You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- Facial Attractiveness: General Patterns of Facial PreferencesDocument36 pagesFacial Attractiveness: General Patterns of Facial PreferencesRahulsinghooooNo ratings yet
- S10 Container Registries SlidesDocument11 pagesS10 Container Registries SlidesWafa KhalidNo ratings yet
- 06 Logistic RegressionDocument16 pages06 Logistic RegressionRahulsinghooooNo ratings yet
- 3.3 Dameron 7-7-04Document42 pages3.3 Dameron 7-7-04RahulsinghooooNo ratings yet
- ZatubDocument3 pagesZatubRahulsinghooooNo ratings yet
- Data Scientist - NLP - Machine Learning Engineer: Rahul VK RMDocument2 pagesData Scientist - NLP - Machine Learning Engineer: Rahul VK RMRahulsinghooooNo ratings yet
- Easyayurveda Com 2016 07 21 Anosmia Ayurvedic Treatment and Home RemediesDocument1 pageEasyayurveda Com 2016 07 21 Anosmia Ayurvedic Treatment and Home RemediesRahulsinghooooNo ratings yet
- Feature Selection Using Deep Neural Networks: July 2015Document7 pagesFeature Selection Using Deep Neural Networks: July 2015RahulsinghooooNo ratings yet
- Ayurvedic Perspective On Covid 19 SymptomsDocument40 pagesAyurvedic Perspective On Covid 19 SymptomsRahulsinghooooNo ratings yet
- List of Homoeopathic Medicines, Combinations & Their UsesDocument29 pagesList of Homoeopathic Medicines, Combinations & Their Usesgirish261187% (55)
- A Declarative Approach To Ontology Translation With Knowledge PreservationDocument311 pagesA Declarative Approach To Ontology Translation With Knowledge PreservationRahulsinghooooNo ratings yet
- Cray Graph Engine User GuideDocument83 pagesCray Graph Engine User GuideRahulsinghooooNo ratings yet
- Ace Data Science InterviewsDocument84 pagesAce Data Science InterviewsRahulsinghoooo83% (6)
- Movies Database and ScriptsDocument18 pagesMovies Database and ScriptsRahulsinghooooNo ratings yet
- Netwok IpDocument1 pageNetwok IpRahulsinghooooNo ratings yet
- 2 - 6 - Relational Algebra Details - Theta-Join (8-34)Document5 pages2 - 6 - Relational Algebra Details - Theta-Join (8-34)RahulsinghooooNo ratings yet
- Hadoop For DummiesDocument67 pagesHadoop For DummiesKiran100% (2)
- 2 - 7 - SQL For Data Science - Interpreting Complicated SQL (12-12)Document7 pages2 - 7 - SQL For Data Science - Interpreting Complicated SQL (12-12)RahulsinghooooNo ratings yet
- 2 - 9 - Physical Optimization (11-14)Document6 pages2 - 9 - Physical Optimization (11-14)RahulsinghooooNo ratings yet
- 6th Central Pay Commission Salary CalculatorDocument15 pages6th Central Pay Commission Salary Calculatorrakhonde100% (436)
- 2 - 4 - Relational Algebra Details - Union, Diff, Select (10-53)Document6 pages2 - 4 - Relational Algebra Details - Union, Diff, Select (10-53)RahulsinghooooNo ratings yet
- 5 - 3 - Effect Size, Meta-Analysis, Heteroskedasticity (9-31)Document5 pages5 - 3 - Effect Size, Meta-Analysis, Heteroskedasticity (9-31)RahulsinghooooNo ratings yet
- 2 - 2 - Motivating Relational Algebra (8-57)Document5 pages2 - 2 - Motivating Relational Algebra (8-57)RahulsinghooooNo ratings yet
- 6th Central Pay Commission Salary CalculatorDocument15 pages6th Central Pay Commission Salary Calculatorrakhonde100% (436)
- Mit15071xt114-U0101 100Document2 pagesMit15071xt114-U0101 100RahulsinghooooNo ratings yet
- 2 - 1 - From Data Models To Databases (10-35)Document6 pages2 - 1 - From Data Models To Databases (10-35)RahulsinghooooNo ratings yet
- 5 - 1 - Statistics Intro (10-36)Document6 pages5 - 1 - Statistics Intro (10-36)RahulsinghooooNo ratings yet
- Week1 Recitation AllSlidesDocument29 pagesWeek1 Recitation AllSlidesRahulsinghooooNo ratings yet
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (894)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Pone 0074250Document9 pagesPone 0074250alfredoibcNo ratings yet
- R.1 VariousHypoTestAnswrsDocument7 pagesR.1 VariousHypoTestAnswrsArthur ChenNo ratings yet
- Child Abuse and Neglect Among Primary SchoolteachersDocument5 pagesChild Abuse and Neglect Among Primary SchoolteachersMarg YatraNo ratings yet
- Practice of Statistics For Business and Economics 4th Edition Moore Solutions ManualDocument19 pagesPractice of Statistics For Business and Economics 4th Edition Moore Solutions Manualkerenzavaleriehed0100% (24)
- Chapter Four CorrectedDocument10 pagesChapter Four CorrectedLawrence EbosieNo ratings yet
- Effects of Sales Promotion Mix On Customer Satisfaction: A Study With Reference To Shopping MallsDocument11 pagesEffects of Sales Promotion Mix On Customer Satisfaction: A Study With Reference To Shopping MallsNur Yudiono100% (1)
- SPSSDocument46 pagesSPSSDeepika VijayakumarNo ratings yet
- Hypothesis Testing BasicsDocument36 pagesHypothesis Testing BasicsRoyal MechanicalNo ratings yet
- Anti Micro PharmaDocument21 pagesAnti Micro PharmaHanna EdonNo ratings yet
- Statistics and Probability: Quarter 4 - Module 3: Test Statistic On Population MeanDocument24 pagesStatistics and Probability: Quarter 4 - Module 3: Test Statistic On Population MeanJelai MedinaNo ratings yet
- Oup Case StudyDocument4 pagesOup Case StudyAnonymous raI6uYNo ratings yet
- HACCP Plan Fruit YoghurtDocument8 pagesHACCP Plan Fruit YoghurtJaynie Lee VillaranNo ratings yet
- Research Question: A. Research Hypotheses What Is The Hypothesis?Document5 pagesResearch Question: A. Research Hypotheses What Is The Hypothesis?Byrence Aradanas BangsaliwNo ratings yet
- Gender DifferencesDocument14 pagesGender DifferencesRaza MazharNo ratings yet
- Quantitative Methods Exam for Master's in EconomicsDocument4 pagesQuantitative Methods Exam for Master's in EconomicsAnjali YadavNo ratings yet
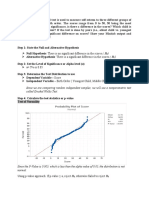
- Step 1: State The Null and Alternative HypothesisDocument3 pagesStep 1: State The Null and Alternative HypothesisChristine Joyce BascoNo ratings yet
- LARS WG ManualDocument29 pagesLARS WG ManualRAFAELNo ratings yet
- IE 162 Laboratory Exercise 3 - Answer SheetDocument8 pagesIE 162 Laboratory Exercise 3 - Answer SheetSamantha MNo ratings yet
- 1) Intro To MinitabDocument29 pages1) Intro To MinitabKareem AbdelazizNo ratings yet
- Home Loan - Hdfc&Icici BankDocument65 pagesHome Loan - Hdfc&Icici BankSahil SethiNo ratings yet
- Lecture 7 - Confidence Intervals and Hypothesis Testing: Statistics 102Document26 pagesLecture 7 - Confidence Intervals and Hypothesis Testing: Statistics 102Manuel BoahenNo ratings yet
- 1330 1507200472 PDFDocument17 pages1330 1507200472 PDFRosemarie SulibagaNo ratings yet
- American Journal of Epidemiology: Am. J. EpidemiolDocument9 pagesAmerican Journal of Epidemiology: Am. J. EpidemiolJapanese2222No ratings yet
- Computational Laboratory For EconomicsDocument461 pagesComputational Laboratory For EconomicsFukuzorgie0% (1)
- Article Research Chat GPTDocument14 pagesArticle Research Chat GPT24- Nguyễn Ngọc Yến VyNo ratings yet
- Eating Habits and Body Image PerceptionsDocument16 pagesEating Habits and Body Image PerceptionscjnicoleNo ratings yet
- Paper7 by KKDocument6 pagesPaper7 by KKKKNo ratings yet
- Rural Urban Khadi ProductsDocument10 pagesRural Urban Khadi Productsbelur_baxi71922No ratings yet
- 12 Statistics and Probability G11 Quarter 4 Module 12 Computating For The Test Statistic Involving Population ProportionDocument27 pages12 Statistics and Probability G11 Quarter 4 Module 12 Computating For The Test Statistic Involving Population ProportionLerwin Garinga100% (9)
- Chapter IiiDocument4 pagesChapter Iiirenlingiftebid143No ratings yet