You might also like
- A-level Maths Revision: Cheeky Revision ShortcutsFrom EverandA-level Maths Revision: Cheeky Revision ShortcutsRating: 3.5 out of 5 stars3.5/5 (8)
- Module in Engineering Data Analysis - Discrete Probability DistributionDocument7 pagesModule in Engineering Data Analysis - Discrete Probability DistributionCrystel JazamaeNo ratings yet
- Numerical Integration: Project PHYSNET Physics Bldg. Michigan State University East Lansing, MIDocument10 pagesNumerical Integration: Project PHYSNET Physics Bldg. Michigan State University East Lansing, MIEpic WinNo ratings yet
- ML Final Lab ManualDocument68 pagesML Final Lab ManualAwanit KumarNo ratings yet
- SGFilter - A Stand-Alone Implementation of The Savitzky-Golay Smoothing FilterDocument42 pagesSGFilter - A Stand-Alone Implementation of The Savitzky-Golay Smoothing FilterFredrik JonssonNo ratings yet
- Bayesian Monte Carlo: Carl Edward Rasmussen and Zoubin GhahramaniDocument8 pagesBayesian Monte Carlo: Carl Edward Rasmussen and Zoubin GhahramanifishelderNo ratings yet
- MATLAB Pattern Recognition GuideDocument58 pagesMATLAB Pattern Recognition GuidemiusayNo ratings yet
- ML RecapDocument96 pagesML RecapAmit MithunNo ratings yet
- Lecture 3Document6 pagesLecture 3د. سعد قاسم الاجهزة الطبيةNo ratings yet
- E9 205 - Machine Learning For Signal ProcessingDocument3 pagesE9 205 - Machine Learning For Signal ProcessingUday GulghaneNo ratings yet
- Machine Learning: Algorithms and Applications: Philip O. OgunbonaDocument29 pagesMachine Learning: Algorithms and Applications: Philip O. OgunbonaNguyễn Hoàng Phương TrầnNo ratings yet
- LFD 2005 Nearest NeighbourDocument6 pagesLFD 2005 Nearest NeighbourAnahi SánchezNo ratings yet
- Raycasting: Direct Volume RenderingDocument6 pagesRaycasting: Direct Volume RenderingCarlos FernandezNo ratings yet
- E9 205 - Machine Learning For Signal ProcessingDocument3 pagesE9 205 - Machine Learning For Signal Processingrishi guptaNo ratings yet
- CHP 1curve FittingDocument21 pagesCHP 1curve FittingAbrar HashmiNo ratings yet
- FRP PDFDocument19 pagesFRP PDFmsl_cspNo ratings yet
- Multifractal measurements introductionDocument60 pagesMultifractal measurements introductionNajmeddine AttiaNo ratings yet
- Wu ZhangDocument8 pagesWu ZhangSagittarius BNo ratings yet
- International Refereed Journal of Engineering and Science (IRJES)Document8 pagesInternational Refereed Journal of Engineering and Science (IRJES)www.irjes.comNo ratings yet
- Learning More Accurate Metrics For Self-Organizing MapsDocument6 pagesLearning More Accurate Metrics For Self-Organizing MapsctorreshhNo ratings yet
- Exam 2:: All AllDocument12 pagesExam 2:: All AllUsama FaisalNo ratings yet
- E ≡ 1 f x x aj (x) ∆ wj=η f x x aj (x) η: x∈ D x∈DDocument2 pagesE ≡ 1 f x x aj (x) ∆ wj=η f x x aj (x) η: x∈ D x∈DTameemuddinNo ratings yet
- ML DSBA Lab4Document5 pagesML DSBA Lab4Houssam FoukiNo ratings yet
- Modal Frequency Analysis using MSC NastranDocument13 pagesModal Frequency Analysis using MSC Nastran5colourbalaNo ratings yet
- Line of Sight Rate Estimation With PFDocument5 pagesLine of Sight Rate Estimation With PFAlpaslan KocaNo ratings yet
- ML CheatsheetDocument1 pageML Cheatsheetfrancoisroyer7709No ratings yet
- Decision Tree For 3-D Connected Components LabelingDocument5 pagesDecision Tree For 3-D Connected Components LabelingPhaisarn SutheebanjardNo ratings yet
- Module 5 Notes 1Document26 pagesModule 5 Notes 1Mohammad Athiq kamranNo ratings yet
- 15 Ec 834Document26 pages15 Ec 834Rocky 1999No ratings yet
- Chapter 07Document68 pagesChapter 07Enfant MortNo ratings yet
- Schwarz-Christoffel Toolbox User's Guide: 1 Executive SummaryDocument26 pagesSchwarz-Christoffel Toolbox User's Guide: 1 Executive Summarychenwx21No ratings yet
- Artificial Neural Networks: Multilayer Perceptrons BackpropagationDocument71 pagesArtificial Neural Networks: Multilayer Perceptrons BackpropagationdinkarbhombeNo ratings yet
- Csci567 Hw1 Spring 2016Document9 pagesCsci567 Hw1 Spring 2016mhasanjafryNo ratings yet
- Publication C28 4Document10 pagesPublication C28 4Mohamed Habashy MubarakNo ratings yet
- Spatial Point Density Estimation TechniquesDocument63 pagesSpatial Point Density Estimation TechniquesJohnNo ratings yet
- Dar Unit-4Document23 pagesDar Unit-4Kalyan VarmaNo ratings yet
- CNN Notes on Convolutional Neural NetworksDocument8 pagesCNN Notes on Convolutional Neural NetworksGiri PrakashNo ratings yet
- Advantages:: Q.No 1.a AnsDocument12 pagesAdvantages:: Q.No 1.a AnsTiwari VivekNo ratings yet
- Experiment 2 ExpressionsDocument4 pagesExperiment 2 Expressionskurddoski28No ratings yet
- 9 Unsupervised Learning: 9.1 K-Means ClusteringDocument34 pages9 Unsupervised Learning: 9.1 K-Means ClusteringJavier RivasNo ratings yet
- Dimensionality ReductionDocument41 pagesDimensionality Reductionh_mursalinNo ratings yet
- PQT NotesDocument337 pagesPQT NotesDot Kidman100% (1)
- Cluster Analysis: Dr. Bernard Chen Ph.D. Assistant ProfessorDocument43 pagesCluster Analysis: Dr. Bernard Chen Ph.D. Assistant Professorrajeshkumar_niceNo ratings yet
- Part 4: Conditional Random Fields: Sebastian Nowozin and Christoph H. LampertDocument39 pagesPart 4: Conditional Random Fields: Sebastian Nowozin and Christoph H. LampertTgjeonNo ratings yet
- Module 5 AIMLDocument18 pagesModule 5 AIMLgovardhanhl5411No ratings yet
- CP 8Document1 pageCP 8Ankita MishraNo ratings yet
- Anthony Kuh - Neural Networks and Learning TheoryDocument72 pagesAnthony Kuh - Neural Networks and Learning TheoryTuhmaNo ratings yet
- Isi Mtech Qror 05Document20 pagesIsi Mtech Qror 05api-26401608No ratings yet
- Optimally Rotation-Equivariant DirectionalDocument8 pagesOptimally Rotation-Equivariant DirectionalEloisa PotrichNo ratings yet
- How To Use "Qqplot": X: Independent Variable, Y: Dependent VariableDocument6 pagesHow To Use "Qqplot": X: Independent Variable, Y: Dependent VariableDaniel WuNo ratings yet
- Python-Advances in Probabilistic Graphical ModelsDocument102 pagesPython-Advances in Probabilistic Graphical Modelsnaveen441No ratings yet
- CSE 474/574 Introduction To Machine Learning Fall 2011 Assignment 3Document3 pagesCSE 474/574 Introduction To Machine Learning Fall 2011 Assignment 3kwzeetNo ratings yet
- KNN, LVQ, SomDocument37 pagesKNN, LVQ, SomKimberley Rodriguez LopezNo ratings yet
- Survey of Trust-Region Derivative Free Optimization MethodsDocument12 pagesSurvey of Trust-Region Derivative Free Optimization MethodsMariangela PintoNo ratings yet
- Pca SlidesDocument33 pagesPca Slidesforscribd1981No ratings yet
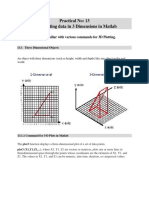
- Practical No 13Document11 pagesPractical No 13Mohammad AhsanNo ratings yet
- Session 2 Student Text1Document8 pagesSession 2 Student Text1ukiNo ratings yet
- 10.3 One-Dimensional Search With First DerivativesDocument4 pages10.3 One-Dimensional Search With First DerivativesRajivSadewaNo ratings yet
- Handouts On Data-Driven Modelling, Part 2 (UNESCO-IHE)Document27 pagesHandouts On Data-Driven Modelling, Part 2 (UNESCO-IHE)solomatineNo ratings yet
- Handouts On Data-Driven Modelling, Part 1 (UNESCO-IHE)Document62 pagesHandouts On Data-Driven Modelling, Part 1 (UNESCO-IHE)solomatineNo ratings yet
- Hydroinformatics - Possibilities For PHDDocument3 pagesHydroinformatics - Possibilities For PHDsolomatineNo ratings yet
- Introduction To Hydroinformatics - Presentation For UNESCO-IHE Students (v16)Document60 pagesIntroduction To Hydroinformatics - Presentation For UNESCO-IHE Students (v16)solomatineNo ratings yet
- Abbott Hydro in For Ma Tics Chapter1 FullDocument52 pagesAbbott Hydro in For Ma Tics Chapter1 FullsolomatineNo ratings yet
- JOGO99 GloptDocument20 pagesJOGO99 GloptsolomatineNo ratings yet
- Clustering & PCA Assignment QuestionsDocument4 pagesClustering & PCA Assignment QuestionsAmith C GowdaNo ratings yet
- Image SegmentationDocument3 pagesImage SegmentationrajasekarNo ratings yet
- Speech Detection On Urban SoundsDocument66 pagesSpeech Detection On Urban SoundsFardeen KhanNo ratings yet
- A Wavelet-Based Anytime Algorithm For K-Means Clustering of Time SeriesDocument12 pagesA Wavelet-Based Anytime Algorithm For K-Means Clustering of Time SeriesYaseen HussainNo ratings yet
- 10 1016@j Simpat 2020 102198Document17 pages10 1016@j Simpat 2020 102198Shrijan SinghNo ratings yet
- 2022 CS244 End Sem SolnDocument6 pages2022 CS244 End Sem SolnBhanu MacharlaNo ratings yet
- Trajectons: Motion Analysis of Tracked Features for Action RecognitionDocument8 pagesTrajectons: Motion Analysis of Tracked Features for Action RecognitionyunciNo ratings yet
- Classification of Automatic Detection of Plant Disease in Leaves and Fruits Using Image Processing With Convolutional Neural NetworkDocument7 pagesClassification of Automatic Detection of Plant Disease in Leaves and Fruits Using Image Processing With Convolutional Neural NetworkBhargavi KmNo ratings yet
- Introduction To Big Data and Data MiningDocument130 pagesIntroduction To Big Data and Data MiningTse ChrisNo ratings yet
- Comparing band math equations for measuring suspended material in coastal watersDocument6 pagesComparing band math equations for measuring suspended material in coastal waterslabibmalikalmhadiNo ratings yet
- Image Clustering: Prof. Dr. Rafiqul Islam Department of CSEDocument26 pagesImage Clustering: Prof. Dr. Rafiqul Islam Department of CSEMainul IslamNo ratings yet
- Machine Learning Zero To Hero 6 WeeksDocument6 pagesMachine Learning Zero To Hero 6 WeeksHitesh MaliNo ratings yet
- Cluster Analysis Techniques and ApplicationsDocument152 pagesCluster Analysis Techniques and ApplicationsShashwat MishraNo ratings yet
- Crime Prediction Using K-Means AlgorithmDocument4 pagesCrime Prediction Using K-Means AlgorithmGRD Journals100% (1)
- Hierarchical Clustering PDFDocument5 pagesHierarchical Clustering PDFLikitha ReddyNo ratings yet
- Fetal Heart Rate: ExplorationDocument32 pagesFetal Heart Rate: ExplorationSruthisri RahulNo ratings yet
- DM GTU Study Material Presentations Unit-5 21052021124400PMDocument63 pagesDM GTU Study Material Presentations Unit-5 21052021124400PMSarvaiya SanjayNo ratings yet
- Data Mining Lab Manual: Aurora's PG College Moosarambagh Mca DepartmentDocument42 pagesData Mining Lab Manual: Aurora's PG College Moosarambagh Mca DepartmentladooroyNo ratings yet
- K-Means Clustering with Euclidean vs Manhattan DistanceDocument7 pagesK-Means Clustering with Euclidean vs Manhattan DistanceSwapnaNo ratings yet
- Combined K-Means and Hierarchical Clustering Method For Improving Clustering Efficiency of MicroarrayDocument4 pagesCombined K-Means and Hierarchical Clustering Method For Improving Clustering Efficiency of Microarraydhruv gargNo ratings yet
- Clustering Approaches For Financial Data Analysis PDFDocument7 pagesClustering Approaches For Financial Data Analysis PDFNewton LinchenNo ratings yet
- An Introduction To WEKA Explorer: in Part From: Yizhou Sun 2008Document104 pagesAn Introduction To WEKA Explorer: in Part From: Yizhou Sun 2008Pablo VelaNo ratings yet
- Lecture - 9 Unsupervised Learning (K-Means, Association Analysis and Frequuent Items)Document73 pagesLecture - 9 Unsupervised Learning (K-Means, Association Analysis and Frequuent Items)ABDURAHMAN ABDELLANo ratings yet
- 3 mmPSODocument21 pages3 mmPSOGoran WnisNo ratings yet
- PlantDisease Classifier CodeDocument20 pagesPlantDisease Classifier CodeNeeraj SirvisettiNo ratings yet
- Intro To Data Science SummaryDocument17 pagesIntro To Data Science SummaryHussein ElGhoulNo ratings yet
- Level II of CFA Program Item-Set - Questions Study Session 3 June 2020Document3 pagesLevel II of CFA Program Item-Set - Questions Study Session 3 June 2020BK ZhangNo ratings yet
- ML Lab Manual TE 2021-22Document43 pagesML Lab Manual TE 2021-22FD04 Alok KaduNo ratings yet
- Tea Leaf Diseases Detection and Prevention by Using K-NN AlgorithmDocument10 pagesTea Leaf Diseases Detection and Prevention by Using K-NN AlgorithmVarun H RNo ratings yet