You might also like
- Advertising and Sales PromotionDocument75 pagesAdvertising and Sales PromotionGuruKPO100% (3)
- Think Tank - Advertising & Sales PromotionDocument75 pagesThink Tank - Advertising & Sales PromotionGuruKPO67% (3)
- ECON1202 Quantitative Analysis Course OutlineDocument17 pagesECON1202 Quantitative Analysis Course Outline1234x3No ratings yet
- E.R. Hooton, Tom Cooper - Desert Storm - Volume 2 - Operation Desert Storm and The Coalition Liberation of Kuwait 1991 (Middle East@War) (2021, Helion and CompanyDocument82 pagesE.R. Hooton, Tom Cooper - Desert Storm - Volume 2 - Operation Desert Storm and The Coalition Liberation of Kuwait 1991 (Middle East@War) (2021, Helion and Companydubie dubs100% (5)
- Statistical Techniques in Business and Economics 15edition CHPT 2Document15 pagesStatistical Techniques in Business and Economics 15edition CHPT 2kryptoniteguamNo ratings yet
- Econometrics PDFDocument2 pagesEconometrics PDFFaculty of Business and Economics, Monash UniversityNo ratings yet
- Applied ElectronicsDocument37 pagesApplied ElectronicsGuruKPO100% (2)
- Banking Services OperationsDocument134 pagesBanking Services OperationsGuruKPONo ratings yet
- Production and Material ManagementDocument50 pagesProduction and Material ManagementGuruKPONo ratings yet
- Graphical and Tabular Descriptive TechniquesDocument40 pagesGraphical and Tabular Descriptive TechniquesJpagNo ratings yet
- Project On SamsungDocument39 pagesProject On SamsungAbbas0% (1)
- Statistical MethodsDocument109 pagesStatistical MethodsGuruKPO90% (10)
- It Research Project 1: I. Course DescriptionDocument5 pagesIt Research Project 1: I. Course DescriptionTina CoNo ratings yet
- Calculus SE FMDocument13 pagesCalculus SE FMluckyguy1100% (1)
- Computer Graphics & Image ProcessingDocument117 pagesComputer Graphics & Image ProcessingGuruKPONo ratings yet
- Quantitative Techniques in BusinessDocument36 pagesQuantitative Techniques in Businesstalha mudassirNo ratings yet
- Product and Brand ManagementDocument129 pagesProduct and Brand ManagementGuruKPONo ratings yet
- Inferential Stats Module: Hypothesis Testing, P-Values ExplainedDocument25 pagesInferential Stats Module: Hypothesis Testing, P-Values ExplainedQueency DangilanNo ratings yet
- ECONOMICS STATISTICS MODULE OVERVIEWDocument58 pagesECONOMICS STATISTICS MODULE OVERVIEWKintu GeraldNo ratings yet
- Econometrics EnglishDocument62 pagesEconometrics EnglishATHANASIA MASOURANo ratings yet
- Biyani's Think Tank: Concept Based NotesDocument49 pagesBiyani's Think Tank: Concept Based NotesGuruKPO71% (7)
- Elementary Practical StatisticsDocument440 pagesElementary Practical Statisticsmbfreesdb67% (3)
- Data Science Machine LearningDocument15 pagesData Science Machine LearningmagrinraphaelNo ratings yet
- Stats Xi All Chapters PptsDocument2,046 pagesStats Xi All Chapters PptsAnadi AgarwalNo ratings yet
- Paper 19 Revised PDFDocument520 pagesPaper 19 Revised PDFAmey Mehta100% (1)
- Business StatisticsDocument110 pagesBusiness StatisticsManoj100% (1)
- Abstract AlgebraDocument111 pagesAbstract AlgebraGuruKPO100% (5)
- Why Learn Statistics for Business DecisionsDocument17 pagesWhy Learn Statistics for Business DecisionsnrsiddiquiNo ratings yet
- Florida International University: Course Syllabus Application of Quantitative Methods in Business QMB3200-RVAA-RPC-1125Document10 pagesFlorida International University: Course Syllabus Application of Quantitative Methods in Business QMB3200-RVAA-RPC-1125Lisa VegasNo ratings yet
- 2003 Makipaa 1Document15 pages2003 Makipaa 1faizal rizkiNo ratings yet
- Cost & Asset Accounting: Prof - Dr.G.M.MamoorDocument51 pagesCost & Asset Accounting: Prof - Dr.G.M.MamoorPIRZADA TALHA ISMAIL100% (1)
- Business Research MethodsDocument62 pagesBusiness Research MethodsSourav KaranthNo ratings yet
- Statistical Amity Directorate of Distance & Methods Online EducationDocument227 pagesStatistical Amity Directorate of Distance & Methods Online EducationAbhyudaya MandalNo ratings yet
- How To Use Log TableDocument2 pagesHow To Use Log TableArun M. PatokarNo ratings yet
- Chapter 1 Quantitative AnalysisDocument16 pagesChapter 1 Quantitative AnalysisMinase TilayeNo ratings yet
- Ugc Net Gradeup Playlist ListDocument3 pagesUgc Net Gradeup Playlist ListDaffodilNo ratings yet
- Cost Analysis Format-Exhaust DyeingDocument1 pageCost Analysis Format-Exhaust DyeingRezaul Karim TutulNo ratings yet
- Instrumental Variable: Statistics Econometrics EpidemiologyDocument5 pagesInstrumental Variable: Statistics Econometrics EpidemiologyJude Agnello AlexNo ratings yet
- Service MarketingDocument60 pagesService MarketingGuruKPONo ratings yet
- Data Communication & NetworkingDocument138 pagesData Communication & NetworkingGuruKPO75% (4)
- Chapter 4 - PRODUCT PRICINGDocument61 pagesChapter 4 - PRODUCT PRICINGMatt Russell Yuson100% (1)
- Business Statistics Module - 1 Introduction-Meaning, Definition, Functions, Objectives and Importance of StatisticsDocument5 pagesBusiness Statistics Module - 1 Introduction-Meaning, Definition, Functions, Objectives and Importance of StatisticsPnx RageNo ratings yet
- Lecture 1 ECN 2331 (Scope of Statistical Methods For Economic Analysis) - 1Document15 pagesLecture 1 ECN 2331 (Scope of Statistical Methods For Economic Analysis) - 1sekelanilunguNo ratings yet
- Stac101 PDFDocument91 pagesStac101 PDFShanmukh SagarNo ratings yet
- Economics Specification A Level EdexcelDocument95 pagesEconomics Specification A Level EdexcelSameer MurphyNo ratings yet
- Pavan CIS8008 Ass3Document23 pagesPavan CIS8008 Ass3Vishwanath TinkuNo ratings yet
- Advanced Econometrics Intro CLRM PDFDocument46 pagesAdvanced Econometrics Intro CLRM PDFMarzieh RostamiNo ratings yet
- MST-002 - Descriptive StatisticsDocument267 pagesMST-002 - Descriptive StatisticsmukulNo ratings yet
- Dmba103 Statistics For ManagementDocument7 pagesDmba103 Statistics For ManagementShashi SainiNo ratings yet
- Day18 - Correlation and RegressionDocument56 pagesDay18 - Correlation and Regressionsubi5No ratings yet
- Print Official StatisticsDocument21 pagesPrint Official StatisticsSuman RajibNo ratings yet
- Bowerman Regression CHPT 1Document18 pagesBowerman Regression CHPT 1CharleneKronstedt100% (1)
- B.SC Statistics PDFDocument16 pagesB.SC Statistics PDFsrinivasprashantNo ratings yet
- Research Methods Bibliographic ListDocument4 pagesResearch Methods Bibliographic ListMihaela MădăranNo ratings yet
- Foundations of Quantitative MethodsDocument160 pagesFoundations of Quantitative MethodsHIMANSHU PATHAKNo ratings yet
- The Business Landscape For MSMEs and Large Enterprises in Zambia - ZBS July 2010Document78 pagesThe Business Landscape For MSMEs and Large Enterprises in Zambia - ZBS July 2010Chola MukangaNo ratings yet
- FALL 2012 - PSYC305 - Statistics For Experimental Design - SyllabusDocument4 pagesFALL 2012 - PSYC305 - Statistics For Experimental Design - SyllabuscreativelyinspiredNo ratings yet
- Chapter 2 Evolution of Management ThoughtsDocument15 pagesChapter 2 Evolution of Management ThoughtsDagm alemayehuNo ratings yet
- 1 Statistics PDFDocument40 pages1 Statistics PDFHue HueNo ratings yet
- Exploratory and Confirmatory Factor Analysis PDFDocument2 pagesExploratory and Confirmatory Factor Analysis PDFRobNo ratings yet
- Capital Statement: Tax InvestigationDocument23 pagesCapital Statement: Tax Investigation--bolabolaNo ratings yet
- Bowerman CH15 APPT FinalDocument38 pagesBowerman CH15 APPT FinalMuktesh Singh100% (1)
- 1.2. Mathematical Language and SymbolsDocument44 pages1.2. Mathematical Language and SymbolsJhayzelle Anne RoperezNo ratings yet
- Recent Advances in Statistics: Papers in Honor of Herman Chernoff on His Sixtieth BirthdayFrom EverandRecent Advances in Statistics: Papers in Honor of Herman Chernoff on His Sixtieth BirthdayM. Haseeb RizviNo ratings yet
- Stages of Public PolicyDocument1 pageStages of Public PolicySuniel ChhetriNo ratings yet
- ACCOUNTING Schaum's Outline of Theory and Problems of Managerial AccountingDocument8 pagesACCOUNTING Schaum's Outline of Theory and Problems of Managerial Accountingtanmaybeckham08No ratings yet
- Quantitative Techniques - WWW - Ifrsiseasy.com - NG PDFDocument561 pagesQuantitative Techniques - WWW - Ifrsiseasy.com - NG PDFAromasodun Omobolanle IswatNo ratings yet
- Strategic Management Accounting PDFDocument5 pagesStrategic Management Accounting PDFMuhammad SadiqNo ratings yet
- Undergraduate EconometricDocument15 pagesUndergraduate EconometricAcho JieNo ratings yet
- Advanced Econometrics - HEC LausanneDocument2 pagesAdvanced Econometrics - HEC LausanneRavi SharmaNo ratings yet
- Public Sector Reform MauritiusDocument2 pagesPublic Sector Reform MauritiusDeva ArmoogumNo ratings yet
- Event Study MethodDocument21 pagesEvent Study Methodvms8181No ratings yet
- FR2202 Financial EconometricsDocument3 pagesFR2202 Financial Econometricscarwasher1No ratings yet
- OptimizationDocument96 pagesOptimizationGuruKPO67% (3)
- Applied ElectronicsDocument40 pagesApplied ElectronicsGuruKPO75% (4)
- Algorithms and Application ProgrammingDocument114 pagesAlgorithms and Application ProgrammingGuruKPONo ratings yet
- Algorithms and Application ProgrammingDocument114 pagesAlgorithms and Application ProgrammingGuruKPONo ratings yet
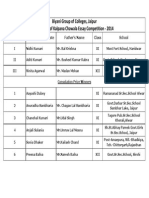
- Biyani Group of Colleges, Jaipur Merit List of Kalpana Chawala Essay Competition - 2014Document1 pageBiyani Group of Colleges, Jaipur Merit List of Kalpana Chawala Essay Competition - 2014GuruKPONo ratings yet
- Fundamental of Nursing Nov 2013Document1 pageFundamental of Nursing Nov 2013GuruKPONo ratings yet
- Phychology & Sociology Jan 2013Document1 pagePhychology & Sociology Jan 2013GuruKPONo ratings yet
- Paediatric Nursing Sep 2013 PDFDocument1 pagePaediatric Nursing Sep 2013 PDFGuruKPONo ratings yet
- Phychology & Sociology Jan 2013Document1 pagePhychology & Sociology Jan 2013GuruKPONo ratings yet
- Biological Science Paper I July 2013Document1 pageBiological Science Paper I July 2013GuruKPONo ratings yet
- Community Health Nursing I Nov 2013Document1 pageCommunity Health Nursing I Nov 2013GuruKPONo ratings yet
- Community Health Nursing Jan 2013Document1 pageCommunity Health Nursing Jan 2013GuruKPONo ratings yet
- Business Ethics and EthosDocument36 pagesBusiness Ethics and EthosGuruKPO100% (3)
- Community Health Nursing I July 2013Document1 pageCommunity Health Nursing I July 2013GuruKPONo ratings yet
- Biological Science Paper 1 Nov 2013Document1 pageBiological Science Paper 1 Nov 2013GuruKPONo ratings yet
- Business LawDocument112 pagesBusiness LawDewanFoysalHaqueNo ratings yet
- Biological Science Paper 1 Jan 2013Document1 pageBiological Science Paper 1 Jan 2013GuruKPONo ratings yet
- BA II English (Paper II)Document45 pagesBA II English (Paper II)GuruKPONo ratings yet
- Software Project ManagementDocument41 pagesSoftware Project ManagementGuruKPO100% (1)
- Training Prospectus 2020 WebDocument89 pagesTraining Prospectus 2020 Webamila_vithanageNo ratings yet
- 2 Security For CostsDocument1 page2 Security For CostsAnonymous Azxx3Kp9100% (1)
- Tabel Condenstatori SMDDocument109 pagesTabel Condenstatori SMDAllYn090888No ratings yet
- An - APX18 206516L CT0Document2 pagesAn - APX18 206516L CT0Maria MartinsNo ratings yet
- Gray Cast Iron Stress ReliefDocument25 pagesGray Cast Iron Stress ReliefSagarKBLNo ratings yet
- Case Study ON: The Spark Batteries LTDDocument8 pagesCase Study ON: The Spark Batteries LTDRitam chaturvediNo ratings yet
- E. Market Size PotentialDocument4 pagesE. Market Size Potentialmesadaeterjohn.studentNo ratings yet
- Green Ecobuses Run On This Route.: BusesDocument6 pagesGreen Ecobuses Run On This Route.: BusesLuis DíazNo ratings yet
- MATLAB code for Mann–Kendall test and Sen's slope estimationDocument7 pagesMATLAB code for Mann–Kendall test and Sen's slope estimationTubaiNandiNo ratings yet
- Bridge Ogres Little Fishes2Document18 pagesBridge Ogres Little Fishes2api-246705433No ratings yet
- Grate Inlet Skimmer Box ™ (GISB™ ) Suntree Technologies Service ManualDocument4 pagesGrate Inlet Skimmer Box ™ (GISB™ ) Suntree Technologies Service ManualOmar Rodriguez OrtizNo ratings yet
- FM Butterfly ValvesDocument3 pagesFM Butterfly ValvesahsanNo ratings yet
- Cs614-Mid Term Solved MCQs With References by Moaaz PDFDocument30 pagesCs614-Mid Term Solved MCQs With References by Moaaz PDFNiazi Qureshi AhmedNo ratings yet
- In Gov cbse-SSCER-191298202020 PDFDocument1 pageIn Gov cbse-SSCER-191298202020 PDFrishichauhan25No ratings yet
- 1st WeekDocument89 pages1st Weekbicky dasNo ratings yet
- AirtelDocument2 pagesAirtelShraddha RawatNo ratings yet
- Essential earthquake preparedness stepsDocument6 pagesEssential earthquake preparedness stepsRalphNacisNo ratings yet
- CPWD Contractor Enlistment Rules 2005 SummaryDocument71 pagesCPWD Contractor Enlistment Rules 2005 Summaryvikky717No ratings yet
- MU0017 Talent ManagementDocument12 pagesMU0017 Talent ManagementDr. Smita ChoudharyNo ratings yet
- Recognition & Derecognition 5Document27 pagesRecognition & Derecognition 5sajedulNo ratings yet
- Foreign Direct Investment in Mongolia An Interactive Case Study (USAID, 2007)Document266 pagesForeign Direct Investment in Mongolia An Interactive Case Study (USAID, 2007)Oyuna Bat-OchirNo ratings yet
- Tutorial: Energy Profiles ManagerDocument6 pagesTutorial: Energy Profiles ManagerDavid Yungan GonzalezNo ratings yet
- IPR GUIDE COVERS PATENTS, TRADEMARKS AND MOREDocument22 pagesIPR GUIDE COVERS PATENTS, TRADEMARKS AND MOREShaheen TajNo ratings yet
- Vaccination Management System of Brgy 6 (Table of Contents)Document8 pagesVaccination Management System of Brgy 6 (Table of Contents)Ryan Christian MenorNo ratings yet
- GPL 12800 (80) AhDocument1 pageGPL 12800 (80) AhismailNo ratings yet