You might also like
- A Mild Method For Regioselective Labeling of Aromatics With Radioactive IodineDocument4 pagesA Mild Method For Regioselective Labeling of Aromatics With Radioactive IodineVida Faith GalvezNo ratings yet
- Total Synthesis of SwaisonineDocument7 pagesTotal Synthesis of SwaisonineVida Faith GalvezNo ratings yet
- Two Perspectives on Using 3D QSAR and Docking to Predict Biological ActivityDocument6 pagesTwo Perspectives on Using 3D QSAR and Docking to Predict Biological ActivityVida Faith GalvezNo ratings yet
- Estructura de La SteviaDocument9 pagesEstructura de La SteviaReinaldo Calderon SupelanoNo ratings yet
- Does Electron Capture Dissociation Cleave Protein Disulfide BondsDocument9 pagesDoes Electron Capture Dissociation Cleave Protein Disulfide BondsVida Faith GalvezNo ratings yet
- Ruthenium-Catalyzed Intramolecular (2+2+2) Cycloaddition and Tandem Cross-Metathesis of Triynes and EnediynesDocument85 pagesRuthenium-Catalyzed Intramolecular (2+2+2) Cycloaddition and Tandem Cross-Metathesis of Triynes and EnediynesVida Faith GalvezNo ratings yet
- Platform For Specific Delivery of Lanthanide-Scandium Mixed-Metal Cluster Fullerenes Into Target CellsDocument4 pagesPlatform For Specific Delivery of Lanthanide-Scandium Mixed-Metal Cluster Fullerenes Into Target CellsVida Faith GalvezNo ratings yet
- Low Entanglement WavefunctionsDocument14 pagesLow Entanglement WavefunctionsVida Faith GalvezNo ratings yet
- Review of HPLC Methods & HPLC-MS Detection For Direct Determination of Aspirin With Its Metabolites in Biological MatricesDocument36 pagesReview of HPLC Methods & HPLC-MS Detection For Direct Determination of Aspirin With Its Metabolites in Biological MatricesVida Faith Galvez0% (1)
- A Novel Active Bionanocomposite Film Incorporating Rosemary Essential Oil & Nanoclay Into ChitosanDocument8 pagesA Novel Active Bionanocomposite Film Incorporating Rosemary Essential Oil & Nanoclay Into ChitosanVida Faith GalvezNo ratings yet
- CO2 Adsorption in Betulin-Based Micro - and Macroporous PolyurethanesDocument5 pagesCO2 Adsorption in Betulin-Based Micro - and Macroporous PolyurethanesVida Faith GalvezNo ratings yet
- Antibody-Capped Mesoporous Nanoscopic Materials-Design of Probe For Finasteride Detection Supplementary InformationDocument3 pagesAntibody-Capped Mesoporous Nanoscopic Materials-Design of Probe For Finasteride Detection Supplementary InformationVida Faith GalvezNo ratings yet
- A Novel Active Bionanocomposite Film Incorporating Rosemary Essential Oil & Nanoclay Into ChitosanDocument8 pagesA Novel Active Bionanocomposite Film Incorporating Rosemary Essential Oil & Nanoclay Into ChitosanVida Faith GalvezNo ratings yet
- Embedded Palladium Activation As A Facile Method For TiO2-Nanotube Nanoparticle Decoration - Cu2O-Induced Visible-Light PhotoactivityDocument5 pagesEmbedded Palladium Activation As A Facile Method For TiO2-Nanotube Nanoparticle Decoration - Cu2O-Induced Visible-Light PhotoactivityVida Faith GalvezNo ratings yet
- Metal-Conugated Affinity Labels - A New Concept To Create Enantioselective Artificial MetalloenzymesDocument6 pagesMetal-Conugated Affinity Labels - A New Concept To Create Enantioselective Artificial MetalloenzymesVida Faith GalvezNo ratings yet
- Synthesis of π-Extended Coumarins and Evaluation of Their Precursors as Reactive Fluorescent Probes for Hg Ions Supplementary materialDocument5 pagesSynthesis of π-Extended Coumarins and Evaluation of Their Precursors as Reactive Fluorescent Probes for Hg Ions Supplementary materialVida Faith GalvezNo ratings yet
- Organic Chemistry - Another Ace in The PackDocument2 pagesOrganic Chemistry - Another Ace in The PackVida Faith GalvezNo ratings yet
- Tripyridyltruxenes-Thermally Stable Cathode Buffer Materials For Organic Thin-Film Solar Cells Supplementary InformationDocument12 pagesTripyridyltruxenes-Thermally Stable Cathode Buffer Materials For Organic Thin-Film Solar Cells Supplementary InformationVida Faith GalvezNo ratings yet
- Syn of π-Extended Coumarins and Evaluation of Their Precursors as Reactive Fluorescent Probes for Hg IonsDocument17 pagesSyn of π-Extended Coumarins and Evaluation of Their Precursors as Reactive Fluorescent Probes for Hg IonsVida Faith GalvezNo ratings yet
- Development and Application of A Database of Food Ingredient Fraud and Economically Motivated Adulteration From 1980 To 2010Document9 pagesDevelopment and Application of A Database of Food Ingredient Fraud and Economically Motivated Adulteration From 1980 To 2010Vida Faith GalvezNo ratings yet
- Using Food Science Demonstrations To Engage Students of All Ages in Science, Technology, Engineering, and Math (STEM)Document7 pagesUsing Food Science Demonstrations To Engage Students of All Ages in Science, Technology, Engineering, and Math (STEM)Vida Faith GalvezNo ratings yet
- Synthetic BiologyDocument64 pagesSynthetic Biologysmarsenik100% (2)
- Natural Products in Drug DiscoveryDocument8 pagesNatural Products in Drug DiscoveryartemisinNo ratings yet
- TLC For The Testing of Avermectins Produced by S.avermitdis StrainsDocument4 pagesTLC For The Testing of Avermectins Produced by S.avermitdis StrainsVida Faith GalvezNo ratings yet
- A Complex Multienz Sys Encoded by 5 PKS Genes Is Involved in The Biosyn of 26-Membered Polyene Macrolide Pimaricin in S.natalensisDocument11 pagesA Complex Multienz Sys Encoded by 5 PKS Genes Is Involved in The Biosyn of 26-Membered Polyene Macrolide Pimaricin in S.natalensisVida Faith GalvezNo ratings yet
- Biomimetic Chemistry and Synthetic Biology-A Two-Way Traffic Across The BordersDocument16 pagesBiomimetic Chemistry and Synthetic Biology-A Two-Way Traffic Across The BordersVida Faith GalvezNo ratings yet
- From Vesicles Self-Reproduction To Semi-Synthetic Minimal CellsDocument7 pagesFrom Vesicles Self-Reproduction To Semi-Synthetic Minimal CellsVida Faith GalvezNo ratings yet
- Transgenic Plants For Insect ResistanceDocument11 pagesTransgenic Plants For Insect ResistanceVida Faith GalvezNo ratings yet
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5783)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (890)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (72)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- ChE 4110 Process Control HW 1Document6 pagesChE 4110 Process Control HW 1MalloryNo ratings yet
- Monster c4 Thread Text - Edited (Way Long) Version2 - Ford Muscle Cars Tech ForumDocument19 pagesMonster c4 Thread Text - Edited (Way Long) Version2 - Ford Muscle Cars Tech Forumjohn larsonNo ratings yet
- Particle: Conceptual PropertiesDocument5 pagesParticle: Conceptual PropertieskirolosseNo ratings yet
- Science 7 Module1Document22 pagesScience 7 Module1Hector Panti0% (1)
- Breadth First Search (BFS) Depth First Search (DFS) A-Star Search (A ) Minimax Algorithm Alpha-Beta PruningDocument31 pagesBreadth First Search (BFS) Depth First Search (DFS) A-Star Search (A ) Minimax Algorithm Alpha-Beta Pruninglevecem778No ratings yet
- VNL-Essar Field Trial: Nairobi-KenyaDocument13 pagesVNL-Essar Field Trial: Nairobi-Kenyapoppy tooNo ratings yet
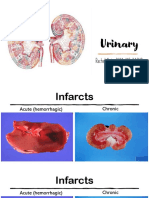
- Urinary: Rachel Neto, DVM, MS, DACVP May 28 2020Document15 pagesUrinary: Rachel Neto, DVM, MS, DACVP May 28 2020Rachel AutranNo ratings yet
- List of Steel Products Made in The UK PDFDocument120 pagesList of Steel Products Made in The UK PDFAntonio MarrufoNo ratings yet
- Appeal Tax Procedure (Malaysia)Document2 pagesAppeal Tax Procedure (Malaysia)Zati TyNo ratings yet
- Medical ParasitologyDocument33 pagesMedical ParasitologyAlexander Luie Jhames SaritaNo ratings yet
- Admission Form BA BSC Composite PDFDocument6 pagesAdmission Form BA BSC Composite PDFKhurram ShahzadNo ratings yet
- TMP 841704 RL 2023-03-13 Relieving LetterDocument1 pageTMP 841704 RL 2023-03-13 Relieving Letterxop0887No ratings yet
- MicroProcessadores ZelenovskyDocument186 pagesMicroProcessadores ZelenovskyDavid SantosNo ratings yet
- Lecture 8 - Life Cycle Inventory Example and SimaPro Intro - S18Document42 pagesLecture 8 - Life Cycle Inventory Example and SimaPro Intro - S18Francisco AraujoNo ratings yet
- GCAF Online Inspector Practice ExamDocument5 pagesGCAF Online Inspector Practice Examcamwills2100% (1)
- User'S Manual: 1 - Installation 2 - Technical SpecificationsDocument8 pagesUser'S Manual: 1 - Installation 2 - Technical SpecificationsGopal HegdeNo ratings yet
- Neem Oil Insect Repellent FormulationDocument12 pagesNeem Oil Insect Repellent FormulationnityaNo ratings yet
- BSC6900 UMTS Hardware Description (V900R017C10 - 01) (PDF) - enDocument224 pagesBSC6900 UMTS Hardware Description (V900R017C10 - 01) (PDF) - enmike014723050% (2)
- rfg040208 PDFDocument2,372 pagesrfg040208 PDFMr DungNo ratings yet
- Ye Zindagi Aur Mujhe Fanaa KardeDocument9 pagesYe Zindagi Aur Mujhe Fanaa Kardeankur9359saxenaNo ratings yet
- Callon & Law (1997) - After The Individual in Society. Lessons On Colectivity From Science, Technology and SocietyDocument19 pagesCallon & Law (1997) - After The Individual in Society. Lessons On Colectivity From Science, Technology and Societysashadam815812No ratings yet
- Bleed Fan SelectionDocument4 pagesBleed Fan Selectionomar abdullahNo ratings yet
- Game Informer September 2013Document104 pagesGame Informer September 2013Igor IvkovićNo ratings yet
- 28 GHZ Millimeter Wave Cellular Communication Measurements For Reflection and Penetration Loss in and Around Buildings in New York CityDocument5 pages28 GHZ Millimeter Wave Cellular Communication Measurements For Reflection and Penetration Loss in and Around Buildings in New York CityJunyi LiNo ratings yet
- PCM320 IDM320 NIM220 PMM310 Base Release Notes 1210Document48 pagesPCM320 IDM320 NIM220 PMM310 Base Release Notes 1210Eduardo Lecaros CabelloNo ratings yet
- Si New Functions 3 1 eDocument152 pagesSi New Functions 3 1 ecmm5477No ratings yet
- The Muscle and Strength Training Pyramid v2.0 Training by Eric Helms-9Document31 pagesThe Muscle and Strength Training Pyramid v2.0 Training by Eric Helms-9Hamada MansourNo ratings yet
- Effective Postoperative Pain Management StrategiesDocument10 pagesEffective Postoperative Pain Management StrategiesvenkayammaNo ratings yet
- Assessment Nursing Diagnosis Scientific Rationale Planning Intervention Rationale EvaluationDocument9 pagesAssessment Nursing Diagnosis Scientific Rationale Planning Intervention Rationale Evaluationclydell joyce masiarNo ratings yet