You might also like
- Trove Research Carbon Credit Demand Supply and Prices 1 June 2021Document51 pagesTrove Research Carbon Credit Demand Supply and Prices 1 June 2021Ceren ArkancanNo ratings yet
- Reaction rate determination and simulation of hydrogenation processDocument3 pagesReaction rate determination and simulation of hydrogenation processToMemNo ratings yet
- Project1Report (Prakash)Document12 pagesProject1Report (Prakash)pgnepal100% (1)
- Cscan 788Document9 pagesCscan 788Adin AdinaNo ratings yet
- Nonlinear regression analysis of data using a spreadsheetDocument2 pagesNonlinear regression analysis of data using a spreadsheetflgrhnNo ratings yet
- Homogeneous Interior Point Method For Constrained Power SchedulingDocument6 pagesHomogeneous Interior Point Method For Constrained Power SchedulingHarish KolliNo ratings yet
- Modelling Network Constrained Economic Dispatch ProblemsDocument6 pagesModelling Network Constrained Economic Dispatch ProblemsNguyễn HồngNo ratings yet
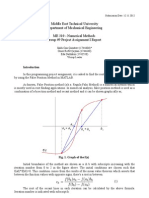
- Middle East Technical University Department of Mechanical Engineering ME 310 - Numerical Methods Group #9 Project Assignment I ReportDocument5 pagesMiddle East Technical University Department of Mechanical Engineering ME 310 - Numerical Methods Group #9 Project Assignment I Reportanon_33416438No ratings yet
- Adaptive Quadrature RevisitedDocument18 pagesAdaptive Quadrature RevisitedSaifuddin AriefNo ratings yet
- A Simple Error Estimator and Adaptive Procedure For Practical Engineering AnalysisDocument21 pagesA Simple Error Estimator and Adaptive Procedure For Practical Engineering AnalysisChao Zhang100% (1)
- Ex 2 SolutionDocument13 pagesEx 2 SolutionMian AlmasNo ratings yet
- Camera Calibration Algorithm ImplementationDocument5 pagesCamera Calibration Algorithm ImplementationgeodesiikaNo ratings yet
- Calibration Using GaDocument6 pagesCalibration Using GaDinesh KumarNo ratings yet
- Adaptive Quadrature RevisitedDocument19 pagesAdaptive Quadrature RevisitedDianaNo ratings yet
- Adaptive Quadrature RevisitedDocument19 pagesAdaptive Quadrature RevisitedVenkatesh PeriasamyNo ratings yet
- Analysis On Algorithm of Wavelet Transform and Its Realization in C LanguageDocument3 pagesAnalysis On Algorithm of Wavelet Transform and Its Realization in C Languagevahdat_kazemiNo ratings yet
- The Use of Finite Element Analysis in The Calculation of Leakage Flux and Dielectric Stress DistributionsDocument35 pagesThe Use of Finite Element Analysis in The Calculation of Leakage Flux and Dielectric Stress DistributionsJeans GonzalezNo ratings yet
- 2014 PR Unsupervised Segmentation and Approximation of Digital Curves With Rate-distortion Curve ModelingDocument11 pages2014 PR Unsupervised Segmentation and Approximation of Digital Curves With Rate-distortion Curve ModelingAlexander KolesnikovNo ratings yet
- Modeling of Quantization EffectsDocument8 pagesModeling of Quantization EffectsdelianchenNo ratings yet
- Kazemi One Millisecond Face 2014 CVPR PaperDocument8 pagesKazemi One Millisecond Face 2014 CVPR PaperRomil ShahNo ratings yet
- Matlab Routines for Subset Selection and Ridge Regression in Linear Neural NetworksDocument46 pagesMatlab Routines for Subset Selection and Ridge Regression in Linear Neural NetworksMAnan NanavatiNo ratings yet
- LDL FactorizacionDocument7 pagesLDL FactorizacionMiguel PerezNo ratings yet
- Exercises PDFDocument30 pagesExercises PDFmylisertaNo ratings yet
- A Dual-Model Fault Detection Approach With Application To Actuators of Robot ManipulatorsDocument6 pagesA Dual-Model Fault Detection Approach With Application To Actuators of Robot ManipulatorsmkannanofficialNo ratings yet
- Image Forgery Detection Based On Quantization Table EstimationDocument4 pagesImage Forgery Detection Based On Quantization Table EstimationKhaled MaNo ratings yet
- Programming Exercise 5: Regularized Linear Regression and Bias V.S. VarianceDocument14 pagesProgramming Exercise 5: Regularized Linear Regression and Bias V.S. VarianceleloiboiNo ratings yet
- A New Method D of Multi Dimensiona Al ScalingDocument6 pagesA New Method D of Multi Dimensiona Al Scalingpis147879No ratings yet
- Is Your Mesh Refined Enough? Estimating Discretization Error Using GCIDocument0 pagesIs Your Mesh Refined Enough? Estimating Discretization Error Using GCIAntonio Martín AlcántaraNo ratings yet
- Safe and Effective Determinant Evaluation: February 25, 1994Document16 pagesSafe and Effective Determinant Evaluation: February 25, 1994David ImmanuelNo ratings yet
- A Sparse Matrix Approach To Reverse Mode AutomaticDocument10 pagesA Sparse Matrix Approach To Reverse Mode Automaticgorot1No ratings yet
- Position Recovery From Accelerometric SensorsDocument50 pagesPosition Recovery From Accelerometric SensorsMarkusMayer100% (1)
- Lecture Notes - Linear RegressionDocument26 pagesLecture Notes - Linear RegressionAmandeep Kaur GahirNo ratings yet
- Department of Computer Science and EngineeringDocument10 pagesDepartment of Computer Science and EngineeringRamesh KumarNo ratings yet
- EKC 244 Lecture 03Document156 pagesEKC 244 Lecture 03Syamsul Rizal Abd ShukorNo ratings yet
- Chapter6 (MBI) ElDocument51 pagesChapter6 (MBI) Eljokowi123No ratings yet
- System Identification Using Matlab: SWF CUA + +Document6 pagesSystem Identification Using Matlab: SWF CUA + +rameshsmeNo ratings yet
- Validación Formulario CMM y Software Evaluación ToleranciaDocument10 pagesValidación Formulario CMM y Software Evaluación ToleranciaAdolfo RodriguezNo ratings yet
- Dynamic Analysis of A Car Chassis Frame Using The Finite Element MethodDocument10 pagesDynamic Analysis of A Car Chassis Frame Using The Finite Element MethodNir ShoNo ratings yet
- Alberty-Matlab Implementation of Fem in ElasticityDocument25 pagesAlberty-Matlab Implementation of Fem in ElasticityRick HunterNo ratings yet
- ISKE2007 Wu HongliangDocument7 pagesISKE2007 Wu HongliangaaayoubNo ratings yet
- Combinational Equivalence Checking Using Satisfiability and Recursive LearningDocument5 pagesCombinational Equivalence Checking Using Satisfiability and Recursive LearningSo FriendNo ratings yet
- Design of Non-Binary Quasi-Cyclic LDPC Codes by ACE OptimizationDocument6 pagesDesign of Non-Binary Quasi-Cyclic LDPC Codes by ACE OptimizationSinshaw BekeleNo ratings yet
- RP SP Far PDFDocument11 pagesRP SP Far PDFAditya KumarNo ratings yet
- Probabilities and Open Pit DesignDocument12 pagesProbabilities and Open Pit DesignmiltonNo ratings yet
- Ex 5Document14 pagesEx 5api-322416213No ratings yet
- Simulink Library Development and Implementation For VLSI Testing in MatlabDocument8 pagesSimulink Library Development and Implementation For VLSI Testing in MatlabM Chandan ShankarNo ratings yet
- Excel RegressionDocument41 pagesExcel RegressionSteve WanNo ratings yet
- M. W Dunnigan: Department Oj Computing and Electrical Engineering, Heriot-Watt University, Edinburgh, ScotlandDocument13 pagesM. W Dunnigan: Department Oj Computing and Electrical Engineering, Heriot-Watt University, Edinburgh, ScotlandVictor PassosNo ratings yet
- CSL-MAINV Preconditioner for Helmholtz EquationsDocument3 pagesCSL-MAINV Preconditioner for Helmholtz EquationssinsecticideNo ratings yet
- From The Initial State, or As From The Moment of Preceding Calculation, One Calculates The Stress Field Resulting From An Increment of DeformationDocument10 pagesFrom The Initial State, or As From The Moment of Preceding Calculation, One Calculates The Stress Field Resulting From An Increment of DeformationTran TuyenNo ratings yet
- Programming Exercise 5: Regularized Linear Regression and Bias v.s. VarianceDocument14 pagesProgramming Exercise 5: Regularized Linear Regression and Bias v.s. VarianceMarko KneževićNo ratings yet
- Image Compression Using Curvelet TransformDocument21 pagesImage Compression Using Curvelet Transformramnag4No ratings yet
- Chap 12Document120 pagesChap 12Phuc LxNo ratings yet
- Fault Diagnosis Model Through Fuzzy Clustering: LV of Science ofDocument5 pagesFault Diagnosis Model Through Fuzzy Clustering: LV of Science ofrvicentclasesNo ratings yet
- Mtable PDFDocument41 pagesMtable PDFOraka NowfelNo ratings yet
- Chain Ladder MethodDocument54 pagesChain Ladder MethodTaitip SuphasiriwattanaNo ratings yet
- Linear Programming Method Application in A Solar CellDocument12 pagesLinear Programming Method Application in A Solar CellKaty Flores OrihuelaNo ratings yet
- A 2589 Line Topology Optimization Code Written For The Graphics CardDocument20 pagesA 2589 Line Topology Optimization Code Written For The Graphics Cardgorot1No ratings yet
- Hardware Implementation of Finite Fields of Characteristic ThreeDocument11 pagesHardware Implementation of Finite Fields of Characteristic ThreehachiiiimNo ratings yet
- Integer Optimization and its Computation in Emergency ManagementFrom EverandInteger Optimization and its Computation in Emergency ManagementNo ratings yet
- 2017 119Document2 pages2017 119Anonymous PsEz5kGVaeNo ratings yet
- The Internet of Things: Jonathan Brewer Network Startup Resource CenterDocument47 pagesThe Internet of Things: Jonathan Brewer Network Startup Resource CenterAnonymous PsEz5kGVaeNo ratings yet
- MELIONES - A Web-Based Three-Tier Control and Monitoring Application For Integrated Facility Management of Photovoltaic SystemsDocument24 pagesMELIONES - A Web-Based Three-Tier Control and Monitoring Application For Integrated Facility Management of Photovoltaic SystemsAnonymous PsEz5kGVaeNo ratings yet
- ALI.203 - The New Energy PolicyDocument22 pagesALI.203 - The New Energy PolicyAnonymous PsEz5kGVaeNo ratings yet
- AURELL.2015.Model For Installation Cost ManagementDocument103 pagesAURELL.2015.Model For Installation Cost ManagementAnonymous PsEz5kGVaeNo ratings yet
- Research of Intelligent Gas Detecting System For Coal MineDocument13 pagesResearch of Intelligent Gas Detecting System For Coal MineAnonymous PsEz5kGVaeNo ratings yet
- IYONI II - Gas Monitor and Cap Lamp CombinationDocument2 pagesIYONI II - Gas Monitor and Cap Lamp CombinationAnonymous PsEz5kGVaeNo ratings yet
- 22b.patterson Gpops II August 2013Document41 pages22b.patterson Gpops II August 2013Anonymous PsEz5kGVaeNo ratings yet
- USSDEK - High-Sensitivity Gas Detection and Monitoring System For High-Risk Welding ActivityDocument6 pagesUSSDEK - High-Sensitivity Gas Detection and Monitoring System For High-Risk Welding ActivityAnonymous PsEz5kGVaeNo ratings yet
- Multi-objective facility layout problem using simulated annealingDocument16 pagesMulti-objective facility layout problem using simulated annealingAnonymous PsEz5kGVaeNo ratings yet
- 10 1 1 669 794Document3 pages10 1 1 669 794Anonymous PsEz5kGVaeNo ratings yet
- 8 ShenDocument9 pages8 ShenAnonymous PsEz5kGVaeNo ratings yet
- 37 ShenDocument15 pages37 ShenAnonymous PsEz5kGVaeNo ratings yet
- Research Article: The Construction of Support Vector Machine Classifier Using The Firefly AlgorithmDocument9 pagesResearch Article: The Construction of Support Vector Machine Classifier Using The Firefly AlgorithmAnonymous PsEz5kGVaeNo ratings yet
- 8 HoDocument22 pages8 HoAnonymous PsEz5kGVaeNo ratings yet
- 12 HuangDocument11 pages12 HuangAnonymous PsEz5kGVaeNo ratings yet
- 3 ChenDocument13 pages3 ChenAnonymous PsEz5kGVaeNo ratings yet
- Patterson Gpopsii UsersguideDocument71 pagesPatterson Gpopsii UsersguideAnonymous PsEz5kGVaeNo ratings yet
- 24 TeoDocument6 pages24 TeoAnonymous PsEz5kGVaeNo ratings yet
- NILSBACK.2006 - A Visual Vocabulary For Flower ClassificationDocument8 pagesNILSBACK.2006 - A Visual Vocabulary For Flower ClassificationAnonymous PsEz5kGVaeNo ratings yet
- International Journal of Production ResearchDocument22 pagesInternational Journal of Production ResearchAnonymous PsEz5kGVaeNo ratings yet
- An Improved Simulated Annealing For Facility Layout Problems in Cellular Manufacturing SystemsDocument11 pagesAn Improved Simulated Annealing For Facility Layout Problems in Cellular Manufacturing SystemsAnonymous PsEz5kGVaeNo ratings yet
- LI.2012 - Automatic Woven Fabric Classification Based On SVMDocument4 pagesLI.2012 - Automatic Woven Fabric Classification Based On SVMAnonymous PsEz5kGVaeNo ratings yet
- SERRE.2007 - Robust Object Recognition With Cortex-Like Mechanism PDFDocument16 pagesSERRE.2007 - Robust Object Recognition With Cortex-Like Mechanism PDFAnonymous PsEz5kGVaeNo ratings yet
- KELLER - Single Row Layout ModelsDocument16 pagesKELLER - Single Row Layout ModelsAnonymous PsEz5kGVaeNo ratings yet
- KLOESEL - A Technology Pathway For Airbreathing, Combined-Cycle, Horizontal Space Launch Through SR-71 Based Trajectory ModelingDocument19 pagesKLOESEL - A Technology Pathway For Airbreathing, Combined-Cycle, Horizontal Space Launch Through SR-71 Based Trajectory ModelingAnonymous PsEz5kGVaeNo ratings yet
- Van de WEIJER.2006 - Coloring Local Feature ExtractionDocument14 pagesVan de WEIJER.2006 - Coloring Local Feature ExtractionAnonymous PsEz5kGVaeNo ratings yet
- SCHMIDHUBER.2015 - Deep Learning in Neural Networks. An OverviewDocument33 pagesSCHMIDHUBER.2015 - Deep Learning in Neural Networks. An OverviewAnonymous PsEz5kGVaeNo ratings yet
- A Day in ReykjavíkDocument6 pagesA Day in ReykjavíkAnonymous PsEz5kGVaeNo ratings yet
- KANG.2015 - Automatic Classification of Woven Fabric Structure Based On Computer Vision TechniquesDocument12 pagesKANG.2015 - Automatic Classification of Woven Fabric Structure Based On Computer Vision TechniquesAnonymous PsEz5kGVaeNo ratings yet
- Marijuana Grow Basics - Jorge CervantesDocument389 pagesMarijuana Grow Basics - Jorge CervantesHugo Herrera100% (1)
- The Impact of Information Technology and Innovation To Improve Business Performance Through Marketing Capabilities in Online Businesses by Young GenerationsDocument10 pagesThe Impact of Information Technology and Innovation To Improve Business Performance Through Marketing Capabilities in Online Businesses by Young GenerationsLanta KhairunisaNo ratings yet
- Ilham Bahasa InggrisDocument12 pagesIlham Bahasa Inggrisilhamwicaksono835No ratings yet
- Solr 3000: Special Operations Long Range Oxygen Supply 3,000 PsigDocument2 pagesSolr 3000: Special Operations Long Range Oxygen Supply 3,000 Psigмар'ян коб'ялковськийNo ratings yet
- Relay Coordination Using Digsilent PowerFactoryDocument12 pagesRelay Coordination Using Digsilent PowerFactoryutshab.ghosh2023No ratings yet
- Denodo Job RoleDocument2 pagesDenodo Job Role059 Monisha BaskarNo ratings yet
- Believer - Imagine Dragons - CIFRA CLUBDocument9 pagesBeliever - Imagine Dragons - CIFRA CLUBSilvio Augusto Comercial 01No ratings yet
- Hencher - Interpretation of Direct Shear Tests On Rock JointsDocument8 pagesHencher - Interpretation of Direct Shear Tests On Rock JointsMark2123100% (1)
- Mesopotamia CivilizationDocument56 pagesMesopotamia CivilizationYashika TharwaniNo ratings yet
- Voltaire's Candide and the Role of Free WillDocument3 pagesVoltaire's Candide and the Role of Free WillAngy ShoogzNo ratings yet
- Center of Gravity and Shear Center of Thin-Walled Open-Section Composite BeamsDocument6 pagesCenter of Gravity and Shear Center of Thin-Walled Open-Section Composite Beamsredz00100% (1)
- W1inse6220 PDFDocument11 pagesW1inse6220 PDFpicalaNo ratings yet
- Introduction To Streering Gear SystemDocument1 pageIntroduction To Streering Gear SystemNorman prattNo ratings yet
- Fiery Training 1Document346 pagesFiery Training 1shamilbasayevNo ratings yet
- Levels of Attainment.Document6 pagesLevels of Attainment.rajeshbarasaraNo ratings yet
- BMXNRPDocument60 pagesBMXNRPSivaprasad KcNo ratings yet
- Operation Guide For The Mercedes-Benz GLA/CLADocument5 pagesOperation Guide For The Mercedes-Benz GLA/CLASantosh TalankarNo ratings yet
- IT SyllabusDocument3 pagesIT SyllabusNeilKumarNo ratings yet
- The Slave Trade and The British Empire An Audit of Commemoration in WalesDocument133 pagesThe Slave Trade and The British Empire An Audit of Commemoration in WaleslegoarkeologNo ratings yet
- Startups Helping - India Go GreenDocument13 pagesStartups Helping - India Go Greensimran kNo ratings yet
- Vintage Style Indonesian Geography Lesson For High School by SlidesgoDocument56 pagesVintage Style Indonesian Geography Lesson For High School by Slidesgoohd InstalasicontrolNo ratings yet
- BSC6900 UMTS V900R011C00SPC700 Parameter ReferenceDocument1,010 pagesBSC6900 UMTS V900R011C00SPC700 Parameter Referenceronnie_smgNo ratings yet
- Mama Leone's Profitability AnalysisDocument6 pagesMama Leone's Profitability AnalysisLuc TranNo ratings yet
- Critique On A Film Director's Approach To Managing CreativityDocument2 pagesCritique On A Film Director's Approach To Managing CreativityDax GaffudNo ratings yet
- Basic Calculus: Performance TaskDocument6 pagesBasic Calculus: Performance TasksammyNo ratings yet
- Class 9th Chemistry Unit#4 Structure of MoleculesDocument8 pagesClass 9th Chemistry Unit#4 Structure of MoleculesIrfanullahNo ratings yet
- Mythic Magazine 017Document43 pagesMythic Magazine 017William Warren100% (1)