You might also like
- Prezentare DMDocument4 pagesPrezentare DMAllexa CalotaNo ratings yet
- Prezent AreDocument2 pagesPrezent AreAllexa CalotaNo ratings yet
- Digital Electronics Lesson 5Document15 pagesDigital Electronics Lesson 5akdauatemNo ratings yet
- NPTEL Online Certification Courses Indian Institute of Technology KharagpurDocument4 pagesNPTEL Online Certification Courses Indian Institute of Technology KharagpurSURENDRAN D CS085No ratings yet
- Lecture Notes - SVMDocument13 pagesLecture Notes - SVMIndrajit Mitali PaulNo ratings yet
- Geog484-Williamss p3Document8 pagesGeog484-Williamss p3api-276783092No ratings yet
- Fuzzy C-Means Clustering Algorithm ExplainedDocument5 pagesFuzzy C-Means Clustering Algorithm ExplainedKarthikRam KvNo ratings yet
- JORDAAN2002 - Estimation of The Regularization Parameter For SVRDocument6 pagesJORDAAN2002 - Estimation of The Regularization Parameter For SVRAnonymous PsEz5kGVaeNo ratings yet
- Binary Decision DiagramsDocument8 pagesBinary Decision DiagramsMohammed MorsyNo ratings yet
- Multiplier Blocks Using Carry-Save Adders: Oscar Gustafsson, Andrew G. Dempster, and Lars WanhammarDocument4 pagesMultiplier Blocks Using Carry-Save Adders: Oscar Gustafsson, Andrew G. Dempster, and Lars WanhammarMurali KrishnaNo ratings yet
- ML Assignment 3 SolutionsDocument8 pagesML Assignment 3 SolutionsThrilling MeherabNo ratings yet
- R Lab 1Document5 pagesR Lab 1sdcphdworkNo ratings yet
- Iteration MethodsDocument12 pagesIteration Methodsfarouq_razzaz2574No ratings yet
- Lab3 Long ReportDocument21 pagesLab3 Long Reportalif fudenNo ratings yet
- Pontius Data Case StudyDocument9 pagesPontius Data Case StudyHarsh GuptaNo ratings yet
- Beyond Binary Classification: Handling Multi-Class, Regression, Unsupervised LearningDocument22 pagesBeyond Binary Classification: Handling Multi-Class, Regression, Unsupervised LearningChrsan RamNo ratings yet
- CS6011: Kernel Methods For Pattern Analysis: Submitted byDocument26 pagesCS6011: Kernel Methods For Pattern Analysis: Submitted byPawan GoyalNo ratings yet
- Pca PDFDocument10 pagesPca PDFSuraj Kumar DasNo ratings yet
- Support Vector Machine: Suraj Kumar DasDocument10 pagesSupport Vector Machine: Suraj Kumar DasSuraj Kumar DasNo ratings yet
- Fig. 1 The Process Yield HistogramDocument10 pagesFig. 1 The Process Yield HistogramALIKNFNo ratings yet
- MA 585: Time Series Analysis and Forecasting: February 12, 2017Document15 pagesMA 585: Time Series Analysis and Forecasting: February 12, 2017Patrick NamNo ratings yet
- Analyzing Time Domain ResponseDocument15 pagesAnalyzing Time Domain ResponseBasharat AslamNo ratings yet
- New Report of Music For The MassesDocument20 pagesNew Report of Music For The Massesneil stagNo ratings yet
- Bias Variance Ridge RegressionDocument4 pagesBias Variance Ridge RegressionSudheer RedusNo ratings yet
- Reservoir Characterisation 2012Document7 pagesReservoir Characterisation 2012T C0% (1)
- Name: Chinmay Tripurwar Roll No: 22b3902: Simple Regression Model AnalysisDocument9 pagesName: Chinmay Tripurwar Roll No: 22b3902: Simple Regression Model Analysissparee1256No ratings yet
- Scale Estimation and Keypoint Description: Li YichengDocument10 pagesScale Estimation and Keypoint Description: Li Yichengapi-303634380No ratings yet
- Sail Mast ReportDocument6 pagesSail Mast ReportMax KondrathNo ratings yet
- Best-Fit Curves: x+1 Is Zero When X 1. The Sine of X Is 1 When X IsDocument3 pagesBest-Fit Curves: x+1 Is Zero When X 1. The Sine of X Is 1 When X IsMilan DjordjevicNo ratings yet
- Tugas Ridho 2.100-2.102Document9 pagesTugas Ridho 2.100-2.102Feby MutiaNo ratings yet
- Project 2: Technical University of DenmarkDocument11 pagesProject 2: Technical University of DenmarkRiyaz AlamNo ratings yet
- CS5242 Neural Networks and Deep Learning: Quiz 1Document2 pagesCS5242 Neural Networks and Deep Learning: Quiz 1SsssNo ratings yet
- Minimum Degree Reordering Algorithms: A Tutorial: 1 Introduction: Cholesky Factorization and The Elimination GameDocument5 pagesMinimum Degree Reordering Algorithms: A Tutorial: 1 Introduction: Cholesky Factorization and The Elimination GamecsamoraNo ratings yet
- Linear Regression Operations AnalyticsDocument10 pagesLinear Regression Operations Analyticsyash mahindreNo ratings yet
- Report Batch 7Document9 pagesReport Batch 7NandhakumarNo ratings yet
- Chap 12Document120 pagesChap 12Phuc LxNo ratings yet
- Nonlinear regression analysis of data using a spreadsheetDocument2 pagesNonlinear regression analysis of data using a spreadsheetflgrhnNo ratings yet
- MATLAB Introduction: Learn Basic Commands & GraphingDocument18 pagesMATLAB Introduction: Learn Basic Commands & GraphingSajjadul IslamNo ratings yet
- House Prices Prediction in King CountyDocument10 pagesHouse Prices Prediction in King CountyJun ZhangNo ratings yet
- Lab 01: IT1005: Name: Lee Zhi Kang Matric No.: A0088205EDocument5 pagesLab 01: IT1005: Name: Lee Zhi Kang Matric No.: A0088205ELee Zhi KangNo ratings yet
- Chapter3 SolutionsDocument5 pagesChapter3 SolutionsAi Lian TanNo ratings yet
- Analysis For Power System State EstimationDocument9 pagesAnalysis For Power System State EstimationAnonymous TJRX7CNo ratings yet
- Report Project2Document25 pagesReport Project2Antonio RinaldiNo ratings yet
- From The Initial State, or As From The Moment of Preceding Calculation, One Calculates The Stress Field Resulting From An Increment of DeformationDocument10 pagesFrom The Initial State, or As From The Moment of Preceding Calculation, One Calculates The Stress Field Resulting From An Increment of DeformationTran TuyenNo ratings yet
- Unit 2Document10 pagesUnit 2Lakshmi Nandini MenteNo ratings yet
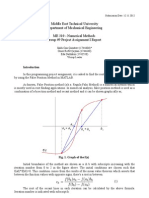
- Middle East Technical University Department of Mechanical Engineering ME 310 - Numerical Methods Group #9 Project Assignment I ReportDocument5 pagesMiddle East Technical University Department of Mechanical Engineering ME 310 - Numerical Methods Group #9 Project Assignment I Reportanon_33416438No ratings yet
- Aircraft Windshield Reliability Final PaperDocument12 pagesAircraft Windshield Reliability Final PaperAnonymous ffje1rpa100% (1)
- How to build linear regression models step-by-stepDocument5 pagesHow to build linear regression models step-by-stepAparna SinghNo ratings yet
- Rgreenfastermath gdc02Document22 pagesRgreenfastermath gdc02Liviu PeleșNo ratings yet
- Support Vector Machines - Hands-On Machine Learning With Scikit-Learn, Keras, and TensorFlow, 3rd EditionDocument17 pagesSupport Vector Machines - Hands-On Machine Learning With Scikit-Learn, Keras, and TensorFlow, 3rd Edition2001 HeyaDarjiNo ratings yet
- Easy13 RAIMDocument0 pagesEasy13 RAIMElpiedrasNo ratings yet
- Important QuestionsDocument18 pagesImportant Questionsshouryarastogi9760No ratings yet
- SVM Support Vector Machine: A Powerful Supervised Learning TechniqueDocument3 pagesSVM Support Vector Machine: A Powerful Supervised Learning TechniqueGarvit MehtaNo ratings yet
- Editing FunctionsDocument9 pagesEditing FunctionsLis LichuNo ratings yet
- Programming Exercise 3Document3 pagesProgramming Exercise 3Abhijit BhattacharyaNo ratings yet
- Lab # 8 Control SystemDocument10 pagesLab # 8 Control SystemZabeehullahmiakhailNo ratings yet
- Answers To Odd-Numbered Exercises: Chapter One An Overview of Regression AnalysisDocument20 pagesAnswers To Odd-Numbered Exercises: Chapter One An Overview of Regression Analysisadvent1312No ratings yet
- Lab Experiment 2Document5 pagesLab Experiment 2BerentoNo ratings yet
- BigdDocument97 pagesBigdANeek181No ratings yet
- SM Mass CommunicationDocument61 pagesSM Mass CommunicationpufuNo ratings yet
- Essay On English GrammarDocument1 pageEssay On English GrammarANeek181No ratings yet
- Cygwin InstallationDocument4 pagesCygwin InstallationANeek181No ratings yet
- Text Classification SlidesDocument88 pagesText Classification SlidesANeek181No ratings yet
- CELP Speech Coding ExplainedDocument23 pagesCELP Speech Coding ExplainedANeek181No ratings yet
- Speaker RecognitionDocument14 pagesSpeaker RecognitionblablablouNo ratings yet
- Onlinebook CollectionsDocument2,433 pagesOnlinebook CollectionsANeek181No ratings yet
- How My Laptop's Battery Converts Energy Sources into Electrical EnergyDocument1 pageHow My Laptop's Battery Converts Energy Sources into Electrical EnergyANeek181No ratings yet
- CC2530ZNP Mini Kit Quick Start GuideDocument2 pagesCC2530ZNP Mini Kit Quick Start GuideANeek181No ratings yet
- Cyclic CodeDocument43 pagesCyclic CodeANeek181No ratings yet
- PDFDocument47 pagesPDFRaquel D. MendietaNo ratings yet
- Document 2Document4 pagesDocument 2ANeek181No ratings yet
- GAT WordsDocument9 pagesGAT WordsANeek181No ratings yet
- SdsModified Cross-Correlation Back Projection For UWB Imaging: Numerical ExamplesDocument5 pagesSdsModified Cross-Correlation Back Projection For UWB Imaging: Numerical ExamplesANeek181No ratings yet
- TP 1Document1 pageTP 1ANeek181No ratings yet
- NEO-PI PersonalityDocument4 pagesNEO-PI PersonalityShivani Marathe100% (1)
- Intervention Week 2 Lesson PlanDocument8 pagesIntervention Week 2 Lesson Planapi-278474046100% (1)
- Meeting 4Document5 pagesMeeting 4K2AAditya NugrahaNo ratings yet
- Scale ConstructionDocument119 pagesScale ConstructionMayizNo ratings yet
- Tao Te ChingDocument36 pagesTao Te ChingLaerte83% (18)
- CompetitiveDocument15 pagesCompetitiveLaura HoreanuNo ratings yet
- Inductive and Deductive LessonDocument8 pagesInductive and Deductive LessonLisa BattistoneNo ratings yet
- HRM ReportDocument11 pagesHRM ReportAldrin Dalisay100% (1)
- QO Action Plan For SHS TVL TrackDocument2 pagesQO Action Plan For SHS TVL TrackEstacio B. Iraida Juna100% (2)
- Propaganda Techniques ExplainedDocument2 pagesPropaganda Techniques ExplainedRushdi Kho Tan50% (2)
- The Cornerstones of TestingDocument7 pagesThe Cornerstones of TestingOmar Khalid Shohag100% (3)
- Project Management Review (Midterm)Document10 pagesProject Management Review (Midterm)Melissa Nagy100% (2)
- Mayhem Magick Has Its Roots in Every Occult Tradition and in The Work of Lots of IndividualsDocument2 pagesMayhem Magick Has Its Roots in Every Occult Tradition and in The Work of Lots of Individualsfir6stevenNo ratings yet
- BIT303 Assignment 2 - Feb 2019 Semester PDFDocument3 pagesBIT303 Assignment 2 - Feb 2019 Semester PDFdnhzrdNo ratings yet
- Providing College Readiness Counselingfor Students With Autism Spectrum DisordersDocument11 pagesProviding College Readiness Counselingfor Students With Autism Spectrum Disordersapi-385677584No ratings yet
- Finance Supervisor or Administrative Assistant or Compliance AnaDocument3 pagesFinance Supervisor or Administrative Assistant or Compliance Anaapi-121835669No ratings yet
- ERQ Study Manuscript ACCEPTEDDocument30 pagesERQ Study Manuscript ACCEPTEDmarcelocarvalhoteacher2373No ratings yet
- Eng 101 - Autoethnography by ChangDocument25 pagesEng 101 - Autoethnography by ChangDevon ScheibertNo ratings yet
- Howtobea Great Consultant: Developer: Alex Wouterse Reviewers: Tony Ecock Steven Tallman John ClarkeDocument24 pagesHowtobea Great Consultant: Developer: Alex Wouterse Reviewers: Tony Ecock Steven Tallman John ClarkeKhishigbayar Purevdavga100% (1)
- Properties of Well-Written TextDocument24 pagesProperties of Well-Written TextKoole VirayNo ratings yet
- Highly Recommended Global Account Manager Seeking MBA For Career AdvancementDocument3 pagesHighly Recommended Global Account Manager Seeking MBA For Career AdvancementViola LamNo ratings yet
- Assessment 1 Written Project Proposal: Studysmarter Resources For Geng5511/12 Engineering Research ProjectDocument3 pagesAssessment 1 Written Project Proposal: Studysmarter Resources For Geng5511/12 Engineering Research ProjectNomen NescioNo ratings yet
- Orgnizations As Systems Meaning of Organization SystemsDocument7 pagesOrgnizations As Systems Meaning of Organization SystemsTash BloomNo ratings yet
- Statement of UnderatandingDocument1 pageStatement of Underatandingapi-249826975No ratings yet
- Swordtail Fish in AquariumDocument6 pagesSwordtail Fish in Aquariumamitdesai1508No ratings yet
- UNESCO Declaration on Education for Peace, Human Rights and DemocracyDocument14 pagesUNESCO Declaration on Education for Peace, Human Rights and DemocracyYugesh D PANDAYNo ratings yet
- (John Philip Jones) How Advertising Works The RolDocument372 pages(John Philip Jones) How Advertising Works The RolHubertus PanjiNo ratings yet
- Invisible Man CraDocument3 pagesInvisible Man Craapi-463313213No ratings yet
- Relationship Between University Students Time Management Skills and Their Academic PerformanceDocument6 pagesRelationship Between University Students Time Management Skills and Their Academic Performancemarriyam nadeemNo ratings yet
- Decision Wise Whitepaper 3 Essential Components of Employee EngagemenDocument8 pagesDecision Wise Whitepaper 3 Essential Components of Employee EngagemenRatna Srinivas Kosuri100% (1)