You might also like
- Probability For Ai2Document8 pagesProbability For Ai2alphamale173No ratings yet
- Multivariate Probability: 1 Discrete Joint DistributionsDocument10 pagesMultivariate Probability: 1 Discrete Joint DistributionshamkarimNo ratings yet
- 10-701/15-781, Machine Learning: Homework 1: Aarti Singh Carnegie Mellon UniversityDocument6 pages10-701/15-781, Machine Learning: Homework 1: Aarti Singh Carnegie Mellon Universitytarun guptaNo ratings yet
- Random Variables and Probability DistributionDocument73 pagesRandom Variables and Probability Distributionkelihe8947No ratings yet
- G RandomvariablesDocument18 pagesG RandomvariablesJason Tagapan GullaNo ratings yet
- Chapter 02Document50 pagesChapter 02Jack Ignacio NahmíasNo ratings yet
- Homework 3: SVM and Sentiment Analysis: Minted ListingsDocument7 pagesHomework 3: SVM and Sentiment Analysis: Minted ListingsMayur AgrawalNo ratings yet
- Tutorial On Helmholtz MachineDocument26 pagesTutorial On Helmholtz MachineNon SenseNo ratings yet
- Unit 5 Probabilistic ModelsDocument39 pagesUnit 5 Probabilistic ModelsRam100% (1)
- Probability Density FunctionsDocument8 pagesProbability Density FunctionsThilini NadeeshaNo ratings yet
- Frequentist Estimation: 4.1 Likelihood FunctionDocument6 pagesFrequentist Estimation: 4.1 Likelihood FunctionJung Yoon SongNo ratings yet
- Lecture5 Maximum LikelihoodDocument13 pagesLecture5 Maximum LikelihoodGerman Galdamez OvandoNo ratings yet
- Random Variables PDFDocument64 pagesRandom Variables PDFdeelipNo ratings yet
- Numerical Analysis and ComputingDocument44 pagesNumerical Analysis and ComputingHéctor F BonillaNo ratings yet
- 04 Scipy and ScikitDocument24 pages04 Scipy and Scikitgiordano manciniNo ratings yet
- Probability and Stats NotesDocument14 pagesProbability and Stats NotesMichael GarciaNo ratings yet
- LN06 Random VariablesDocument5 pagesLN06 Random VariablesLucky AlamsyahNo ratings yet
- Class 4Document9 pagesClass 4Smruti RanjanNo ratings yet
- Machine Learning in MATLAB: Roland MemisevicDocument16 pagesMachine Learning in MATLAB: Roland MemisevicRupesh SushirNo ratings yet
- Anomaly Detection - Problem MotivationDocument9 pagesAnomaly Detection - Problem MotivationmarcNo ratings yet
- Variation AlDocument25 pagesVariation AlshomitbNo ratings yet
- Accuracy Precision and RecallDocument12 pagesAccuracy Precision and Recallksoleti8254No ratings yet
- Machine Learning and Pattern Recognition Background Selftest AnswersDocument5 pagesMachine Learning and Pattern Recognition Background Selftest AnswerszeliawillscumbergNo ratings yet
- Statistics Concepts: An Overview of Upper-Division Statistics With RDocument69 pagesStatistics Concepts: An Overview of Upper-Division Statistics With RmukeshNo ratings yet
- ES209 Module 3 - Discrete Probability DistributionDocument14 pagesES209 Module 3 - Discrete Probability DistributionMoguri OwowNo ratings yet
- Probability Distributions in RDocument42 pagesProbability Distributions in RNaski KuafniNo ratings yet
- Na Ive Bayes ClassifierDocument3 pagesNa Ive Bayes ClassifierWill CorleoneNo ratings yet
- Lecture 9 - SVMDocument42 pagesLecture 9 - SVMHusein YusufNo ratings yet
- ML Section14 GMM emDocument53 pagesML Section14 GMM emdummyNo ratings yet
- InterpolationDocument18 pagesInterpolationNathalia Ysabelle ReigoNo ratings yet
- ML:Introduction: Week 1 Lecture NotesDocument5 pagesML:Introduction: Week 1 Lecture NotesAKNo ratings yet
- Rational Root TheoremDocument2 pagesRational Root TheoremLastCardHolderNo ratings yet
- 1 Difference Between Grad and Undergrad Algorithms: Lecture 1: Course Intro and HashingDocument8 pages1 Difference Between Grad and Undergrad Algorithms: Lecture 1: Course Intro and Hashingclouds lauNo ratings yet
- Parzen WindowingDocument10 pagesParzen WindowingAvishek ChowdhuryNo ratings yet
- Unit 1 - Digital Communication - WWW - Rgpvnotes.inDocument11 pagesUnit 1 - Digital Communication - WWW - Rgpvnotes.in0111ec211064.pallaviNo ratings yet
- Homework #5: MA 402 Mathematics of Scientific Computing Due: Monday, September 27Document6 pagesHomework #5: MA 402 Mathematics of Scientific Computing Due: Monday, September 27ra100% (1)
- Comp Intel Cheat SheetDocument2 pagesComp Intel Cheat SheetDanielNo ratings yet
- EE 561 Communication Theory Spring 2003Document27 pagesEE 561 Communication Theory Spring 2003Mohamed Ziad AlezzoNo ratings yet
- MidtermDocument12 pagesMidtermEman AsemNo ratings yet
- OQM Lecture Note - Part 1 Introduction To Mathematical OptimisationDocument10 pagesOQM Lecture Note - Part 1 Introduction To Mathematical OptimisationdanNo ratings yet
- Assign 1Document5 pagesAssign 1darkmanhiNo ratings yet
- Estimation Theory PresentationDocument66 pagesEstimation Theory PresentationBengi Mutlu Dülek100% (1)
- L3 Linear RegressionDocument23 pagesL3 Linear RegressionHieu Tien TrinhNo ratings yet
- Machine Learning and Pattern Recognition Week 3 Intro - ClassificationDocument5 pagesMachine Learning and Pattern Recognition Week 3 Intro - ClassificationzeliawillscumbergNo ratings yet
- Factoring Polynomials and Solving Higher Degree Equations: Nikos Apostolakis November 15, 2008Document15 pagesFactoring Polynomials and Solving Higher Degree Equations: Nikos Apostolakis November 15, 2008doocsNo ratings yet
- 6 Classic Theory of Point Estimation: 6.1 Likelihood Function and MLE: Conceptual DiscussionDocument63 pages6 Classic Theory of Point Estimation: 6.1 Likelihood Function and MLE: Conceptual DiscussionsergioandradNo ratings yet
- Statistical Machine Learning-The Basic Approach and Current Research ChallengesDocument35 pagesStatistical Machine Learning-The Basic Approach and Current Research Challengesnikhilesh kumarNo ratings yet
- Series 1, Oct 1st, 2013 Probability and Related) : Machine LearningDocument4 pagesSeries 1, Oct 1st, 2013 Probability and Related) : Machine Learningshelbot22No ratings yet
- Review6 9Document24 pagesReview6 9api-234480282No ratings yet
- Econometrics 2019 PDFDocument143 pagesEconometrics 2019 PDFOlivia PriciliaNo ratings yet
- CTB Chapter Lattice Introduction enDocument91 pagesCTB Chapter Lattice Introduction enRồng TrươngNo ratings yet
- Prob Distribution 1Document86 pagesProb Distribution 1karan79No ratings yet
- Introduction To Rewriting and Functional ProgrammingDocument355 pagesIntroduction To Rewriting and Functional ProgrammingcluxNo ratings yet
- Probability MeasureDocument22 pagesProbability MeasureLilia XaNo ratings yet
- Random VariablesDocument44 pagesRandom VariablesOtAkU 101No ratings yet
- Statistics and Probability KatabasisDocument7 pagesStatistics and Probability KatabasisDaniel N Sherine FooNo ratings yet
- The Binary Entropy Function: ECE 7680 Lecture 2 - Definitions and Basic FactsDocument8 pagesThe Binary Entropy Function: ECE 7680 Lecture 2 - Definitions and Basic Factsvahap_samanli4102No ratings yet
- Session3 PSQT DKJDocument83 pagesSession3 PSQT DKJdharmendrakumar_jaiswalNo ratings yet
- All LectureNotesDocument155 pagesAll LectureNotesSrinivas NemaniNo ratings yet
- Dept & Sem: Subject Name: Course Code: Unit: Prepared byDocument75 pagesDept & Sem: Subject Name: Course Code: Unit: Prepared by474 likithkumarreddy1No ratings yet
- What Are The Advantages and Disadvantages of UsingDocument4 pagesWhat Are The Advantages and Disadvantages of UsingJofet Mendiola88% (8)
- Pontevedra 1 Ok Action PlanDocument5 pagesPontevedra 1 Ok Action PlanGemma Carnecer Mongcal50% (2)
- Level Swiches Data SheetDocument4 pagesLevel Swiches Data SheetROGELIO QUIJANONo ratings yet
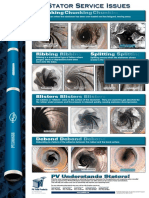
- Chunking Chunking Chunking: Stator Service IssuesDocument1 pageChunking Chunking Chunking: Stator Service IssuesGina Vanessa Quintero CruzNo ratings yet
- Junos ErrorsDocument2 pagesJunos ErrorsrashidsharafatNo ratings yet
- Sample Interview Questions For Planning EngineersDocument16 pagesSample Interview Questions For Planning EngineersPooja PawarNo ratings yet
- Thermodynamic c106Document120 pagesThermodynamic c106Драгослав БјелицаNo ratings yet
- Assignment-For-Final of-Supply-Chain - Management of Courses PSC 545 & 565 PDFDocument18 pagesAssignment-For-Final of-Supply-Chain - Management of Courses PSC 545 & 565 PDFRAKIB HOWLADERNo ratings yet
- Reading Stressful Jobs 1 4Document4 pagesReading Stressful Jobs 1 4Ivana C. AgudoNo ratings yet
- Course DescriptionDocument54 pagesCourse DescriptionMesafint lisanuNo ratings yet
- Lecture 12 Health Management Information SystemDocument14 pagesLecture 12 Health Management Information SystemKamran SheikhNo ratings yet
- Household: Ucsp11/12Hsoiii-20Document2 pagesHousehold: Ucsp11/12Hsoiii-20Igorota SheanneNo ratings yet
- SAP HR - Legacy System Migration Workbench (LSMW)Document5 pagesSAP HR - Legacy System Migration Workbench (LSMW)Bharathk KldNo ratings yet
- DOST-PHIVOLCS Presentation For The CRDRRMC Meeting 15jan2020Document36 pagesDOST-PHIVOLCS Presentation For The CRDRRMC Meeting 15jan2020RJay JacabanNo ratings yet
- Assessing The Marks and Spencers Retail ChainDocument10 pagesAssessing The Marks and Spencers Retail ChainHND Assignment Help100% (1)
- Yarn HairinessDocument9 pagesYarn HairinessGhandi AhmadNo ratings yet
- 3g Node B On Ip MediaDocument79 pages3g Node B On Ip MediaBsskkd KkdNo ratings yet
- Brochure GM Oat Technology 2017 enDocument8 pagesBrochure GM Oat Technology 2017 enArlette ReyesNo ratings yet
- Hydraulics and PneumaticsDocument6 pagesHydraulics and PneumaticsRyo TevezNo ratings yet
- Mother Tongue K To 12 Curriculum GuideDocument18 pagesMother Tongue K To 12 Curriculum GuideBlogWatch100% (5)
- Process Industry Practices Insulation: PIP INEG2000 Guidelines For Use of Insulation PracticesDocument15 pagesProcess Industry Practices Insulation: PIP INEG2000 Guidelines For Use of Insulation PracticesZubair RaoofNo ratings yet
- Annex To ED Decision 2013-015-RDocument18 pagesAnnex To ED Decision 2013-015-RBurse LeeNo ratings yet
- Advanced Java SlidesDocument134 pagesAdvanced Java SlidesDeepa SubramanyamNo ratings yet
- Steel Price Index PresentationDocument12 pagesSteel Price Index PresentationAnuj SinghNo ratings yet
- Fluoride - Wide Range of Serious Health Problems"Document29 pagesFluoride - Wide Range of Serious Health Problems"zataullah100% (2)
- Slides - SARSDocument191 pagesSlides - SARSCedric PoolNo ratings yet
- VC AndrewsDocument3 pagesVC AndrewsLesa O'Leary100% (1)
- The Beauty of Laplace's Equation, Mathematical Key To Everything - WIRED PDFDocument9 pagesThe Beauty of Laplace's Equation, Mathematical Key To Everything - WIRED PDFYan XiongNo ratings yet
- Evolis SDK Use Latest IomemDocument10 pagesEvolis SDK Use Latest IomempatrickNo ratings yet