You might also like
- CCTV Surveillance: Video Practices and TechnologyFrom EverandCCTV Surveillance: Video Practices and TechnologyRating: 5 out of 5 stars5/5 (2)
- Thermodynamics QuestionsDocument4 pagesThermodynamics QuestionsPiyush BaidNo ratings yet
- PLC CurriculumDocument4 pagesPLC CurriculummanisegarNo ratings yet
- 12186Document2 pages12186Harsh BhatiaNo ratings yet
- GSM Controlled Automatic Irrigation System Using 8051 Microcontroller OriginalDocument13 pagesGSM Controlled Automatic Irrigation System Using 8051 Microcontroller Originalamism24No ratings yet
- 21314Document5 pages21314HirkanipatilNo ratings yet
- Discrete Time SignalDocument11 pagesDiscrete Time Signaldheerajdb99No ratings yet
- Seminar: 8255A PPIDocument15 pagesSeminar: 8255A PPIyuvraj singhNo ratings yet
- Solution Practice 08.24Document14 pagesSolution Practice 08.24Abdu AbdoulayeNo ratings yet
- Block DiagramDocument75 pagesBlock DiagramJane Erestain BuenaobraNo ratings yet
- IC 8155 InformationDocument13 pagesIC 8155 InformationKajol PhadtareNo ratings yet
- Flow ComputerDocument29 pagesFlow ComputerCahyo PrasetyoNo ratings yet
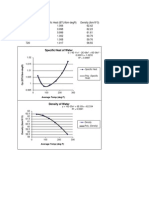
- Btu CalculationsDocument1 pageBtu CalculationsVíctor RojasNo ratings yet
- Iscan2 ScannerDocument2 pagesIscan2 ScannerjqithriNo ratings yet
- 8255 - SeminarDocument28 pages8255 - SeminarJKNo ratings yet
- Type Ezr EstancoDocument40 pagesType Ezr EstancoJuan JuanNo ratings yet
- EZR Installation ManualDocument40 pagesEZR Installation ManualRoberto Aldayuz HerediaNo ratings yet
- Solenoid Operated Valves: Nuclear Power GenerationDocument12 pagesSolenoid Operated Valves: Nuclear Power GenerationVeerabhadra BujurkeNo ratings yet
- Signature Recognition Using Image Processing ArtificialDocument104 pagesSignature Recognition Using Image Processing ArtificialNiko Karis GunawanNo ratings yet
- Vortex Pilot Gas Heater Over Temperature ProtectionDocument17 pagesVortex Pilot Gas Heater Over Temperature ProtectionDon BettonNo ratings yet
- PLC CourseDocument3 pagesPLC CourseNisar AhmedNo ratings yet
- Intro Process Xmitters (Suresh)Document33 pagesIntro Process Xmitters (Suresh)sreeyukthaNo ratings yet
- (Job Title #1) / (Job Title #2) : (NAME)Document3 pages(Job Title #1) / (Job Title #2) : (NAME)Rashid Mahmood JaatNo ratings yet
- 3/2 Directional ValveDocument9 pages3/2 Directional ValveMohan ArumugavallalNo ratings yet
- Chemical Composition of Carrot Seeds Daucus Carota PDFDocument8 pagesChemical Composition of Carrot Seeds Daucus Carota PDFMaurizio ArdizziNo ratings yet
- Why 4-20 Ma Signal Is Used in Industrial Instrumentation?: Google ChromeDocument2 pagesWhy 4-20 Ma Signal Is Used in Industrial Instrumentation?: Google Chromemunro_85No ratings yet
- LAN and WAN ConnectivityDocument11 pagesLAN and WAN Connectivitydebabratalogon50% (2)
- GS02 33 35Document2 pagesGS02 33 35Adal VeraNo ratings yet
- GgsDocument21 pagesGgsKrishna KumarNo ratings yet
- SG Actuator Gas Over OilDocument4 pagesSG Actuator Gas Over Oiltoader56No ratings yet
- Manual Regulators Man Slamshut 2-4inchDocument20 pagesManual Regulators Man Slamshut 2-4inchDelfin Rosanieto TapiaNo ratings yet
- LP Gas Regulators Equipment Application Guide Technical Section en 126594 PDFDocument152 pagesLP Gas Regulators Equipment Application Guide Technical Section en 126594 PDFIsaac FloresNo ratings yet
- Natural Gas Chromatograph (NGC) 8206: Data Sheet 2101164-AGDocument5 pagesNatural Gas Chromatograph (NGC) 8206: Data Sheet 2101164-AGishibhoomiNo ratings yet
- 67Document10 pages67johnnylim456No ratings yet
- Modular UARTDocument28 pagesModular UARTpreetiNo ratings yet
- Sample Exam2cDocument10 pagesSample Exam2cnaefmubarakNo ratings yet
- 6 Measurement of Ripple Factor of RectifiersDocument5 pages6 Measurement of Ripple Factor of Rectifierskarthiksubramanian940% (1)
- Fluid Mechanics IMP Theory QuestionsDocument4 pagesFluid Mechanics IMP Theory QuestionsShaikh MubashirNo ratings yet
- Advanced Computer ArchitectureDocument214 pagesAdvanced Computer Architecturenaznin18No ratings yet
- FloBoss™ S600+ Flow Computer Instruction Manual PDFDocument152 pagesFloBoss™ S600+ Flow Computer Instruction Manual PDFSibabrata ChoudhuryNo ratings yet
- Natural Gas AssignmentDocument9 pagesNatural Gas AssignmentJagathisswary SatthiNo ratings yet
- DPSD CS8351 U1 PDFDocument182 pagesDPSD CS8351 U1 PDFPragna SidhireddyNo ratings yet
- Society of Petroleum GeophysicistsDocument57 pagesSociety of Petroleum Geophysicistsdinesh_hsenidNo ratings yet
- Variable-Area FlowmeterDocument15 pagesVariable-Area FlowmeterhotnatkapoorNo ratings yet
- Difference Between LAN and WANDocument6 pagesDifference Between LAN and WANSyed JaWad HyderNo ratings yet
- Department of Electrical EngineeringDocument9 pagesDepartment of Electrical EngineeringArslan ArshadNo ratings yet
- Overflow Valves: Type OFV 20-25 Type OFV-SS 20-25Document13 pagesOverflow Valves: Type OFV 20-25 Type OFV-SS 20-25LucioRimacNo ratings yet
- Natural Gas Dynamics - Mod 2Document44 pagesNatural Gas Dynamics - Mod 2sujaysarkar85No ratings yet
- Important Java Question For ICSE Class X Board ExamDocument102 pagesImportant Java Question For ICSE Class X Board ExamDwijesh DonthyNo ratings yet
- Design of AccumulatorDocument5 pagesDesign of AccumulatorMd. AbdullahNo ratings yet
- Importance and Features of HLLDocument4 pagesImportance and Features of HLLMayank VermaNo ratings yet
- Frequently Asked Questions On Natural Gas - Hindustan Petroleum Corporation Limited, IndiaDocument5 pagesFrequently Asked Questions On Natural Gas - Hindustan Petroleum Corporation Limited, IndiaDAYARNAB BAIDYANo ratings yet
- Course Handout - Operating Systems Design - S-19cs2106sDocument24 pagesCourse Handout - Operating Systems Design - S-19cs2106sAshish ReddyNo ratings yet
- OGDCL-Past Papers 2021Document4 pagesOGDCL-Past Papers 2021Haseeb AhmadNo ratings yet
- Books Groundwater in General:: Course Hydraulic Modelling Granada 2006 by C. KohfahlDocument36 pagesBooks Groundwater in General:: Course Hydraulic Modelling Granada 2006 by C. KohfahlToygar Akar100% (1)
- 4 Instruction PipelineDocument13 pages4 Instruction PipelineAKASH PALNo ratings yet
- CSC15107: Computer Architecture: Lecture - 13, 14: Pipelined Processor 01, 03 September 2020Document32 pagesCSC15107: Computer Architecture: Lecture - 13, 14: Pipelined Processor 01, 03 September 202018je0140 anshbafnaNo ratings yet
- Pipelining Pipelining Characteristics of Pipelining Clocks and Latches 5 Stages of Pipelining Hazards Loads / Stores Risc and CiscDocument12 pagesPipelining Pipelining Characteristics of Pipelining Clocks and Latches 5 Stages of Pipelining Hazards Loads / Stores Risc and CiscKelvinNo ratings yet
- Pipeline HazardsDocument43 pagesPipeline HazardsDare DevilNo ratings yet
- 13054119-176 - Pipelining - Aqsa SaleemDocument21 pages13054119-176 - Pipelining - Aqsa SaleemMasoomBachiiNo ratings yet
- Company Name Here: Proposal TitleDocument6 pagesCompany Name Here: Proposal Titlejamal009No ratings yet
- Lahore Chemicals CompaniesDocument3 pagesLahore Chemicals Companiesjamal009No ratings yet
- WTM V10 - eDocument2 pagesWTM V10 - ejamal009No ratings yet
- Job Application Form: The Urban UnitDocument2 pagesJob Application Form: The Urban Unitjamal009No ratings yet
- Final-M SC Advertisement 2012Document1 pageFinal-M SC Advertisement 2012jamal009No ratings yet
- Assignment 1Document1 pageAssignment 1jamal009No ratings yet
- EE 3323 Section 8.2 NoiseDocument54 pagesEE 3323 Section 8.2 Noisejamal009No ratings yet
- EE 520-Computer Architecture-Adeel Pasha PDFDocument3 pagesEE 520-Computer Architecture-Adeel Pasha PDFTALHA SALEEMNo ratings yet
- Unit - 6 Pipeline & Vector Processing: 2140707 Computer OrganizationDocument36 pagesUnit - 6 Pipeline & Vector Processing: 2140707 Computer OrganizationHemanth VNo ratings yet
- Design of 3 Stage Pipelining Processor Using VHDLDocument22 pagesDesign of 3 Stage Pipelining Processor Using VHDLsdmdharwadNo ratings yet
- HWMonitorDocument50 pagesHWMonitorAnca LoredanaNo ratings yet
- ProblemDocument19 pagesProblemRakib SheikhNo ratings yet
- 02 Ch5 Basic Computer Organization and DesignDocument30 pages02 Ch5 Basic Computer Organization and DesignBigo LiveNo ratings yet
- Superscalar Processors QuestionsDocument12 pagesSuperscalar Processors QuestionsSUPRIYA MANDALNo ratings yet
- Comp Architecture Sample QuestionsDocument9 pagesComp Architecture Sample QuestionsMohamaad SihatthNo ratings yet
- Instruction TablesDocument469 pagesInstruction Tablesreklamyspam02No ratings yet
- William Stallings Computer Organization and Architecture 8 Edition Processor Structure and FunctionDocument74 pagesWilliam Stallings Computer Organization and Architecture 8 Edition Processor Structure and FunctionRehman HazratNo ratings yet
- 8086 Lab ExercisesDocument39 pages8086 Lab ExercisesAreej Al MajedNo ratings yet
- x86 Instruction OPCODEDocument57 pagesx86 Instruction OPCODEAlex ZXNo ratings yet
- Sections 3.2 and 3.3 Dynamic Scheduling - Tomasulo's AlgorithmDocument53 pagesSections 3.2 and 3.3 Dynamic Scheduling - Tomasulo's AlgorithmvpsampathNo ratings yet
- Addressing Modes of 8085Document10 pagesAddressing Modes of 8085etfs4indiaNo ratings yet
- 3DNow! and MMX Instructions Set PDFDocument44 pages3DNow! and MMX Instructions Set PDFbeniNo ratings yet
- Pipelinehazard For ClassDocument61 pagesPipelinehazard For ClassJayanta SikdarNo ratings yet
- L24 PipelineDocument40 pagesL24 PipelineES SENo ratings yet
- CS433 hw1 Fall 07Document3 pagesCS433 hw1 Fall 0798140207No ratings yet
- Chapter 15 - Exercises - Reduced Instruction Set ComputersDocument6 pagesChapter 15 - Exercises - Reduced Instruction Set ComputersNguyen Quang ChienNo ratings yet
- 8088/8086 MICROPROCESSOR Programming - Control Flow Instructions and Program StructuresDocument10 pages8088/8086 MICROPROCESSOR Programming - Control Flow Instructions and Program Structuressai420No ratings yet
- CS104: Computer Organization: 2 April, 2020Document33 pagesCS104: Computer Organization: 2 April, 2020Om PrakashNo ratings yet
- Appendix B2 P374493Document10 pagesAppendix B2 P374493jakkNo ratings yet
- Lec11 Pipeline 1 NotesDocument26 pagesLec11 Pipeline 1 Noteschancharlie30624700No ratings yet
- Part 2Document39 pagesPart 2Aschalew AyeleNo ratings yet
- Branching InstructionsDocument5 pagesBranching InstructionsDeepti ChandrasekharanNo ratings yet
- Chapter 6 Instruction Set of 8085 & ProgrammingDocument103 pagesChapter 6 Instruction Set of 8085 & Programmingshubhankar pal100% (1)
- EE-457 SpringDocument11 pagesEE-457 SpringTecho SunnyNo ratings yet
- Microprocessor Module-5 Question AnswersDocument8 pagesMicroprocessor Module-5 Question AnswersShubham BargeNo ratings yet
- Chapter 3.3 - Computer Architecture and Fetch-Execute Cycle (Cambridge AL 9691)Document7 pagesChapter 3.3 - Computer Architecture and Fetch-Execute Cycle (Cambridge AL 9691)lyceum_fans100% (1)
- 5 - RISCV - SingleCycle - Arch1Document44 pages5 - RISCV - SingleCycle - Arch1Hassan AliNo ratings yet