Professional Documents
Culture Documents
Achieving Secure, Scalable and Fine-Grained Data Access Control in Cloud Computing
Uploaded by
pssumi2Original Description:
Original Title
Copyright
Available Formats
Share this document
Did you find this document useful?
Is this content inappropriate?
Report this DocumentCopyright:
Available Formats
Achieving Secure, Scalable and Fine-Grained Data Access Control in Cloud Computing
Uploaded by
pssumi2Copyright:
Available Formats
Achieving Secure, Scalable and Fine-grained Data Access Control in Cloud Computing
1. INTRODUCTION
Cloud computing is a promising computing paradigm which recently has drawn
extensive attention from both academia and industry. By combining a set of existing and
new techniques from research areas such as Service-Oriented Architectures (SOA) and
virtualization, cloud computing is regarded as such a computing paradigm in which
resources in the computing infrastructure are provided as services over the Internet.
Along with this new paradigm, various business models are developed, which can be
[1]
described by terminology of “X as a service (XaaS)” where X could be software,
[2]
hardware, data storage, and etc. Successful examples are Amazon’s EC2 and S3 ,
[3] [4]
Google App Engine , and Microsoft Azure which provide users with scalable
resources in the pay-as-you use fashion at relatively low prices. For example, Amazon’s
S3 data storage service just charges $0.12 to $0.15 per gigabytemonth. As compared to
building their own infrastructures, users are able to save their investments significantly
by migrating businesses into the cloud. With the increasing development of cloud
computing technologies, it is not hard to imagine that in the near future more and more
businesses will be moved into the cloud.
Cloud computing is also facing many challenges that, if not well resolved, may
impede its fast growth. Data security, as it exists in many other applications, is among
these challenges that would raise great concerns from users when they store sensitive
information on cloud servers. These concerns originate from the fact that cloud servers
are usually operated by commercial providers which are very likely to be outside of the
trusted domain of the users. Data confidential against cloud servers is hence frequently
desired when users outsource data for storage in the cloud. In some practical application
systems, data confidentiality is not only a security/privacy issue, but also of juristic
concerns. For example, in healthcare application scenarios use and disclosure of
protected health information (PHI) should meet the requirements of Health Insurance
Portability and Accountability Act (HIPAA) [5], and keeping user data confidential against
the storage servers is not just an option, but a requirement. Furthermore, we observe that
there are also cases in which cloud users themselves are content providers. They publish
data on cloud servers for sharing and need fine-grained data access control in terms of
which user (data consumer) has the access privilege to which types of data. In the
Dept. of CSE, Sri Kalahasteeswara Institute of Technology, Srikalahasti
44
Achieving Secure, Scalable and Fine-grained Data Access Control in Cloud Computing
healthcare case, for example, a medical center would be the data owner who stores
millions of healthcare records in the cloud. It would allow data consumers such as
doctors, patients, researchers and etc, to access various types of healthcare records under
policies admitted by HIPAA. To enforce these access policies, the data owners on one
hand would like to take advantage of the abundant resources that the cloud provides for
efficiency and economy; on the other hand, they may want to keep the data contents
confidential against cloud servers.
We address this open issue and propose a secure and scalable fine-grained data
access control scheme for cloud computing. Our proposed scheme is partially based on
our observation that, in practical application scenarios each data file can be associated
with a set of attributes which are meaningful in the context of interest. The access
structure of each user can thus be defined as a unique logical expression over these
attributes to reflect the scope of data files that the user is allowed to access.
As the logical expression can represent any desired data file set, fine-grainedness
of data access control is achieved. To enforce these access structures, we define a public
key component for each attribute. Data files are encrypted using public key components
corresponding to their attributes. User secret keys are defined to reflect their access
structures so that a user is able to decrypt a cipher text if and only if the data file
attributes satisfy his access structure. Such a design also brings about the efficiency
benefit, as compared to previous works, in that, 1) the complexity of encryption is just
related the number of attributes associated to the data file, and is independent to the
number of users in the system and 2) data file creation/deletion and new user grant
operations just affect current file/user without involving system-wide data file update or
[23]
re-keying . One extremely challenging issue with this design is the implementation of
user revocation, which would inevitably require re-encryption of data files accessible to
the leaving user, and may need update of secret keys for all the remaining users. If all
these tasks are performed by the data owner himself/herself, it would introduce a heavy
computation overhead on him/her and may also require the data owner to be always
online. To resolve this challenging issue, our proposed scheme enables the data owner to
delegate tasks of data file re-encryption and user secret key update to cloud servers
without disclosing data contents or user access privilege information. We achieve our
Dept. of CSE, Sri Kalahasteeswara Institute of Technology, Srikalahasti
44
Achieving Secure, Scalable and Fine-grained Data Access Control in Cloud Computing
design goals by exploiting a novel cryptographic primitive, namely key policy attribute-
based encryption.
1.1 MODELS AND ASSUMPTIONS
1.1.1 System Models
Similar to Enabling Public Verifiability and Data Dynamics for Storage Security
in Cloud Computing [17], we assume that the system is composed of the following parties:
the Data Owner, many Data Consumers, many Cloud Servers, and a Third Party Auditor
if necessary. To access data files shared by the data owner, Data Consumers, or users for
brevity, download data files of their interest from Cloud Servers and then decrypt.
Neither the data owner nor users will be always online. They come online just on the
necessity basis. For simplicity, we assume that the only access privilege for users is data
file reading. Extending our proposed scheme to support data file writing is trivial by
asking the data writer to sign the new data file on each update as [12] does. From now on,
we will also call data files by files for brevity. Cloud Servers are always online and
operated by the Cloud Service Provider (CSP). They are assumed to have abundant
storage capacity and computation power. The Third Party Auditor is also an online party
which is used for auditing every file access event. In addition, we also assume that the
data owner can not only store data files but also run his own code on Cloud Servers to
manage his data files. This assumption coincides with the unified ontology of cloud
computing which is recently proposed by Youseff et al [18].
1.1.2. Security Models
In this work, we just consider Honest but Curious Cloud Servers as Over-
[14]
encryption: Management of access control evolution on outsourced data does. That is
to say, Cloud Servers will follow our proposed protocol in general, but try to find out as
much secret information as possible based on their inputs. More specifically, we assume
Cloud Servers are more interested in file contents and user access privilege information
than other secret information. Cloud Servers might collude with a small number of
malicious users for the purpose of harvesting file contents when it is highly beneficial.
Communication channel between the data owner/users and Cloud Servers are assumed to
be secured under existing security protocols such as SSL. Users would try to access files
either within or outside the scope of their access privileges. To achieve this goal,
Dept. of CSE, Sri Kalahasteeswara Institute of Technology, Srikalahasti
44
Achieving Secure, Scalable and Fine-grained Data Access Control in Cloud Computing
unauthorized users may work independently or cooperatively. In addition, each party is
preloaded with a public/private key pair and the public key can be easily obtained by
other parties when necessary.
1.1.3. Design Goals
Our main design goal is to help the data owner achieve fine-grained access
control on files stored by Cloud Servers. Specifically, we want to enable the data owner
to enforce a unique access structure on each user, which precisely designates the set of
files that the user is allowed to access. We also want to prevent Cloud Servers from being
able to learn both the data file contents and user access privilege information. In addition,
the proposed scheme should be able to achieve security goals like user accountability and
support basic operations such as user grant/revocation as a general one-to-many
communication system would require. All these design goals should be achieved
efficiently in the sense that the system is scalable.
Dept. of CSE, Sri Kalahasteeswara Institute of Technology, Srikalahasti
44
Achieving Secure, Scalable and Fine-grained Data Access Control in Cloud Computing
2. SYSTEM STUDY
2.1. EXISTING SYSTEM
Our existing solution applies cryptographic methods by disclosing data decryption
keys only to authorized users. These solutions inevitably introduce a heavy computation
overhead on the data owner for key distribution and data management when fine grained
data access control is desired, and thus do not scale well.
Disadvantages
• Software update/patches - could change security settings, assigning privileges
too low, or even more alarmingly too high allowing access to your data by other
parties.
• Security concerns - Experts claim that their clouds are 100% secure - but it will
not be their head on the block when things go awry. It's often stated that cloud
computing security is better than most enterprises. Also, how do you decide
which data to handle in the cloud and which to keep to internal systems - once
decided keeping it secure could well be a full-time task?
• Control - Control of your data/system by third-party. Data - once in the cloud
always in the cloud! Can you be sure that once you delete data from your cloud
account will it not exist any more... ...or will traces remain in the cloud?
2.2. PROPOSED SYSTEM
2.2.1. Main Idea
In order to achieve secure, scalable and fine-grained access control on outsourced
data in the cloud, we utilize and uniquely combine the following three advanced
cryptographic techniques:
• Key Policy Attribute-Based Encryption (KP-ABE).
• Proxy Re-Encryption (PRE)
• Lazy re-encryption
Advantages
• Low initial capital investment
Dept. of CSE, Sri Kalahasteeswara Institute of Technology, Srikalahasti
44
Achieving Secure, Scalable and Fine-grained Data Access Control in Cloud Computing
• Shorter start-up time for new services
• Lower maintenance and operation costs
• Higher utilization through virtualization
• Easier disaster recovery
More specifically, we associate each data file with a set of
attributes, and assign each user an expressive access structure which
is defined over these attributes. To enforce this kind of access control,
we utilize KP-ABE to escort data encryption keys of data files. Such a
construction enables us to immediately enjoy fine-grainedness of
access control. However, this construction, if deployed alone, would
introduce heavy computation overhead and cumbersome online
burden towards the data owner, as he is in charge of all the operations
of data/user management. Specifically, such an issue is mainly caused
by the operation of user revocation, which inevitably requires the data
owner to re-encrypt all the data files accessible to the leaving user, or
even needs the data owner to stay online to update secret keys for
users. To resolve this challenging issue and make the construction
suitable for cloud computing, we uniquely combine PRE with KP-ABE
and enable the data owner to delegate most of the computation
intensive operations to Cloud Servers without disclosing the underlying
file contents. Such a construction allows the data owner to control
access of his data files with a minimal overhead in terms of
computation effort and online time, and thus fits well into the cloud
environment. Data confidentiality is also achieved since Cloud Servers
are not able to learn the plaintext of any data file in our construction.
For further reducing the computation overhead on Cloud Servers and
thus saving the data owner’s investment, we take advantage of the
lazy re-encryption technique and allow Cloud Servers to “aggregate”
computation tasks of multiple system operations. As we will discuss in
section V-B, the computation complexity on Cloud Servers is either
proportional to the number of system attributes, or linear to the size of
the user access structure/tree, which is independent to the number of
Dept. of CSE, Sri Kalahasteeswara Institute of Technology, Srikalahasti
44
Achieving Secure, Scalable and Fine-grained Data Access Control in Cloud Computing
users in the system. Scalability is thus achieved. In addition, our
construction also protects user access privilege information against
Cloud Servers. Accountability of user secret key can also be achieved
by using an enhanced scheme of KP-ABE.
2.2.2. Definition and Notation
For each data file the owner assigns a set of meaningful attributes which are
necessary for access control. Different data files can have a subset of attributes in
common. Each attribute is associated with a version number for the purpose of attribute
update as we will discuss later. Cloud Servers keep an attribute history list AHL which
records the version evolution history of each attribute and PRE keys used. In addition to
these meaningful attributes, we also define one dummy attribute, denoted by symbol AttD
for the purpose of key management. AttD is required to be included in every data file’s
attribute set and will never be updated. The access structure of each user is implemented
by an access tree. Interior nodes of the access tree are threshold gates. Leaf nodes of the
access tree are associated with data file attributes. For the purpose of key management,
we require the root node to be an AND gate (i.e., n-of-n threshold gate) with one child
being the leaf node which is associated with the dummy attribute, and the other child
node being any threshold gate. The dummy attribute will not be attached to any other
node in the access tree. Fig.1 illustrates our definitions by an example. In addition, Cloud
Servers also keep a user list UL which records IDs of all the valid users in the system.
Fig.2 gives the description of notation to be used in our scheme.
Dept. of CSE, Sri Kalahasteeswara Institute of Technology, Srikalahasti
44
Achieving Secure, Scalable and Fine-grained Data Access Control in Cloud Computing
Fig.1: Example showing Cloud Computing
Notation Description
PK, MK system public key and master key
Ti public key component for attribute i
ti master key component for attribute i
SK user secret key
ski user secret key component for attribute i
Ei cipher-text component for attribute i
I attribute set assigned to a data file
DEK symmetric data encryption key of a data file
P user access structure
LP set of attributes attached to leaf nodes of P
AttD the dummy attribute
UL the system user list
AHLi attribute history list for attribute i
rki↔i’ proxy re-encryption key for attribute i from its current version to the updated
version i’
δO,X the data owner’s signature on message X
Dept. of CSE, Sri Kalahasteeswara Institute of Technology, Srikalahasti
44
Achieving Secure, Scalable and Fine-grained Data Access Control in Cloud Computing
Fig. 2: Notation used in our scheme description
2.2.3. Scheme Description
For clarity we will present our proposed scheme in two levels: System Level and
Algorithm Level. At system level, we describe the implementation of high level
operations, i.e., System Setup, New File Creation, New User Grant, and User Revocation,
File Access, File Deletion, and the interaction between involved parties. At algorithm
level, we focus on the implementation of low level algorithms that are invoked by system
level operations.
1) System Level Operations: System level operations in our proposed scheme are
designed as follows.
System Setup In this operation, the data owner chooses a security parameter κ
and calls the algorithm level interface ASetup(k), which outputs the system public
parameter PK and the system master key MK. The data owner then signs each component
of PK and sends PK along with these signatures to Cloud Servers.
New File Creation Before uploading a file to Cloud Servers, the data owner
processes the data file as follows.
• select a unique ID for this data file;
• randomly select a symmetric data encryption key DEK R← K, where K is the key space,
and encrypt the data file using DEK;
• define a set of attribute I for the data file and encrypt DEK with I using KP-ABE, i.e.,
(Ẽ, {Ei}i∈I ) ← AEncrypt(I,DEK,PK).
Header Body
ID I, Ẽ, {Ei}i∈I {DataFile}DEK
Fig. 3: Format of a data file stored on the cloud
Finally, each data file is stored on the cloud in the format as is shown in Fig.3.
New User Grant When a new user wants to join the system, the data owner
assigns an access structure and the corresponding secret key to this user as follows.
• assign the new user a unique identity w and an access structure P;
• generate a secret key SK for w, i.e., SK ← AKeyGen(P,MK);
Dept. of CSE, Sri Kalahasteeswara Institute of Technology, Srikalahasti
44
Achieving Secure, Scalable and Fine-grained Data Access Control in Cloud Computing
• encrypt the tuple (P, SK,PK, δO,(P,SK,PK)) with user w’s public key, denoting the cipher-
text by C;
• send the tuple (T,C, δO,(T,C)) to Cloud Servers, where T denotes the tuple (w, {j, skj} jLP
\AttD ). On receiving the tuple (T,C, δO,(T,C)), Cloud Servers processes as follows.
• verify δO,(T,C) and proceed if correct;
• store T in the system user list UL;
• forward C to the user.
On receiving C, the user first decrypts it with his private key. Then he verifies the
signature δO,(P,SK,PK). If correct, he accepts (P, SK,PK) as his access structure, secret key,
and the system public key.
As described above, Cloud Servers store all the secret key components of SK
except for the one corresponding to the dummy attribute AttD. Such a design allows
Cloud Servers to update these secret key components during user revocation as we will
describe soon. As there still exists one undisclosed secret key component (the one for
AttD), Cloud Servers cannot use these known ones to correctly decrypt ciphertexts.
Actually, these disclosed secret key components, if given to any unauthorized user, do
not give him any extra advantage in decryption as we will show in our security analysis.
User Revocation We start with the intuition of the user revocation operation as
follows. Whenever there is a user to be revoked, the data owner first determines a
minimal set of attributes without which the leaving user’s access structure will never be
satisfied. Next, he updates these attributes by redefining their corresponding system
master key components in MK. Public key components of all these updated attributes in
PK are redefined accordingly. Then, he updates user secret keys accordingly for all the
users except for the one to be revoked. Finally, DEKs of affected data files are re-
encrypted with the latest version of PK. The main issue with this intuitive scheme is that
it would introduce a heavy computation overhead for the data owner to re-encrypt data
files and might require the data owner to be always online to provide secret key update
service for users. To resolve this issue, we combine the technique of proxy re-encryption
with KP-ABE and delegate tasks of data file re-encryption and user secret key update to
Cloud Servers. More specifically, we divide the user revocation scheme into two stages
as is shown below.
Dept. of CSE, Sri Kalahasteeswara Institute of Technology, Srikalahasti
44
Achieving Secure, Scalable and Fine-grained Data Access Control in Cloud Computing
// to revoke user v
// stage 1: attribute update.
The Data Owner Cloud Servers
1. D ← AMinimalSet(P), where P is v’s access structure; remove v from the system
user list UL;
2. for each attribute i in D for each attribute i ∈ D
Att
(t’i, T’i , rki↔i’ )← AUpdateAtt(i,MK); → store (i, T_i , δO,(i,T _i ));
3. send Att = (v,D, {i, T’i , δO,(i,T ‘i ), rki↔i’}i ∈ D). add rki↔i’ to i’s history list
AHLi.
// stage 2: data file and user secret key update.
Cloud Servers User (u)
1. on receiving REQ, proceed if u ∈ UL;
2. get the tuple (u, {j, skj}j∈LP \AttD); 1. generate data file access
request REQ;
for each attribute j ∈ LP \AttD ←REQ 2. wait for the response from
Cloud Servers;
sk’j← AUpdateSK(j, skj,AHLj );
for each requested file f in REQ 3. on receiving RESP, verify
for each attribute k ∈ If RESP
→ each δO,(j,T ‘j ) and sk’j; proceed
if
correct;
E’k← AUpdateAtt4File(k,Ek,AHLk); 4. replace each skj in SK with
sk’j;
3. send RESP = ({j, sk’j, T’j, δO,(j,T ‘j )}j∈LP \AttD, FL). 5. decrypt each file in FL
with
SK.
Description of the process of user revocation
In the first stage, the data owner determines the minimal set of attributes,
redefines MK and PK for involved attributes, and generates the corresponding PRE keys.
He then sends the user’s ID, the minimal attribute set, the PRE keys, the updated public
key components, along with his signatures on these components to Cloud Servers, and
Dept. of CSE, Sri Kalahasteeswara Institute of Technology, Srikalahasti
44
Achieving Secure, Scalable and Fine-grained Data Access Control in Cloud Computing
can go off-line again. Cloud Servers, on receiving this message from the data owner,
remove the revoked user from the system user list UL, store the updated public key
components as well as the owner’s signatures on them, and record the PRE key of the
latest version in the attribute history list AHL for each updated attribute. AHL of each
attribute is a list used to record the version evolution history of this attribute as well as
the PRE keys used. Every attribute has its own AHL. With AHL, Cloud Servers are able
to compute a single PRE key that enables them to update the attribute from any historical
version to the latest version. This property allows Cloud Servers to update user secret
keys and data files in the “lazy” way as follows. Once a user revocation event occurs,
Cloud Servers just record information submitted by the data owner as is previously
discussed. If only there is a file data access request from a user, do Cloud Servers re-
encrypt the requested files and update the requesting user’s secret key. This statistically
saves a lot of computation overhead since Cloud Servers are able to “aggregate” multiple
update/re-encryption operations into one if there is no access request occurring across
multiple successive user revocation events.
File Access This is also the second stage of user revocation. In this operation,
Cloud Servers respond user request on data file access, and update user secret keys and
re-encrypt requested data files if necessary. As is depicted in Fig. 4, Cloud Servers first
verify if the requesting user is a valid system user in UL. If true, they update this user’s
secret key components to the latest version and re-encrypt the DEKs of requested data
files using the latest version of PK. Notably; Cloud Servers will not perform update/re-
encryption if secret key components/data files are already of the latest version. Finally,
Cloud Servers send updated secret key components as well as ciphertexts of the requested
data files to the user. On receiving the response from Cloud Servers, the user first verifies
if the claimed version of each attribute is really newer than the current version he knows.
For this purpose, he needs to verify the data owner’s signatures on the attribute
information (including the version information) and the corresponding public key
components, i.e., tuples of the form (j, T’j) in Fig. 4. If correct, the user further verifies if
each secret key component returned by Cloud Servers is correctly computed. He verifies
this by computing a bilinear pairing between sk’j and T’j and comparing the result with
that between the old skj and Tj that he possesses. If verification succeeds, he replaces each
skj of his secret key with sk’j and update Tj with T’j. Finally, he decrypts data files by first
calling ADecrypt(P, SK,E) to decrypt DEK’s and then decrypting data files using DEK’s.
Dept. of CSE, Sri Kalahasteeswara Institute of Technology, Srikalahasti
44
Achieving Secure, Scalable and Fine-grained Data Access Control in Cloud Computing
File Deletion This operation can only be performed at the request of the data
owner. To delete a file, the data owner sends the file’s unique ID along with his signature
on this ID to Cloud Servers. If verification of the owner’s signature returns true, Cloud
Servers delete the data file. 2) Algorithm level operations: Algorithm level operations
include eight algorithms: ASetup, AEncrypt, AKeyGen, ADecrypt, AUpdateAtt,
AUpdateSK, AUpdateAtt4File, and AMinimalSet. As the first four algorithms are just the
same as Setup, Encryption, Key Generation, and Decryption of the standard KP-ABE
respectively, we focus on our implementation of the last four algorithms.
AUpdateAtt This algorithm updates an attribute to a new version by redefining its
system master key and public key component. It also outputs a proxy re-encryption key
between the old version and the new version of the attribute.
AUpdateAtt4File This algorithm translates the ciphertext component of an
attribute i of a file from an old version into the latest version. It first checks the attribute
history list of this attribute and locates the position of the old version. Then it multiplies
all the PRE keys between the old version and the latest version and obtains a single PRE
key. Finally it apply this single PRE key to the ciphertext component Ei and returns E (n)i
which coincides with the latest definition of attribute i.
AUpdateSK This algorithm translates the secret key component of attribute i in
the user secret key SK from an old version into the latest version. Its implementation is
similar to AUpdateAtt4File except that, in the last step it applies (rki↔i(n) )−1 to SKi instead
of rki↔i(n) . This is because ti is the denominator of the exponent part of SKi while in Ei it is
a numerator.
AMinimalSet This algorithm determines a minimal set of attributes without which
an access tree will never be satisfied. For this purpose, it constructs the conjunctive
normal form (CNF) of the access tree, and returns attributes in the shortest clause of the
CNF formula as the minimal attribute set.
2.3. FEASIBILITY STUDY
Dept. of CSE, Sri Kalahasteeswara Institute of Technology, Srikalahasti
44
Achieving Secure, Scalable and Fine-grained Data Access Control in Cloud Computing
The feasibility of the project is analyzed in this phase and business proposal is put
forth with a very general plan for the project and some cost estimates. During system
analysis the feasibility study of the proposed system is to be carried out. This is to ensure
that the proposed system is not a burden to the company. For feasibility analysis, some
understanding of the major requirements for the system is essential. Three key
considerations involved in the feasibility analysis are
♦ ECONOMICAL FEASIBILITY
♦ TECHNICAL FEASIBILITY
♦ SOCIAL FEASIBILITY
2.3.1. Economical Feasibility
This study is carried out to check the economic impact that the system will have
on the organization. The amount of fund that the company can pour into the research and
development of the system is limited. The expenditures must be justified. Thus the
developed system as well within the budget and this was achieved because most of the
technologies used are freely available. Only the customized products had to be purchased.
2.3.2. Technical Feasibility
This study is carried out to check the technical feasibility, that is, the technical
requirements of the system. Any system developed must not have a high demand on the
available technical resources. This will lead to high demands on the available technical
resources. This will lead to high demands being placed on the client. The developed
system must have a modest requirement, as only minimal or null changes are required for
implementing this system.
2.3.3. Social Feasibility
The aspect of study is to check the level of acceptance of the system by the user.
This includes the process of training the user to use the system efficiently. The user must
not feel threatened by the system, instead must accept it as a necessity. The level of
acceptance by the users solely depends on the methods that are employed to educate the
user about the system and to make him familiar with it. His level of confidence must be
raised so that he is also able to make some constructive criticism, which is welcomed, as
he is the final user of the system.
Dept. of CSE, Sri Kalahasteeswara Institute of Technology, Srikalahasti
44
Achieving Secure, Scalable and Fine-grained Data Access Control in Cloud Computing
3. SYSTEM SPECIFICATIONS
3.1. Hardware Requirements:
• Processor : Pentium IV 2.4 GHz
• Ram : 512 Mb
• Hard Disk : 40 GB
3.2. Software Requirements:
• Operating system : Windows XP
• Coding Language : DOT NET
• Tools Used : Visual Studio2008
• Data Base : SQL Server 2005
Dept. of CSE, Sri Kalahasteeswara Institute of Technology, Srikalahasti
44
Achieving Secure, Scalable and Fine-grained Data Access Control in Cloud Computing
4. SOFTWARE ENVIRONMENT
4.1. FEATURES OF .NET
Microsoft’s .NET is a set of Microsoft software technologies for rapidly building
and integrating XML Web services, Microsoft Windows-based applications, and Web
solutions. The .NET Framework is a language-neutral platform for writing programs that
can easily and securely interoperate. There’s no language barrier with .NET: there are
numerous languages available to the developer including Managed C++, C#, Visual
Basic and Java Script. The .NET framework provides the foundation for components to
interact seamlessly, whether locally or remotely on different platforms. It standardizes
common data types and communications protocols so that components created in
different languages can easily interoperate.
“.NET” is also the collective name given to various software components built
upon the .NET platform. These will be both products (Visual Studio.NET and
Windows.NET Server, for instance) and services (like Passport, .NET My Services, and
so on).
Dept. of CSE, Sri Kalahasteeswara Institute of Technology, Srikalahasti
44
Achieving Secure, Scalable and Fine-grained Data Access Control in Cloud Computing
The .Net Framework
The .NET Framework has two main parts:
1. The Common Language Runtime (CLR).
2. A hierarchical set of class libraries.
The CLR is described as the “execution engine” of .NET. It provides the
environment within which programs run. The most important features are
♦ Conversion from a low-level assembler-style language, called
Intermediate Language (IL), into code native to the platform being
executed on.
♦ Memory management, notably including garbage collection.
♦ Checking and enforcing security restrictions on the running code.
♦ Loading and executing programs, with version control and other such
features.
The following features of the .NET framework are also worth description:
Managed Code
The code that targets .NET, and which contains certain extra information called
“metadata” - to describe itself. Whilst both managed and unmanaged code can run in the
runtime, only managed code contains the information that allows the CLR to guarantee,
for instance, safe execution and interoperability.
Managed Data
With Managed Code comes Managed Data. CLR provides memory allocation and
Deal location facilities, and garbage collection. Some .NET languages use Managed Data
by default, such as C#, Visual Basic.NET and JScript.NET, whereas others, namely C++,
do not. Targeting CLR can, depending on the language you’re using, impose certain
constraints on the features available. As with managed and unmanaged code, one can
have both managed and unmanaged data in .NET applications - data that doesn’t get
garbage collected but instead is looked after by unmanaged code.
Dept. of CSE, Sri Kalahasteeswara Institute of Technology, Srikalahasti
44
Achieving Secure, Scalable and Fine-grained Data Access Control in Cloud Computing
Common Type System
The CLR uses something called the Common Type System (CTS) to strictly
enforce type-safety. This ensures that all classes are compatible with each other, by
describing types in a common way. CTS define how types work within the runtime,
which enables types in one language to interoperate with types in another language,
including cross-language exception handling. As well as ensuring that types are only used
in appropriate ways, the runtime also ensures that code doesn’t attempt to access memory
that hasn’t been allocated to it.
Common Language Specification
The CLR provides built-in support for language interoperability. To ensure that
you can develop managed code that can be fully used by developers using any
programming language, a set of language features and rules for using them called the
Common Language Specification (CLS) has been defined. Components that follow these
rules and expose only CLS features are considered CLS-compliant.
4.2. THE CLASS LIBRARY
.NET provides a single-rooted hierarchy of classes, containing over 7000 types.
The root of the namespace is called System; this contains basic types like Byte, Double,
Boolean, and String, as well as Object. All objects derive from System. Object. As well
as objects, there are value types. Value types can be allocated on the stack, which can
provide useful flexibility. There are also efficient means of converting value types to
object types if and when necessary.
The set of classes is pretty comprehensive, providing collections, file, screen, and
network I/O, threading, and so on, as well as XML and database connectivity.
The class library is subdivided into a number of sets (or namespaces), each
providing distinct areas of functionality, with dependencies between the namespaces kept
to a minimum.
Languages Supported By .Net
Dept. of CSE, Sri Kalahasteeswara Institute of Technology, Srikalahasti
44
Achieving Secure, Scalable and Fine-grained Data Access Control in Cloud Computing
The multi-language capability of the .NET Framework and Visual Studio .NET
enables developers to use their existing programming skills to build all types of
applications and XML Web services. The .NET framework supports new versions of
Microsoft’s old favorites Visual Basic and C++ (as VB.NET and Managed C++), but
there are also a number of new additions to the family.
Visual Basic .NET has been updated to include many new and improved language
features that make it a powerful object-oriented programming language. These features
include inheritance, interfaces, and overloading, among others. Visual Basic also now
supports structured exception handling, custom attributes and also supports multi-
threading.
Visual Basic .NET is also CLS compliant, which means that any CLS-compliant
language can use the classes, objects, and components you create in Visual Basic .NET.
Managed Extensions for C++ and attributed programming are just some of the
enhancements made to the C++ language. Managed Extensions simplify the task of
migrating existing C++ applications to the new .NET Framework.
C# is Microsoft’s new language. It’s a C-style language that is essentially “C++
for Rapid Application Development”. Unlike other languages, its specification is just the
grammar of the language. It has no standard library of its own, and instead has been
designed with the intention of using the .NET libraries as its own.
Microsoft Visual J# .NET provides the easiest transition for Java-language
developers into the world of XML Web Services and dramatically improves the
interoperability of Java-language programs with existing software written in a variety of
other programming languages.
Active State has created Visual Perl and Visual Python, which enable .NET-aware
applications to be built in either Perl or Python. Both products can be integrated into the
Visual Studio .NET environment. Visual Perl includes support for Active State’s Perl
Dev Kit.
Other languages for which .NET compilers are available include
Dept. of CSE, Sri Kalahasteeswara Institute of Technology, Srikalahasti
44
Achieving Secure, Scalable and Fine-grained Data Access Control in Cloud Computing
• FORTRAN
• COBOL
• Eiffel
ASP.NET Windows Forms
XML WEB SERVICES
Base Class Libraries
Common Language Runtime
Operating System
Fig4: Net Framework
C#.NET is also compliant with CLS (Common Language Specification) and
supports structured exception handling. CLS is set of rules and constructs that are
supported by the CLR (Common Language Runtime). CLR is the runtime environment
provided by the .NET Framework; it manages the execution of the code and also makes
the development process easier by providing services.
C#.NET is a CLS-compliant language. Any objects, classes, or components that
created in C#.NET can be used in any other CLS-compliant language. In addition, we can
use objects, classes, and components created in other CLS-compliant languages in
C#.NET .The use of CLS ensures complete interoperability among applications,
regardless of the languages used to create the application.
Constructors and Destructors
Constructors are used to initialize objects, whereas destructors are used to destroy
them. In other words, destructors are used to release the resources allocated to the object.
In C#.NET the sub finalize procedure is available. The sub finalize procedure is used to
complete the tasks that must be performed when an object is destroyed. The sub finalize
procedure is called automatically when an object is destroyed. In addition, the sub
finalize procedure can be called only from the class it belongs to or from derived classes.
Garbage Collection
Dept. of CSE, Sri Kalahasteeswara Institute of Technology, Srikalahasti
44
Achieving Secure, Scalable and Fine-grained Data Access Control in Cloud Computing
Garbage Collection is another new feature in C#.NET. The .NET Framework
monitors allocated resources, such as objects and variables. In addition, the .NET
Framework automatically releases memory for reuse by destroying objects that are no
longer in use.
In C#.NET, the garbage collector checks for the objects that are not currently in
use by applications. When the garbage collector comes across an object that is marked for
garbage collection, it releases the memory occupied by the object.
Overloading
Overloading is another feature in C#. Overloading enables us to define multiple
procedures with the same name, where each procedure has a different set of arguments.
Besides using overloading for procedures, we can use it for constructors and properties in
a class.
Multithreading
C#.NET also supports multithreading. An application that supports multithreading
can handle multiple tasks simultaneously, we can use multithreading to decrease the time
taken by an application to respond to user interaction.
Structured Exception Handling
C#.NET supports structured handling, which enables us to detect and remove
errors at runtime. In C#.NET, we need to use Try…Catch…Finally statements to create
exception handlers. Using Try…Catch…Finally statements, we can create robust and
effective exception handlers to improve the performance of our application.
The .Net Framework
The .NET Framework is a new computing platform that simplifies application
development in the highly distributed environment of the Internet.
Dept. of CSE, Sri Kalahasteeswara Institute of Technology, Srikalahasti
44
Achieving Secure, Scalable and Fine-grained Data Access Control in Cloud Computing
Objectives of .Net Framework
1. To provide a consistent object-oriented programming environment whether object
codes is stored and executed locally on Internet-distributed, or executed remotely.
2. To provide a code-execution environment to minimizes software deployment and
guarantees safe execution of code.
3. Eliminates the performance problems.
There are different types of application, such as Windows-based applications and
Web-based applications.
4.3. FEATURES OF SQL-SERVER
The OLAP Services feature available in SQL Server version 7.0 is now called
SQL Server 2000 Analysis Services. The term OLAP Services has been replaced with the
term Analysis Services. Analysis Services also includes a new data mining component.
The Repository component available in SQL Server version 7.0 is now called Microsoft
SQL Server 2000 Meta Data Services. References to the component now use the term
Meta Data Services. The term repository is used only in reference to the repository
engine within Meta Data Services. SQL-SERVER database consist of objects specified
below.
1. TABLE
2. QUERY
3. FORM
4. REPORT
5. MACRO
TABLE
A database is a collection of data about a specific topic.
VIEWS OF TABLE
We can work with a table in two types,
Dept. of CSE, Sri Kalahasteeswara Institute of Technology, Srikalahasti
44
Achieving Secure, Scalable and Fine-grained Data Access Control in Cloud Computing
1. Design View
2. Datasheet View
Design View
To build or modify the structure of a table we work in the table design view. We
can specify what kind of data will be hold.
Datasheet View
To add, edit or analyses the data itself we work in tables datasheet view mode.
QUERY:
A query is a question that has to be asked the data. Access gathers data that
answers the question from one or more table. The data that make up the answer is either
dynaset (if you edit it) or a snapshot (it cannot be edited).Each time we run query, we get
latest information in the dynaset. Access either displays the dynaset or snapshot for us to
view or perform an action on it, such as deleting or updating.
5. SYSTEM DESIGN
5.1. INPUT DESIGN
The input design is the link between the information system and the user. It
comprises the developing specification and procedures for data preparation and those
steps are necessary to put transaction data in to a usable form for processing can be
achieved by inspecting the computer to read data from a written or printed document or it
can occur by having people keying the data directly into the system. The design of input
focuses on controlling the amount of input required, controlling the errors, avoiding
delay, avoiding extra steps and keeping the process simple. The input is designed in such
a way so that it provides security and ease of use with retaining the privacy. Input Design
considered the following things:
What data should be given as input?
How the data should be arranged or coded?
The dialog to guide the operating personnel in providing input.
Dept. of CSE, Sri Kalahasteeswara Institute of Technology, Srikalahasti
44
Achieving Secure, Scalable and Fine-grained Data Access Control in Cloud Computing
Methods for preparing input validations and steps to follow when error occur.
Objectives
1. Input Design is the process of converting a user-oriented description of the input into a
computer-based system. This design is important to avoid errors in the data input process
and show the correct direction to the management for getting correct information from
the computerized system.
2. It is achieved by creating user-friendly screens for the data entry to handle large
volume of data. The goal of designing input is to make data entry easier and to be free
from errors. The data entry screen is designed in such a way that all the data manipulates
can be performed. It also provides record viewing facilities.
3. When the data is entered it will check for its validity. Data can be entered with the help
of screens. Appropriate messages are provided as when needed so that the user will not
be in maize of instant. Thus the objective of input design is to create an input layout that
is easy to follow.
5.2. OUTPUT DESIGN
A quality output is one, which meets the requirements of the end user and
presents the information clearly. In any system results of processing are communicated to
the users and to other system through outputs. In output design it is determined how the
information is to be displaced for immediate need and also the hard copy output. It is the
most important and direct source information to the user. Efficient and intelligent output
design improves the system’s relationship to help user decision-making.
1. Designing computer output should proceed in an organized, well thought out manner;
the right output must be developed while ensuring that each output element is designed so
that people will find the system can use easily and effectively. When analysis design
computer output, they should Identify the specific output that is needed to meet the
requirements.
2. Select methods for presenting information.
Dept. of CSE, Sri Kalahasteeswara Institute of Technology, Srikalahasti
44
Achieving Secure, Scalable and Fine-grained Data Access Control in Cloud Computing
3. Create document, report, or other formats that contain information produced by the
system.
The output form of an information system should accomplish one or more of the
following objectives.
Convey information about past activities, current status or projections of the
Future.
Signal important events, opportunities, problems, or warnings.
Trigger an action.
Confirm an action.
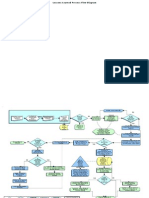
Data flow diagram:
Dept. of CSE, Sri Kalahasteeswara Institute of Technology, Srikalahasti
44
Achieving Secure, Scalable and Fine-grained Data Access Control in Cloud Computing
Login
Owner User
Check
no
Open file Exists
yes
Create account
Upload files to cloud server
Enter data to search
Maintainance of files and users
Encrypt and decrypt the data
End
Send to cloud server
yes no
If files exists for data
List out the files Displays no datas in server
End
Open the required file
Wrong
Enter secret key Check Displays duplicate data
Correct
Displays original file
Use case diagram:
Dept. of CSE, Sri Kalahasteeswara Institute of Technology, Srikalahasti
44
Achieving Secure, Scalable and Fine-grained Data Access Control in Cloud Computing
Create account
Login
Upload files
User
Data owner
Search files
Generate secret key
Cloud server
Maintain secret keys
Secure files
Displays required datas
Class diagram:
Dept. of CSE, Sri Kalahasteeswara Institute of Technology, Srikalahasti
44
Achieving Secure, Scalable and Fine-grained Data Access Control in Cloud Computing
Upload files User account
Fileid Name
Filename Username
uploadeddate Password
downloadeddate Dateofbirth
Address
sendtocloud() Contact number
viewfiledetails() Emailid
createaccount()
generatekeys()
Search files
Fileid
Filename
Secure
Userdata
Userdata
downloadfiles() Userid
showduplicates() Encrypteddata
Decrypteddata
publickey
privatekey
encryption()
decryption()
Sequence diagram:
Dept. of CSE, Sri Kalahasteeswara Institute of Technology, Srikalahasti
44
Achieving Secure, Scalable and Fine-grained Data Access Control in Cloud Computing
Cloud server
User Data owner
Upload files
Create account
Maintain file details
Generate Keys
Search files
Ask secret key
S end secret key
S end required files
Send duplicate datas
If secret key does not matches If secret key matches
Activity diagram:
Dept. of CSE, Sri Kalahasteeswara Institute of Technology, Srikalahasti
44
Achieving Secure, Scalable and Fine-grained Data Access Control in Cloud Computing
Login
Check
User
O wner
No
Upload files Exists Create account
Yes
Send data to
Maintain files and user details
cloud server
Enter secret key
Check
Download Receive duplicate
original data
files
6. MODULE DESCRIPTION
Dept. of CSE, Sri Kalahasteeswara Institute of Technology, Srikalahasti
44
Achieving Secure, Scalable and Fine-grained Data Access Control in Cloud Computing
6.1. KEY POLICY ATTRIBUTE-BASED ENCRYPTION (KP-ABE):
[15]
KP-ABE is a public key cryptography primitive for one-to-many
communications. In KP-ABE, data are associated with attributes for each of which a
public key component is defined. The encryptor associates the set of attributes to the
message by encrypting it with the corresponding public key components. Each user is
assigned an access structure which is usually defined as an access tree over data
attributes, i.e., interior nodes of the access tree are threshold gates and leaf nodes are
associated with attributes. User secret key is defined to reflect the access structure so that
the user is able to decrypt a cipher text if and only if the data attributes satisfy his access
structure [23]. A KP-ABE scheme is composed of four algorithms which can be defined as
follows:
• Setup Attributes
• Encryption
• Secret key generation
• Decryption
Setup Attributes:
This algorithm is used to set attributes for users. This is a randomized algorithm
that takes no input other than the implicit security parameter. It defines a bilinear group
G1 of prime order p with a generator g, a bilinear map e : G1 × G1 → G2 which has the
properties of bilinearity, computability, and non-degeneracy. From these attributes public
key and master key for each user can be determined. The attributes, public key and
master key are denoted as
Attributes- U = {1, 2. . . N}
Public key- PK = (Y, T1, T2, . . . , TN)
Master key- MK = (y, t1, t2, . . . , tN)
where Ti ∈ G1 and ti ∈ Zp are for attribute i, 1 ≤ i ≤ N, and Y ∈ G2 is another public key
component. We have Ti = gti and Y = e (g, g) y, y∈ Zp. While PK is publicly known to all
the parties in the system, MK is kept as a secret by the authority party.
Encryption:
Dept. of CSE, Sri Kalahasteeswara Institute of Technology, Srikalahasti
44
Achieving Secure, Scalable and Fine-grained Data Access Control in Cloud Computing
This is a randomized algorithm that takes a message M, the public key PK, and a
set of attributes I as input. It outputs the cipher text E with the following format:
E = (I, Ẽ, {Ei ∈ I )
where Ẽ= MYs, Ei = Tis. and s is randomly chosen from Zp
Secret key generation:
This is a randomized algorithm that takes as input an access tree T, the master key
MK, and the public key K. It outputs a user secret key SK as follows. First, it defines a
random polynomial pi(x) for each node i of T in the top-down manner starting from the
root node r. For each non-root node j, pj(0) = pparent(j)(idx(j)) where parent(j) represents j’s
parent and idx(j) is j’s unique index given by its parent. For the root node r, pr(0) = y.
Then it outputs SK as follows.
SK = {ski} i ∈ L
where L denotes the set of attributes attached to the leaf nodes of T and ski = gpi(0)/ti .
Decryption:
This algorithm takes as input the cipher text E encrypted under the attribute set I,
the user’s secret key SK for access tree T, and the public key PK. It first computes e(Ei,
ski) = e(g, g)pi(0)s for leaf nodes. Then, it aggregates these pairing results in the bottom-up
manner using the polynomial interpolation technique. Finally, it may recover the blind
factor Ys=e(g,g)ys and output the message M if and only if I satisfies T.
Access tree T:
Let T be a tree representing an access structure. Each non-leaf node of the tree
represents a threshold gate, described by its children and a threshold value. If numx
is the number of children of a node x and kx is its threshold value, then 0 < kx ≤ numx.
When kx = 1, the threshold gate is an OR gate and when kx = numx, it is an AND gate.
Each leaf node x of the tree is described by an attribute and a threshold value kx = 1.
To facilitate working with the access trees, we define a few functions. We denote
the parent of the node x in the tree by parent(x). The function att(x) is defined only if x is
a leaf node and denotes the attribute associated with the leaf node x in the tree. The
access tree T also defines an ordering between the children of every node, that is, the
children of a node are numbered from 1 to num. The function index(x) returns such a
Dept. of CSE, Sri Kalahasteeswara Institute of Technology, Srikalahasti
44
Achieving Secure, Scalable and Fine-grained Data Access Control in Cloud Computing
number associated with the node x, where the index values are uniquely assigned to
nodes in the access structure for a given key in an arbitrary manner.
Satisfying an access tree:
Let T be an access tree with root r. Denote by Tx the sub tree of T rooted at the
node x. Hence T is the same as Tr. If a set of attributes I satisfies the access tree Tx, we
denote it as Tx(I) = 1. We compute Tx(I) recursively as follows. If x is a non-leaf node,
evaluate Tx’(I) for all children x’ of node x. Tx(I) returns 1 if and only if at least kx children
return 1. If x is a leaf node, then Tx(I) returns 1 if and only if att(x) ∈ I.
Construction of Access Trees:
In the access-tree construction, cipher texts are labeled with a set of descriptive
attributes. Private keys are identified by a tree-access structure in which each interior
node of the tree is a threshold gate and the leaves are associated with attributes. A user
will be able to decrypt a cipher text with a given key if and only if there is an assignment
of attributes from the cipher texts to nodes of the tree such that the tree is satisfied.
Efficiency:
We now consider the efficiency of the scheme in terms of cipher text size, private
key size, and computation time for decryption and encryption. The cipher text overhead
will be approximately one group element in G1 for every element in I. That is the number
of group elements will be equal to the number of descriptive attributes in the cipher text.
Similarly, the encryption algorithm will need to perform one exponentiation for each
attribute in I.
The public parameters in the system will be of size linear in the number of
attributes defined in the system. User's private keys will consist of a group element for
every leaf in the key's corresponding access tree. The decryption procedure is by far the
hardest to define performance for. In our rudimentary decryption algorithm the number of
pairings to decrypt might always be as large as the number of nodes in the tree. However,
this method is extremely suboptimal and we now discuss methods to improve upon it.
One important idea is for the decryption algorithm to do some type of exploration
of the access tree relative to the cipher text attributes before it makes cryptographic
Dept. of CSE, Sri Kalahasteeswara Institute of Technology, Srikalahasti
44
Achieving Secure, Scalable and Fine-grained Data Access Control in Cloud Computing
computations. At the very least the algorithm should first discover which nodes are not
satisfied and not bother performing cryptographic operations on them.
The following observation shows how to modify our decryption method to
optimize the efficiency. First we find out which leaf nodes we should use in order to
minimize the number of pairing computations as follows. For each node x, define a set Sx.
If x is a leaf node, then Sx = {x}. Otherwise, let k be the threshold value of x. From among
the child nodes of x, choose k nodes x1, x2,…, xk such that Sxi (for i = 1, 2,…, k) are first k
sets of the smallest size. Then for non-leaf node x, Sx = {x’: x’∈ Sxi, i = 1,2,…, k}. The set
Sr corresponding to the root node r denotes the set of leaf nodes that should be used in
order to minimize the number of pairing computations. Next, we notice that in the given
decryption algorithm, Lagrange coefficients (∆i, S’x) from various levels get multiplied in
the exponent in a certain way in Zp. Thus, instead of exponentiating at each level, for
each leaf node x ∈Sr, we can keep track of which Lagrange coefficients get multiplied
with each other. Using this we can compute the final exponent fx for each leaf node x ∈
Sr by doing multiplication in Zp. Now Fr is simply ∏x∈Sr e(Dx, Eatt(x))fx. This reduces the
number of pairing computations and exponentiations to |Sr|. Thus, decryption is
dominated by |Sr| pairing computations.
The number of group elements that compose a user's private key grows linearly
with the number of leaf nodes in the access tree. The number of group elements in a
cipher text grows linearly with the size of the set we are encrypting under. Finally, the
number of group elements in the public parameters grows linearly with the number of
attributes in the defined universe. Later, we provide a construction for large universes
where all elements in Z*p can be used as attributes, yet the size of public parameters only
grows linearly in a parameter n that we set to be the maximum possible size of I.
6.2. PROXY RE-ENCRYPTION (PRE):
Proxy Re-Encryption (PRE) is a cryptographic primitive in which a semi-trusted
proxy is able to convert a cipher text encrypted under Alice’s public key into another
cipher text that can be opened by Bob’s private key without seeing the underlying
plaintext. A Proxy Re-Encryption scheme allows the proxy, given the proxy re-
Dept. of CSE, Sri Kalahasteeswara Institute of Technology, Srikalahasti
44
Achieving Secure, Scalable and Fine-grained Data Access Control in Cloud Computing
encryption key rka↔b, to translate cipher texts under
public key pka into cipher texts under public key pkb and vice versa [16].
First, we consider protocol divertibility, in which the (honest) intermediary, called
a warden, randomizes all messages so that the intended underlying protocol succeeds, but
information contained in subtle deviations from the protocol (for example, information
coded into the values of supposedly random challenges) will be obliterated by the
warden’s transformation. Next, we introduce atomic proxy cryptography, in which two
parties publish a proxy key that allows an untrusted intermediary to convert cipher texts
encrypted for the first party directly into cipher texts that can be decrypted by the second.
The intermediary learns neither clear text nor secret keys.
Divertible Protocols:
The basic observation was that some 2-party identification protocols could be
extended by placing an intermediary called a warden for historical reasons between the
prover and verifier so that, even if both parties conspire, they cannot distinguish talking
to each other through the warden from talking directly to a hypothetical honest verifier
and honest prover, respectively.
In order to deal with protocols of more than two parties, we generalize the notion
of Interactive Turing machine (ITM). Then we define connections of ITMs and finally
give the definition of protocol divertibility.
(m, n)-Interactive Turing Machine:
An (m, n)-Interactive Turing Machine ((m, n)-ITM) is a Turing machine with
m ∈ N read-only input tapes, m write-only output tapes, m read-only random tapes, a
work tape, a read-only auxiliary tape, and n ∈ N0 pairs of communication tapes. Each
pair consists of one read-only and one write-only tape that serves for reading in-messages
from or writing out-messages to another ITM. (The purpose of allowing n=0 will become
clear below.) The random tapes each contain an infinite stream of bits chosen uniformly
at random. Read-only tapes are readable only from left to right. If the string to the right of
a read-only head is empty, then we say the tape is empty.
Dept. of CSE, Sri Kalahasteeswara Institute of Technology, Srikalahasti
44
Achieving Secure, Scalable and Fine-grained Data Access Control in Cloud Computing
Associated to an ITM is a security parameter k ∈N, a family D = {Dπ}π of tuples of
domains, a probabilistic picking algorithm pick(k) and an encoding scheme S. Each
member
Dπ = (In(1 )π , . . . , In(m)π , Out(1 )π , . . . , Out(m)π , Ω(1 )π , . . . ,Ω(m)π ,
(IM (1 )π ,OM(1 )π ), . . . , (IM (n)π ,OM(n)π ))
of D contains one input (output, choice, in-message, out-message) domain for each of the
m input (output, random) tapes and n (read-only, write-only) communication tapes. The
algorithm pick(k) on input some security parameter k outputs a family index π. Finally,
there is a polynomial P(k) so that for each π chosen by pick(k), S encodes all elements of
all domains in Dπ as bitstrings of length P(k).
Atomic Proxy Cryptography:
A basic goal of public-key encryption is to allow only the key or keys selected
at the time of encryption to decrypt the cipher text. To change the cipher text to a
different key requires re-encryption of the message with the new key, which implies
access to the original clear text and to a reliable copy of the new encryption key.
Here, on the other hand, we investigate the possibility of atomic proxy functions
that convert ciphertext for one key into ciphertext for another without revealing secret
decryption keys or cleartext messages .An atomic proxy function allows an untrusted
party to convert ciphertext between keys without access to either the original message or
to the secret component of the old key or the new key.
Categories of Proxy Scheme:
Symmetric proxy functions also imply that B trusts A, e.g., because dB can be
feasibly calculated given the proxy key plus dA. Asymmetric proxy functions do not imply
this bilateral trust.
In an active asymmetric scheme, B has to cooperate to produce the proxy key
πA→B feasibly, although the proxy key (even together with A’s secret key) might not
compromise B’s secret key. In a passive asymmetric scheme, on the other hand, A’s
secret key and B’s public key suffice to construct the proxy key.
Dept. of CSE, Sri Kalahasteeswara Institute of Technology, Srikalahasti
44
Achieving Secure, Scalable and Fine-grained Data Access Control in Cloud Computing
Transparent proxy keys reveal the original two public keys to a third party.
Translucent proxy keys allow a third party to verify a guess as to which two keys are
involved (given their public keys). Opaque proxy keys reveal nothing, even to an
adversary who correctly guesses the original public keys (but who does not know the
secret keys involved).
6.3. LAZY RE-ENCRYPTION:
The lazy re-encryption technique and allow Cloud Servers to aggregate
computation tasks of multiple operations. The operations such as
Update secret keys
Update user attributes.
Lazy re-encryption operates by using correlations in data updates to decide when
to rekey. Since data re-encryption accounts for the larger part of the cost of key
replacement, re-encryption is only performed if the data changes significantly after a user
departs or if the data is highly sensitive and requires immediate re-encryption to prevent
the user from accessing it. The cost of rekeying is minimized, but the problem remains of
having to re-encrypt the data after a user’s departure. Moreover, if a sensitive file does
not change frequently, lazy re-encryption can allow a malicious user time to copy off
information from the file into another file and leave the system without ever being
detected. We have to assume that if a key k requires updating, then any objects encrypted
with k are available to any user who could derive k. Hence, we may as well wait until the
contents of an object changes before re-encrypting it. Similarly, we may as well defer
sending a user u the new key k′ until such time as u actually requires k′ to decrypt an
object. This is sometimes referred to as lazy update and lazy re-encryption.
Plutus allows owners of files to revoke other people’s rights to access those files.
Following a revocation, we assume that it is acceptable for the revoked reader to read
unmodified or cached files. A revoked reader, however, must not be able to read updated
files, nor may a revoked writer be able to modify the files. Settling for lazy revocation
trades re-encryption cost for a degree of security.
Dept. of CSE, Sri Kalahasteeswara Institute of Technology, Srikalahasti
44
Achieving Secure, Scalable and Fine-grained Data Access Control in Cloud Computing
In a large distributed system, we expect revocation of users to happen on a regular
basis. For instance, according to seven months of AFS protection server logs we obtained
from MIT, there were 29,203 individual revocations of users from 2,916 different access
control lists (counting the number of times a single user was deleted from an ACL). In
general, common revocation schemes, such as in UNIX and Windows NT, rely on the
server checking for users’ group membership before granting access. This requires all the
servers to store or cache information regarding users, which places a high trust
requirement on the servers and requires all the servers to maintain this authentication
information in a secure and consistent manner.
Revocation is a seemingly expensive operation for encrypt-on-disk systems as it
requires re-encryption (in Plutus, re-computing block hashes and re-signing root hashes
as well) of the affected files. Revocation also introduces an additional overhead as
owners now need to distribute new keys to users. Though the security semantics of
revocation need to be guaranteed, they should be implemented with minimal overhead to
the regular users sharing those files.
To make revocation less expensive, one can delay re-encryption until a file is
updated. This notion of lazy revocation was first proposed in Cepheus. The idea is that
there is no significant loss in security if revoked readers can still read unchanged files.
This is equivalent to the access the user had during the time that they were authorized
(when they could have copied the data onto floppy disks, for example). Expensive re-
encryption occurs only when new data is created. The meta-data still needs to be
immediately changed to prevent further writes by revoked writers.
A revoked reader who has access to the server will still have read access to the
files not changed since the user’s revocation, but will never be able to read data updated
since their revocation. Lazy revocation, however, is complicated when multiple files are
encrypted with the same key, as is the case when using filegroups. In this case, whenever
a file gets updated, it gets encrypted with a new key. This causes filegroups to get
fragmented (meaning a filegroup could have more than one key), which is undesirable.
The next section describes how we mitigate this problem; briefly, we show how readers
and writers can generate all the previous keys of a fragmented filegroup from the current
key.
Dept. of CSE, Sri Kalahasteeswara Institute of Technology, Srikalahasti
44
Achieving Secure, Scalable and Fine-grained Data Access Control in Cloud Computing
7. SYSTEM TESTING
The purpose of testing is to discover errors. Testing is the process of trying to
discover every conceivable fault or weakness in a work product. It provides a way to
check the functionality of components, sub assemblies, assemblies and/or a finished
product It is the process of exercising software with the intent of ensuring that the
Software system meets its requirements and user expectations and does not fail in an
unacceptable manner. There are various types of test. Each test type addresses a specific
testing requirement.
TYPES OF TESTS
Unit Testing
Unit testing involves the design of test cases that validate that the internal
program logic is functioning properly, and that program inputs produce valid outputs. All
decision branches and internal code flow should be validated. It is the testing of
individual software units of the application .it is done after the completion of an
individual unit before integration. This is a structural testing, that relies on knowledge of
its construction and is invasive. Unit tests perform basic tests at component level and test
a specific business process, application, and/or system configuration. Unit tests ensure
that each unique path of a business process performs accurately to the documented
specifications and contains clearly defined inputs and expected results.
Integration Testing
Integration tests are designed to test integrated software components to determine
if they actually run as one program. Testing is event driven and is more concerned with
the basic outcome of screens or fields. Integration tests demonstrate that although the
components were individually satisfaction, as shown by successfully unit testing, the
combination of components is correct and consistent. Integration testing is specifically
aimed at exposing the problems that arise from the combination of components.
Dept. of CSE, Sri Kalahasteeswara Institute of Technology, Srikalahasti
44
Achieving Secure, Scalable and Fine-grained Data Access Control in Cloud Computing
Functional Testing
Functional tests provide systematic demonstrations that functions tested are
available as specified by the business and technical requirements, system documentation,
and user manuals.
Functional testing is centered on the following items:
Valid Input : identified classes of valid input must be accepted.
Invalid Input : identified classes of invalid input must be rejected.
Functions : identified functions must be exercised.
Output : identified classes of application outputs must be exercised.
Systems/Procedures : interfacing systems or procedures must be invoked.
Organization and preparation of functional tests is focused on requirements, key
functions, or special test cases. In addition, systematic coverage pertaining to identify
Business process flows; data fields, predefined processes, and successive processes must
be considered for testing. Before functional testing is complete, additional tests are
identified and the effective value of current tests is determined.
System Testing
System testing ensures that the entire integrated software system meets
requirements. It tests a configuration to ensure known and predictable results. An
example of system testing is the configuration oriented system integration test. System
testing is based on process descriptions and flows, emphasizing pre-driven process links
and integration points.
White Box Testing
White Box Testing is a testing in which in which the software tester has
knowledge of the inner workings, structure and language of the software, or at least its
purpose. It is purpose. It is used to test areas that cannot be reached from a black box
level.
Black Box Testing
Black Box Testing is testing the software without any knowledge of the inner
workings, structure or language of the module being tested. Black box tests, as most other
Dept. of CSE, Sri Kalahasteeswara Institute of Technology, Srikalahasti
44
Achieving Secure, Scalable and Fine-grained Data Access Control in Cloud Computing
kinds of tests, must be written from a definitive source document, such as specification or
requirements document, such as specification or requirements document. It is a testing in
which the software under test is treated, as a black box .you cannot “see” into it. The test
provides inputs and responds to outputs without considering how the software works.
Unit Testing:
Unit testing is usually conducted as part of a combined code and unit test phase of
the software lifecycle, although it is not uncommon for coding and unit testing to be
conducted as two distinct phases.
Test strategy and approach
Field testing will be performed manually and functional tests will be written in
detail.
Test objectives
• All field entries must work properly.
• Pages must be activated from the identified link.
• The entry screen, messages and responses must not be delayed.
Features to be tested
• Verify that the entries are of the correct format
• No duplicate entries should be allowed
• All links should take the user to the correct page.
Integration Testing
Software integration testing is the incremental integration testing of two or more
integrated software components on a single platform to produce failures caused by
interface defects.
The task of the integration test is to check that components or software
applications, e.g. components in a software system or – one step up – software
applications at the company level – interact without error.
Dept. of CSE, Sri Kalahasteeswara Institute of Technology, Srikalahasti
44
Achieving Secure, Scalable and Fine-grained Data Access Control in Cloud Computing
Test Results: All the test cases mentioned above passed successfully. No defects
encountered.
Acceptance Testing
User Acceptance Testing is a critical phase of any project and requires significant
participation by the end user. It also ensures that the system meets the functional
requirements.
Test Results: All the test cases mentioned above passed successfully. No defects
encountered.
Dept. of CSE, Sri Kalahasteeswara Institute of Technology, Srikalahasti
44
Achieving Secure, Scalable and Fine-grained Data Access Control in Cloud Computing
8. CONCLUSION
Our project aims at fine-grained data access control in cloud
computing. One challenge in this context is to achieve fine-
grainedness, data confidentiality, and scalability simultaneously, which
is not provided by current work. In this paper we propose a scheme to
achieve this goal by exploiting KPABE and uniquely combining it with
techniques of proxy re-encryption and lazy re-encryption. Moreover,
our proposed scheme can enable the data owner to delegate most of
computation overhead to powerful cloud servers. Confidentiality of
user access privilege and user secret key accountability can be
achieved. Formal security proofs show that our proposed scheme is
secure under standard cryptographic models.
Dept. of CSE, Sri Kalahasteeswara Institute of Technology, Srikalahasti
44
Achieving Secure, Scalable and Fine-grained Data Access Control in Cloud Computing
REFERENCES
[1] M. Armbrust, A. Fox, R. Griffith, A. D. Joseph, R. H. Katz, A. Konwinski, G. Lee, D.
A. Patterson, A. Rabkin, I. Stoica, and M. Zaharia, “Above the clouds: A berkeley view
of cloud computing,” University of California, Berkeley, Tech. Rep. USB-EECS-2009-
28, Feb 2009.
[2] Amazon Web Services (AWS), online at http://aws.amazon.com.
[3] Google App Engine, Online at http://code.google.com/appengine/.
[4] Microsoft Azure, http://www.microsoft.com/azure/.
[5] 104th United States Congress, “Health Insurance Portability and Accountability Act
of 1996 (HIPPA),” Online at http://aspe.hhs.gov/admnsimp/pl104191.htm, 1996.
[6] H. Harney, A. Colgrove, and P. D. McDaniel, “Principles of policy in secure groups,”
in Proc. of NDSS’01, 2001.
[7] P. D. McDaniel and A. Prakash, “Methods and limitations of security policy
reconciliation,” in Proc. of SP’02, 2002.
[8] T. Yu and M. Winslett, “A unified scheme for resource protection in automated trust
negotiation,” in Proc. of SP’03, 2003.
[9] J. Li, N. Li, and W. H. Winsborough, “Automated trust negotiation using
cryptographic credentials,” in Proc. of CCS’05, 2005.
[10] J. Anderson, “Computer Security Technology Planning Study,” Air Force Electronic
Systems Division, Report ESD-TR-73-51, 1972,
http://seclab.cs.ucdavis.edu/projects/history/.
[11] M. Kallahalla, E. Riedel, R. Swaminathan, Q. Wang, and K. Fu, “Scalable secure
file sharing on untrusted storage,” in Proc. of FAST’03, 2003.
[12] E. Goh, H. Shacham, N. Modadugu, and D. Boneh, “Sirius: Securing remote
untrusted storage,” in Proc. of NDSS’03, 2003.
[13] G. Ateniese, K. Fu, M. Green, and S. Hohenberger, “Improved proxy re-encryption
schemes with applications to secure distributed storage,” in Proc. of NDSS’05, 2005.
[14] S. D. C. di Vimercati, S. Foresti, S. Jajodia, S. Paraboschi, and P. Samarati, “Over-
encryption: Management of access control evolution on outsourced data,” in Proc. of
VLDB’07, 2007.
[15] V. Goyal, O. Pandey, A. Sahai, and B. Waters, “Attribute-based encryption for fine-
grained access control of encrypted data,” in Proc. Of CCS’06, 2006.
Dept. of CSE, Sri Kalahasteeswara Institute of Technology, Srikalahasti
44
Achieving Secure, Scalable and Fine-grained Data Access Control in Cloud Computing
[16] M. Blaze, G. Bleumer, and M. Strauss, “Divertible protocols and atomic proxy
cryptography,” in Proc. of EUROCRYPT ’98, 1998.
[17] Q. Wang, C. Wang, J. Li, K. Ren, and W. Lou, “Enabling public verifiability and
data dynamics for storage security in cloud computing,” in Proc. of ESORICS ’09, 2009.
[18] L. Youseff, M. Butrico, and D. D. Silva, “Toward a unified ontology of cloud
computing,” in Proc. of GCE’08, 2008.
[19] S. Yu, K. Ren, W. Lou, and J. Li, “Defending against key abuse attacks in kp-abe
enabled broadcast systems,” in Proc. of SECURECOMM’09, 2009.
[20] D. Sheridan, “The optimality of a fast CNF conversion and its use with SAT,” in
Proc. of SAT’04, 2004.
[21] D. Naor, M. Naor, and J. B. Lotspiech, “Revocation and tracing schemes for
stateless receivers,” in Proc. of CRYPTO’01, 2001.
[22] M. Atallah, K. Frikken, and M. Blanton, “Dynamic and efficient key management
for access hierarchies,” in Proc. of CCS’05, 2005.
[23] Shucheng Yu, Cong Wang, Kui Ren, and Wenjing Lou, “Achieving Secure,
Scalable, and Fine-grained Data Access Control in Cloud Computing,” in Proc. of
INFOCOM’10, 2010.
Dept. of CSE, Sri Kalahasteeswara Institute of Technology, Srikalahasti
44
Achieving Secure, Scalable and Fine-grained Data Access Control in Cloud Computing
Screen Shots:
Default Page of the Website/Login Page
User Registration Page
After Successful Registration
Key Details of Registered User
The page that asks for mobile number to provide Secret Key to the User
Displaying Secret Key to the User
Login Page (Registered User Logging in)
Sending a keyword to search in the Cloud Server
Search results
Authentication Request to download the requested File
Download Page
Login Page (Data Owner Logging in)
Owner uploads a File
File Uploaded Successfully
Owner viewing User Details
Owner viewing the Downloads of a particular File
Dept. of CSE, Sri Kalahasteeswara Institute of Technology, Srikalahasti
44
Achieving Secure, Scalable and Fine-grained Data Access Control in Cloud Computing
Login Page (Again the User)
Sends a keyword to search in the Cloud Server
Search Results (The last file is uploaded in the previous section by the owner)
User providing wrong Secret Key
No download is occurred
The User Account is blocked
Dept. of CSE, Sri Kalahasteeswara Institute of Technology, Srikalahasti
44
You might also like
- Migration Document - SharePoint 2010 On-Premise Server To SharePoint OnlineDocument2 pagesMigration Document - SharePoint 2010 On-Premise Server To SharePoint OnlineSurjith JithuNo ratings yet
- Pim PPTDocument3 pagesPim PPTNavneetGuptaNo ratings yet
- Microsoft Azure Business Continuity Solutio PDFDocument2 pagesMicrosoft Azure Business Continuity Solutio PDFgerardo arceNo ratings yet
- Professional Cloud Security Manager - Mock ExamDocument22 pagesProfessional Cloud Security Manager - Mock ExamCSK100% (1)
- Cloud Integration A Complete Guide - 2019 EditionFrom EverandCloud Integration A Complete Guide - 2019 EditionRating: 5 out of 5 stars5/5 (1)
- Active Directory Migration Strategy A Complete Guide - 2020 EditionFrom EverandActive Directory Migration Strategy A Complete Guide - 2020 EditionNo ratings yet
- Software As A ServiceDocument19 pagesSoftware As A ServiceSoniya VaswaniNo ratings yet
- Cloud Computing NotesDocument134 pagesCloud Computing NotesSohail KhanNo ratings yet
- OWASP Vulnerability Management GuideDocument20 pagesOWASP Vulnerability Management Guidetarzi01No ratings yet
- CLO02-Cloud Solutions ArchitectDocument2 pagesCLO02-Cloud Solutions ArchitectharibabuNo ratings yet
- Proposal No. Frame Agreement:: XXX/XX - XX.XXXX XX - XX.XXXXDocument3 pagesProposal No. Frame Agreement:: XXX/XX - XX.XXXX XX - XX.XXXXDicu AndreiNo ratings yet
- Endpoint Encryption Powered by PGP Technology: Proof of Concept DocumentDocument9 pagesEndpoint Encryption Powered by PGP Technology: Proof of Concept DocumentNaveen AlluriNo ratings yet
- This Is Cloud Data ManagementDocument2 pagesThis Is Cloud Data ManagementRayanNo ratings yet
- Securosis Secrets Management JAN2018 FINALDocument20 pagesSecurosis Secrets Management JAN2018 FINALSalah AyoubiNo ratings yet
- Adopting An Application Portfolio Management Approach: Key Principles and Good PracticesDocument24 pagesAdopting An Application Portfolio Management Approach: Key Principles and Good PracticesMateo Álvarez Henao100% (1)
- Cloud Computing Concerns of The U S GovernmentDocument213 pagesCloud Computing Concerns of The U S GovernmentkpopescoNo ratings yet
- DrupalDocument9 pagesDrupalComputer Science EducationNo ratings yet
- Everett & McKinsey Identity and Access Management 2009 SurveyDocument40 pagesEverett & McKinsey Identity and Access Management 2009 SurveyAmit KinariwalaNo ratings yet
- Dajana YasarDocument2 pagesDajana YasarAnvesh RecruitNo ratings yet
- Cloud Security and Its InfrastructureDocument22 pagesCloud Security and Its InfrastructureRahul saini100% (1)
- Security Pillar: AWS Well-Architected FrameworkDocument37 pagesSecurity Pillar: AWS Well-Architected FrameworkRaziwanNo ratings yet
- PM - 157 - Project Logistic and Infrastructure TemplateDocument4 pagesPM - 157 - Project Logistic and Infrastructure TemplateJarlei GoncalvesNo ratings yet
- Service Now Application Product OverviewDocument10 pagesService Now Application Product OverviewvinitNo ratings yet
- Cloud Quiz Question AnswerDocument12 pagesCloud Quiz Question Answertayyab bsra juttNo ratings yet
- Case Study On Cloud SecurityDocument11 pagesCase Study On Cloud SecurityJohn Singh100% (1)
- State Data Center Migration Project Charter: DraftDocument19 pagesState Data Center Migration Project Charter: Draftakram_alqadasiitNo ratings yet
- IBM Open PagesDocument17 pagesIBM Open PagesProduct Poshan100% (1)
- SOW Service - Platform.and - Infrastructure.system - And.database - ArchitectureDocument35 pagesSOW Service - Platform.and - Infrastructure.system - And.database - ArchitecturegmasayNo ratings yet
- IamDocument3 pagesIamBunnyNo ratings yet
- Data MeshDocument4 pagesData Meshcharlotte899No ratings yet
- Simplified: SecurityDocument31 pagesSimplified: SecurityAlexandru BurucNo ratings yet
- WP Delivering Enterprise Value With Service Management PDFDocument23 pagesWP Delivering Enterprise Value With Service Management PDFJoey ANo ratings yet
- ZabbixDocument45 pagesZabbixlexcyrNo ratings yet
- Next-Generation Test Data Management: How To Deliver The Right Test Data, To The Right Teams, at The Right TimeDocument10 pagesNext-Generation Test Data Management: How To Deliver The Right Test Data, To The Right Teams, at The Right Timesaur089229No ratings yet
- An Introduction To Firewalls and The Firewall Selection ProcessDocument10 pagesAn Introduction To Firewalls and The Firewall Selection ProcessS SagarNo ratings yet
- Cloud Cost Monitoring and Management ServiceDocument3 pagesCloud Cost Monitoring and Management ServiceCloud VerseNo ratings yet
- SysCloud's Guide To Gmail BackupDocument69 pagesSysCloud's Guide To Gmail BackupSysCloudNo ratings yet
- NIST SP 800-53ar5Document733 pagesNIST SP 800-53ar5Sigan ReimondoNo ratings yet
- Introduction To Cloud Databases: Lecturer: Dr. Pavle MoginDocument23 pagesIntroduction To Cloud Databases: Lecturer: Dr. Pavle MoginlcofresiNo ratings yet
- Designing The Service Delivery ProcessDocument15 pagesDesigning The Service Delivery ProcessJosante TaylorNo ratings yet
- C Gart63Document14 pagesC Gart63raj.raidurNo ratings yet
- Brazil Datacenter - OverviewDocument10 pagesBrazil Datacenter - OverviewTalent NeuronNo ratings yet
- Bsimm-V: The Building Security in Maturity ModelDocument32 pagesBsimm-V: The Building Security in Maturity ModelmabesninaNo ratings yet
- CheckList ISO 20000 1Document2 pagesCheckList ISO 20000 1Teresa SerraoNo ratings yet
- Cloud Computing Security TechniquesDocument8 pagesCloud Computing Security TechniquesVinod NaiduNo ratings yet
- BitLocker Design GuideDocument47 pagesBitLocker Design GuidelayantNo ratings yet
- Sap Bw/4Hana Why Do I Need It? Why Do I Want It?Document4 pagesSap Bw/4Hana Why Do I Need It? Why Do I Want It?rohan laddhaNo ratings yet
- Azure ADDocument10 pagesAzure ADrachel gomezNo ratings yet
- Security Framework For Cloud ComputingDocument9 pagesSecurity Framework For Cloud Computingjack s99No ratings yet
- Experience Summary: Rampalli Srinivasa RaoDocument5 pagesExperience Summary: Rampalli Srinivasa Raoapi-3779816No ratings yet
- Solutions For Financial Services: Openlink Opencomponents - Next Generation Component Development StrategyDocument4 pagesSolutions For Financial Services: Openlink Opencomponents - Next Generation Component Development StrategyMata KikuniNo ratings yet
- Identity and Access Management 1Document6 pagesIdentity and Access Management 1catudayjaNo ratings yet
- ASSIGENMENTDocument13 pagesASSIGENMENTR.N. PatelNo ratings yet
- Hybrid Encryption For Cloud Database Security-AnnotatedDocument7 pagesHybrid Encryption For Cloud Database Security-AnnotatedClaireNo ratings yet
- General - Resume - 6 2020 IAM and PM Okta 2Document8 pagesGeneral - Resume - 6 2020 IAM and PM Okta 2Rohit BhasinNo ratings yet
- Top Threats To Cloud ComputingDocument9 pagesTop Threats To Cloud ComputingVinny BamrahNo ratings yet
- Migration To Google Cloud WWW - Powerupcloud.com 1.PDF 1Document4 pagesMigration To Google Cloud WWW - Powerupcloud.com 1.PDF 1purum100% (1)
- Az 900 Identity AccessDocument8 pagesAz 900 Identity AccessmaheshNo ratings yet
- Top-Down Network Design: Chapter SixDocument50 pagesTop-Down Network Design: Chapter SixyogaNo ratings yet
- Domain 1 PDFDocument22 pagesDomain 1 PDFKrish krishNo ratings yet
- Fnde 103Document1 pageFnde 103hemacrcNo ratings yet
- UnitIVCourseProject SampleAnswersDocument3 pagesUnitIVCourseProject SampleAnswersnarender0% (1)
- Lec 2 - GIS DataDocument83 pagesLec 2 - GIS DataAlind mmNo ratings yet
- E-Voting System For EthiopiaDocument76 pagesE-Voting System For Ethiopiaiyasu ayenekuluNo ratings yet
- Ultimus 6 Product GuideDocument64 pagesUltimus 6 Product GuideKevin James Emanuel ResiNo ratings yet
- DocumentDocument905 pagesDocumentpavan kumarNo ratings yet
- Tactical Drone Jammer (Dronegun) Product CompletedDocument19 pagesTactical Drone Jammer (Dronegun) Product CompleteddanuNo ratings yet
- IMV 2010 BovineDocument40 pagesIMV 2010 BovineInstrulife OostkampNo ratings yet
- Unit 3 SQL Extra-1-4Document4 pagesUnit 3 SQL Extra-1-4rakshit dhokaNo ratings yet
- Bca 223 SsadDocument96 pagesBca 223 SsadBipin SaraswatNo ratings yet
- PRISM G2 v4 - 6 Release NotesDocument37 pagesPRISM G2 v4 - 6 Release NotesDennis Mendoza100% (1)
- Security Real-Time Data Auditing With Extended Oracle Change Data CaptureDocument6 pagesSecurity Real-Time Data Auditing With Extended Oracle Change Data CapturelbrittobaNo ratings yet
- Core - Database - Timeline Nouman ShamimDocument2 pagesCore - Database - Timeline Nouman ShamimNouman Shamim - 50145/TCHR/BKJCNo ratings yet
- Axtraxng: Access Control Management SoftwareDocument2 pagesAxtraxng: Access Control Management SoftwareDvripto IrapuatoNo ratings yet
- Distributing Full Use Licenses For Applications Programs Skills Assessment Test 1 PDFDocument1 pageDistributing Full Use Licenses For Applications Programs Skills Assessment Test 1 PDFPeace For AllNo ratings yet
- Call Recorder VoIP Manual EN V1.2Document29 pagesCall Recorder VoIP Manual EN V1.2Riky FitriadiNo ratings yet
- Achieving DFT Accuracy With A Machine-Learning Interatomic Potential: Thermomechanics and Defects in BCC Ferromagnetic IronDocument19 pagesAchieving DFT Accuracy With A Machine-Learning Interatomic Potential: Thermomechanics and Defects in BCC Ferromagnetic IrontaherymahsaaNo ratings yet
- Oracle Database Upgrade MethodsDocument20 pagesOracle Database Upgrade MethodshassanNo ratings yet
- 1 Processs Flow Diagram - Lessons LearnedDocument2 pages1 Processs Flow Diagram - Lessons LearnedishuaibNo ratings yet
- I.T. Class-X ST LAWRENCE PRE BOARDSDocument2 pagesI.T. Class-X ST LAWRENCE PRE BOARDSdatalogdigitalNo ratings yet
- UrbanCode Deploy ScenariosDocument13 pagesUrbanCode Deploy ScenariosGeyzyely LimaNo ratings yet
- COMPUTER SCIENCE (M SC (CS) )Document14 pagesCOMPUTER SCIENCE (M SC (CS) )Chandra Sekhar DNo ratings yet
- Infoscale PresentationDocument35 pagesInfoscale PresentationIrfan Khan0% (1)
- Dell - Test Inside - DSDSC 200.v2018!06!23.by - Sebastian.69qDocument46 pagesDell - Test Inside - DSDSC 200.v2018!06!23.by - Sebastian.69qNguyen Hoang AnhNo ratings yet
- Data MiningDocument3 pagesData MiningTran Minh TuNo ratings yet
- 2060 VBDocument24 pages2060 VBJyothikala JooNo ratings yet
- MVC Workflow With JPaginationDocument5 pagesMVC Workflow With JPaginationManoka76No ratings yet
- Mannila 1997Document15 pagesMannila 1997Enny KinanthiNo ratings yet
- Oracle SQL Quick ReferenceDocument180 pagesOracle SQL Quick Referencechamisso chenNo ratings yet
- Instalacion Oracle en Linux RHDocument16 pagesInstalacion Oracle en Linux RHAdrian MerloNo ratings yet