You might also like
- 6th Central Pay Commission Salary CalculatorDocument15 pages6th Central Pay Commission Salary Calculatorrakhonde100% (436)
- 6th Central Pay Commission Salary CalculatorDocument15 pages6th Central Pay Commission Salary Calculatorrakhonde100% (436)
- Data Warehouse ComponentsDocument18 pagesData Warehouse ComponentsMaja Kostic Ex SimicNo ratings yet
- Data ModelingDocument87 pagesData ModelingCrish NagarkarNo ratings yet
- INFORMATION MANAGEMENT Unit 3 NEWDocument61 pagesINFORMATION MANAGEMENT Unit 3 NEWThirumal Azhagan100% (1)
- Data Warehousing and Modeling ConceptsDocument37 pagesData Warehousing and Modeling Concepts1DT19CS032 Chethana T SNo ratings yet
- Data Quality ServicesDocument196 pagesData Quality ServicesrajbmohanNo ratings yet
- Rcs454: Python Language Programming LAB: Write A Python Program ToDocument39 pagesRcs454: Python Language Programming LAB: Write A Python Program ToShikha AryaNo ratings yet
- DataModel and Database Design StepsDocument35 pagesDataModel and Database Design Stepssamuel mechNo ratings yet
- Unit 2 Data Warehouse NewDocument45 pagesUnit 2 Data Warehouse NewSUMAN SHEKHARNo ratings yet
- Visual Data Mining: Concepts, Frameworks and Algorithm DevelopmentDocument30 pagesVisual Data Mining: Concepts, Frameworks and Algorithm Developmentanuj988guptaNo ratings yet
- CHP 19Document63 pagesCHP 19mona yadvNo ratings yet
- Lect#2 DDBS (Characteristics and Layers of Query Processing)Document20 pagesLect#2 DDBS (Characteristics and Layers of Query Processing)ridagul75% (8)
- RA27T1A35Document8 pagesRA27T1A35Nakul KumarNo ratings yet
- DWDMDocument5 pagesDWDMAnkit KumarNo ratings yet
- Advantages of ObjectDocument11 pagesAdvantages of ObjectAman KukarNo ratings yet
- Course: Object-Oriented Systems and Programming: 07B61CI241 (Theory) and 07B61CI801 (Lab)Document22 pagesCourse: Object-Oriented Systems and Programming: 07B61CI241 (Theory) and 07B61CI801 (Lab)Sanchit BatraNo ratings yet
- Cse 511Document7 pagesCse 511Ioana Raluca TiriacNo ratings yet
- Chapter 11 2 Applications and Trends in Data MiningDocument2 pagesChapter 11 2 Applications and Trends in Data MiningbharathimanianNo ratings yet
- Current TrendsDocument35 pagesCurrent TrendsicecoolbergeNo ratings yet
- Gujarat Technological University: Subject Name: Elective I - Data Warehousing & Data Mining (DWDM) Subject Code: 640005Document5 pagesGujarat Technological University: Subject Name: Elective I - Data Warehousing & Data Mining (DWDM) Subject Code: 640005kiran_y2No ratings yet
- DWM 3Document15 pagesDWM 3Shivraj JadhavNo ratings yet
- SSAS-Analysis Services Query Performance Top 10 Best PracticesDocument5 pagesSSAS-Analysis Services Query Performance Top 10 Best PracticesNag DhallNo ratings yet
- # Understanding DM Architecture, KDD & DM ToolsDocument29 pages# Understanding DM Architecture, KDD & DM ToolsDan MasangaNo ratings yet
- Data Mining Issues and KDD ProcessDocument10 pagesData Mining Issues and KDD ProcessShubham GuptaNo ratings yet
- For Chapter 3Document13 pagesFor Chapter 3abhi7219No ratings yet
- Data Mining: Instructor DR Dhani BuxDocument12 pagesData Mining: Instructor DR Dhani BuxShanza khursheedNo ratings yet
- WINSEM2023-24 BCSE302L TH CH2023240502444 Reference Material I 08-01-2024 MODULE 1Document165 pagesWINSEM2023-24 BCSE302L TH CH2023240502444 Reference Material I 08-01-2024 MODULE 1sarvesh.vitchennaiNo ratings yet
- L1 IntroductionDocument12 pagesL1 IntroductionKarthik LaxmikanthNo ratings yet
- Unit 3: by Dr. Anand VyasDocument20 pagesUnit 3: by Dr. Anand VyasPrince SinghNo ratings yet
- Chapter 1 Introduction To Databases and TransactionsDocument47 pagesChapter 1 Introduction To Databases and TransactionsRahul SinghNo ratings yet
- Chapter 2 and 3Document89 pagesChapter 2 and 3Harshad NawghareNo ratings yet
- Viva Questions For Data Mining and Warehousing: Q1. Ans.Document13 pagesViva Questions For Data Mining and Warehousing: Q1. Ans.Aditi JangidNo ratings yet
- DWDM Unit 2Document46 pagesDWDM Unit 2sri charanNo ratings yet
- Practical Tips To Improve Data Load Performance and EfficiencyDocument51 pagesPractical Tips To Improve Data Load Performance and EfficiencyJitendra JoshiNo ratings yet
- 06 - Physical Design in Data WarehouseDocument18 pages06 - Physical Design in Data WarehouseMase LikuNo ratings yet
- How Is Bigdata Handled in Kaggle?: 17Cp006-Leenanci Parmar 17CP012-DHRUVI LADDocument18 pagesHow Is Bigdata Handled in Kaggle?: 17Cp006-Leenanci Parmar 17CP012-DHRUVI LADDarshan TankNo ratings yet
- Introduction To Big Data-0Document77 pagesIntroduction To Big Data-0AbhishreeNo ratings yet
- Data Science PDFDocument11 pagesData Science PDFsredhar sNo ratings yet
- Authenticating and Reducing False Hits in MiningDocument37 pagesAuthenticating and Reducing False Hits in MiningUjwala BhogaNo ratings yet
- File Processing Systems: Billing Program Purchasing ProgramDocument29 pagesFile Processing Systems: Billing Program Purchasing ProgramRajesh KumarNo ratings yet
- File Processing Systems: Billing Program Purchasing ProgramDocument35 pagesFile Processing Systems: Billing Program Purchasing ProgramJan Reinhart PerezNo ratings yet
- 03 Etl 081028 2055Document46 pages03 Etl 081028 2055Mahesh SharmaNo ratings yet
- Maintenance: - Occurs When The System Is in Production - IncludesDocument25 pagesMaintenance: - Occurs When The System Is in Production - IncludesSachin KumarNo ratings yet
- ML Data Poison Detection Under 40Document22 pagesML Data Poison Detection Under 40Telu TejaswiniNo ratings yet
- Data Models: Hierarchical, Network & RelationalDocument27 pagesData Models: Hierarchical, Network & RelationalShobhita MahajanNo ratings yet
- University Institute of Computing: Master of Computer Applications (MCA)Document10 pagesUniversity Institute of Computing: Master of Computer Applications (MCA)Rohit DahiyaNo ratings yet
- Introduction To Data ScienceDocument11 pagesIntroduction To Data SciencepjmmagNo ratings yet
- Real Time Data Stream Processing EngineDocument13 pagesReal Time Data Stream Processing Engineakg_No ratings yet
- Lec 4Document12 pagesLec 4Rifky AhmedNo ratings yet
- Data Mining and Database Systems Where Is The IntersectionDocument5 pagesData Mining and Database Systems Where Is The Intersectionjorge051289No ratings yet
- 2.0 Database SystemDocument9 pages2.0 Database SystemNurazizah JasmanNo ratings yet
- Data Mining CatDocument6 pagesData Mining Catmwepaka ndackiaNo ratings yet
- Data Warehousing Prelim SummaryDocument129 pagesData Warehousing Prelim Summarycyka blyatNo ratings yet
- Introduction To Data MiningDocument29 pagesIntroduction To Data MiningBulmi HilmeNo ratings yet
- Data Mining and Database Systems: Where Is The Intersection?Document5 pagesData Mining and Database Systems: Where Is The Intersection?Juan KardNo ratings yet
- Veritabanı Yönetim Sistemleri YZM508: Dr. Osman GÖKALPDocument49 pagesVeritabanı Yönetim Sistemleri YZM508: Dr. Osman GÖKALPolcayto krocanNo ratings yet
- Ism Second ModuleDocument73 pagesIsm Second ModuleABOOBAKKERNo ratings yet
- A Study On Post Mining of Association Rules Targeting User InterestDocument7 pagesA Study On Post Mining of Association Rules Targeting User Interestsurendiran123No ratings yet
- DSA Unit1Document37 pagesDSA Unit1neha yarrapothuNo ratings yet
- Parallel Processing Topic OverviewDocument18 pagesParallel Processing Topic OverviewwmanjonjoNo ratings yet
- Data & Storage Structures: Introductions &Document17 pagesData & Storage Structures: Introductions &shivaniNo ratings yet
- Data Warehouse & Data MiningDocument41 pagesData Warehouse & Data MiningSyed MotashamNo ratings yet
- Install and Use Winki OSDocument17 pagesInstall and Use Winki OSJulio Omar Palacio NiñoNo ratings yet
- Lang AaDocument50 pagesLang AaAndrweAnayaNo ratings yet
- Explore SharePoint 2013Document81 pagesExplore SharePoint 2013Warren Franklin100% (1)
- Third Party AttributionsfgjghDocument11 pagesThird Party AttributionsfgjghMohammed NourNo ratings yet
- ReadmeDocument4 pagesReadmeJoe BleauNo ratings yet
- Log Gathering HelpDocument1 pageLog Gathering HelpJulio Omar Palacio NiñoNo ratings yet
- Log Gathering HelpDocument1 pageLog Gathering HelpJulio Omar Palacio NiñoNo ratings yet
- NewsDocument5 pagesNewsJulio Omar Palacio NiñoNo ratings yet
- ReadmeDocument4 pagesReadmeJulio Omar Palacio NiñoNo ratings yet
- VersionDocument1 pageVersionJulio Omar Palacio NiñoNo ratings yet
- JavaDocument1 pageJavaNajib AbdillahNo ratings yet
- VersionDocument1 pageVersionJulio Omar Palacio NiñoNo ratings yet
- VersionDocument1 pageVersionJulio Omar Palacio NiñoNo ratings yet
- JavaDocument1 pageJavaNajib AbdillahNo ratings yet
- JavaDocument1 pageJavaNajib AbdillahNo ratings yet
- FAQ How To Send Base64 Encoded Passwords v1.0Document5 pagesFAQ How To Send Base64 Encoded Passwords v1.0rachmat99No ratings yet
- RT 701 Object Oriented Modeling and Design - Module 4Document18 pagesRT 701 Object Oriented Modeling and Design - Module 4Lulu TojeenNo ratings yet
- Employee data queries and CRUD operationsDocument3 pagesEmployee data queries and CRUD operationsAya SalahNo ratings yet
- Flutter Tutorial 2Document6 pagesFlutter Tutorial 2Pedro GomezNo ratings yet
- Assign 1Document3 pagesAssign 1Tesfaye GemechuNo ratings yet
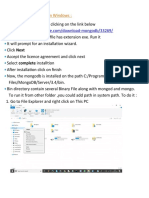
- How to Install MongoDB on Windows in 10 Easy StepsDocument20 pagesHow to Install MongoDB on Windows in 10 Easy Stepsvikas yadavNo ratings yet
- Lab Exercise - Array in JAVADocument8 pagesLab Exercise - Array in JAVASubaashini MohanasundaramNo ratings yet
- openFoamUserManual PFMDocument383 pagesopenFoamUserManual PFMHans JensenNo ratings yet
- Python Practicum Report IntroductionDocument9 pagesPython Practicum Report IntroductionIrfanNo ratings yet
- Python Crash CourseDocument2 pagesPython Crash Courseg25% (4)
- Practicals (CE-4 Batch-B4) Program OutputDocument26 pagesPracticals (CE-4 Batch-B4) Program OutputnooneNo ratings yet
- Homework 2Document12 pagesHomework 2Saidulu Kamineni0% (1)
- Beginners Guide To PLX DAQ v2 (Rev1)Document12 pagesBeginners Guide To PLX DAQ v2 (Rev1)miguel angelNo ratings yet
- MD5 and SHA 1Document6 pagesMD5 and SHA 1Syed SalmanNo ratings yet
- Friend functions and classes in CDocument24 pagesFriend functions and classes in CpoobharathiiNo ratings yet
- SQL Wildcards & Operators Lab TasksDocument10 pagesSQL Wildcards & Operators Lab Taskssaqib idreesNo ratings yet
- Ar TransactionsDocument6 pagesAr TransactionsreddyvijaykNo ratings yet
- PracticeDocument4 pagesPracticeAnoop ChauhanNo ratings yet
- Software Debugging Techniques: P. AdragnaDocument16 pagesSoftware Debugging Techniques: P. AdragnapavanaNo ratings yet
- Log Cat 1642657210498Document711 pagesLog Cat 1642657210498abishrantNo ratings yet
- Suraj KulkarniResumeDocument1 pageSuraj KulkarniResumesuraj kulkarniNo ratings yet
- Memory Allocation in C: Segments SegmentsDocument24 pagesMemory Allocation in C: Segments SegmentsSharaf AroniNo ratings yet
- CS 188: Artificial Intelligence: Constraint Satisfaction ProblemsDocument43 pagesCS 188: Artificial Intelligence: Constraint Satisfaction ProblemsSufi NoraniNo ratings yet
- A225521651 - 28838 - 11 - 2023 - Simulation QuestionsDocument4 pagesA225521651 - 28838 - 11 - 2023 - Simulation QuestionsAmit DansenaNo ratings yet
- DBMS Lab Midterm ReportDocument7 pagesDBMS Lab Midterm ReportAkshay HarishNo ratings yet
- SweetAlert2 JavaScript libraryDocument16 pagesSweetAlert2 JavaScript libraryPb Monyet1234No ratings yet
- English Work and How To Use ThemDocument209 pagesEnglish Work and How To Use ThemNguyenHongSangNo ratings yet
- JWT Authentication with Node.js - Generate and Verify TokensDocument4 pagesJWT Authentication with Node.js - Generate and Verify Tokensdriss nadhemNo ratings yet
- Rapid Web Development With Python/Django: Julian HillDocument37 pagesRapid Web Development With Python/Django: Julian Hilljppn33No ratings yet