You might also like
- ASPHALTDocument7 pagesASPHALTJessie Radaza TutorNo ratings yet
- Generational Differences in Acute Care NursesDocument13 pagesGenerational Differences in Acute Care NursesJessie Radaza TutorNo ratings yet
- TOEIC-style Error Recognition: 23130 Page 1 of 2Document2 pagesTOEIC-style Error Recognition: 23130 Page 1 of 2Jessie Radaza TutorNo ratings yet
- New Dicklumn Catchment Area Polygon 43 14.2203 27.9481: Name Shape Type of Points S) RS)Document3 pagesNew Dicklumn Catchment Area Polygon 43 14.2203 27.9481: Name Shape Type of Points S) RS)Jessie Radaza TutorNo ratings yet
- Structural Geometry and Load System AnalysisDocument3 pagesStructural Geometry and Load System AnalysisJesus Ray M. Mansayon100% (3)
- Palweb E-000-000000007793643 15aug2018 PDFDocument1 pagePalweb E-000-000000007793643 15aug2018 PDFJessie Radaza TutorNo ratings yet
- Palweb E-000-000000007793643 15aug2018 PDFDocument1 pagePalweb E-000-000000007793643 15aug2018 PDFJessie Radaza TutorNo ratings yet
- New Dicklumn Catchment Area DetailsDocument3 pagesNew Dicklumn Catchment Area DetailsJessie Radaza TutorNo ratings yet
- E-Ticket Itinerary/Receipt 12074713Document8 pagesE-Ticket Itinerary/Receipt 12074713Jessie Radaza Tutor100% (2)
- The Role of Public Service Values Program To Organizational Transformation - Dr. Ledesma Layon PDFDocument52 pagesThe Role of Public Service Values Program To Organizational Transformation - Dr. Ledesma Layon PDFJessie Radaza TutorNo ratings yet
- Balili River Polygon 177 56.5568 48.6741: Name Shape Type of Points S) RS)Document3 pagesBalili River Polygon 177 56.5568 48.6741: Name Shape Type of Points S) RS)Jessie Radaza TutorNo ratings yet
- Origin and Theoretical Basis of The New Public Management (NPM)Document35 pagesOrigin and Theoretical Basis of The New Public Management (NPM)Jessie Radaza TutorNo ratings yet
- Financial ManagementDocument9 pagesFinancial ManagementJessie Radaza TutorNo ratings yet
- Structural Analysis ExamDocument3 pagesStructural Analysis ExamJessie Radaza TutorNo ratings yet
- Deck SlabDocument22 pagesDeck SlabFarid TataNo ratings yet
- Table of ContentsDocument1 pageTable of ContentsJessie Radaza TutorNo ratings yet
- Engr. Jessie Radaza Tutor: Personal InformationDocument4 pagesEngr. Jessie Radaza Tutor: Personal InformationJessie Radaza TutorNo ratings yet
- Syllabus Public Management ReformsDocument3 pagesSyllabus Public Management ReformsJessie Radaza TutorNo ratings yet
- Easy Investment Program GuideDocument8 pagesEasy Investment Program GuideaprilbiluganNo ratings yet
- Philosophy of ManagementDocument3 pagesPhilosophy of ManagementJessie Radaza TutorNo ratings yet
- 31 Khaled KhederDocument15 pages31 Khaled KhederJessie Radaza TutorNo ratings yet
- BureaucracyDocument23 pagesBureaucracyAbdillah Abdul-rahmanNo ratings yet
- TP 144Document24 pagesTP 144Jessie Radaza Tutor0% (1)
- FlyerDocument2 pagesFlyerJessie Radaza TutorNo ratings yet
- JDS Math2013 SolutionDocument5 pagesJDS Math2013 SolutionJessie Radaza Tutor100% (3)
- REvised - Assignment of Topic Presentation For Quantitative Approaches in ManagementDocument1 pageREvised - Assignment of Topic Presentation For Quantitative Approaches in ManagementJessie Radaza TutorNo ratings yet
- TP 160Document30 pagesTP 160Jessie Radaza TutorNo ratings yet
- System Design ManagementDocument5 pagesSystem Design ManagementJessie Radaza TutorNo ratings yet
- Philippines Decentralisation RRLDocument12 pagesPhilippines Decentralisation RRLJessie Radaza TutorNo ratings yet
- Philippine Journal of Public AdministrationDocument18 pagesPhilippine Journal of Public AdministrationJessie Radaza Tutor0% (1)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5784)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (890)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (72)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- VB Script Coding ConventionsDocument11 pagesVB Script Coding ConventionsvinylscribdNo ratings yet
- Java AssignmentDocument5 pagesJava Assignmentsankulsybca50% (2)
- Mobile Security: A Report OnDocument13 pagesMobile Security: A Report OnMohammed HabeebNo ratings yet
- Eric Roberts Art Science Java PDFDocument2 pagesEric Roberts Art Science Java PDFEvanNo ratings yet
- Ccna1 ch7Document6 pagesCcna1 ch7Vali IlieNo ratings yet
- Fin ReportDocument19 pagesFin ReportSoulanki KunduNo ratings yet
- 10-Interactive Reporting in SAP ABAPDocument34 pages10-Interactive Reporting in SAP ABAPKIRAN100% (1)
- Toward Generating A New Intrusion Detection Dataset and Intrusion Traffic CharacterizationDocument9 pagesToward Generating A New Intrusion Detection Dataset and Intrusion Traffic Characterizationandres pythonNo ratings yet
- VZ01 - LAB - FactoryTalk View Machine Edition and PanelView Plus - Introductory ROKTechED 2015 PDFDocument126 pagesVZ01 - LAB - FactoryTalk View Machine Edition and PanelView Plus - Introductory ROKTechED 2015 PDFPedroNo ratings yet
- 1 Introduction To MineSight 2012Document48 pages1 Introduction To MineSight 2012xxmisterioxxNo ratings yet
- 1333228531.0442unit 4Document19 pages1333228531.0442unit 4RolandDanangWijaya0% (1)
- Netdata Debian LinuxDocument52 pagesNetdata Debian LinuxWalid UmarNo ratings yet
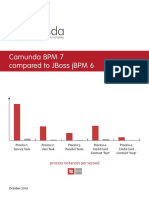
- 477 - Camunda BPM 7 Com Pared To JBossDocument17 pages477 - Camunda BPM 7 Com Pared To JBossManojBhangaleNo ratings yet
- Review: Detection & Diagnosis of Plant Leaf Disease Using Integrated Image Processing ApproachDocument17 pagesReview: Detection & Diagnosis of Plant Leaf Disease Using Integrated Image Processing ApproachdanangkitaNo ratings yet
- Banking Management System ReportDocument79 pagesBanking Management System ReportShweta SinghNo ratings yet
- Abap Real Time Interview QuestionsDocument98 pagesAbap Real Time Interview QuestionsNagesh reddyNo ratings yet
- 2-BCA 10 Lecture 2 - Computer ConceptsDocument36 pages2-BCA 10 Lecture 2 - Computer ConceptsHannah VillanuevaNo ratings yet
- HP Commercial Notebook DMI Programming - Dec2014Document9 pagesHP Commercial Notebook DMI Programming - Dec2014David Contreras EspejoNo ratings yet
- Make Up MidtermDocument6 pagesMake Up MidtermArgent MetaliajNo ratings yet
- Loops Algorithms Flowcharts ProblemsDocument20 pagesLoops Algorithms Flowcharts ProblemsAyaz AhmedNo ratings yet
- (PPT) DFT DTFS and Transforms (Stanford)Document13 pages(PPT) DFT DTFS and Transforms (Stanford)Wesley GeorgeNo ratings yet
- Combinatorics and Graph Theory With Mathematica: Steven SkienaDocument31 pagesCombinatorics and Graph Theory With Mathematica: Steven SkienaPrateekNo ratings yet
- IorcDocument15 pagesIorcSushma K RaoNo ratings yet
- Pillar Gridding in PETRELDocument14 pagesPillar Gridding in PETRELHenry Reynolds DarcyNo ratings yet
- Hadoop and BigData LAB MANUALDocument59 pagesHadoop and BigData LAB MANUALharshi33% (3)
- Automated Installation With Kiskstart PDFDocument3 pagesAutomated Installation With Kiskstart PDFharshalwarke1991No ratings yet
- ELX304 Topic1 Lesson 1 Pr2Document22 pagesELX304 Topic1 Lesson 1 Pr2Mahesvaran SubramaniamNo ratings yet
- SNMP TroubleshootingDocument20 pagesSNMP TroubleshootingIshmeet Singh100% (1)
- ISO 9001 CM ProcedureDocument9 pagesISO 9001 CM ProcedureElías A Pérez RíosNo ratings yet
- Geo LibsDocument5 pagesGeo Libsrenish_mehtaNo ratings yet