You might also like
- Earned Value Analysis SoftwareDocument9 pagesEarned Value Analysis SoftwareosemavNo ratings yet
- CarusoDocument27 pagesCarusoosemavNo ratings yet
- Practical Guide To MSCEITDocument15 pagesPractical Guide To MSCEITosemav100% (2)
- Leadership and Emotional IntelligenceDocument8 pagesLeadership and Emotional IntelligenceosemavNo ratings yet
- The Business Case For Emotional Intelligence: Joshua Freedman & Todd Everett, MBADocument32 pagesThe Business Case For Emotional Intelligence: Joshua Freedman & Todd Everett, MBAHelen GrantNo ratings yet
- Neuroscience and EducationDocument28 pagesNeuroscience and EducationosemavNo ratings yet
- Handbook For Software Cost Estimation PDFDocument63 pagesHandbook For Software Cost Estimation PDFcyber_amanNo ratings yet
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5783)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (890)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (72)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Porter 5 ForcesDocument44 pagesPorter 5 ForcesSwapnil ChonkarNo ratings yet
- Rediscovering Ecotorism - : Poaching, A Major Challenge in Liwonde National Park Cashing in On TourismDocument28 pagesRediscovering Ecotorism - : Poaching, A Major Challenge in Liwonde National Park Cashing in On TourismJohn Richard KasalikaNo ratings yet
- Appetizers Fire-Grilled Gourmet Burgers: Red Robin'S Finest Burgers Red'S Tavern MenuDocument2 pagesAppetizers Fire-Grilled Gourmet Burgers: Red Robin'S Finest Burgers Red'S Tavern MenufruitfuckNo ratings yet
- Catalogo Bombas PedrolloDocument80 pagesCatalogo Bombas PedrolloChesster EscobarNo ratings yet
- Project Close OutDocument12 pagesProject Close OutWeel HiaNo ratings yet
- Haley Sue Exsted FacebookDocument58 pagesHaley Sue Exsted Facebookapi-323808402No ratings yet
- E-Leadership Literature ReviewDocument36 pagesE-Leadership Literature ReviewYasser BahaaNo ratings yet
- Dimensions of Comparative EducationDocument5 pagesDimensions of Comparative Educationeminentsurvivor9No ratings yet
- Simplex-4004 Installation Operating Manual Rev C PDFDocument36 pagesSimplex-4004 Installation Operating Manual Rev C PDFElias Rangel100% (1)
- Louise Bedford Trading InsightsDocument80 pagesLouise Bedford Trading Insightsartendu100% (3)
- Task and Link Analysis AssignmentDocument4 pagesTask and Link Analysis AssignmentAzeem NawazNo ratings yet
- TBEM CII Exim Bank Award ComparisonDocument38 pagesTBEM CII Exim Bank Award ComparisonSamNo ratings yet
- Deed of Sale for 2009 Toyota PickupDocument1 pageDeed of Sale for 2009 Toyota PickupRheal P Esmail100% (3)
- 5 Hunger of The PineDocument39 pages5 Hunger of The PinedraconeitNo ratings yet
- Nord Lock Washers Material Type GuideDocument1 pageNord Lock Washers Material Type GuideArthur ZinkeNo ratings yet
- Horses To Follow: Ten To Follow From Timeform'S Team of ExpertsDocument12 pagesHorses To Follow: Ten To Follow From Timeform'S Team of ExpertsNita naNo ratings yet
- FS 1 Observations of Teaching-Learning in Actual School EnvironmentDocument8 pagesFS 1 Observations of Teaching-Learning in Actual School EnvironmentJessie PeraltaNo ratings yet
- Patanjali PDFDocument11 pagesPatanjali PDFSiddharth GuptaNo ratings yet
- CompReg 13SEPTEMBER2023Document2,725 pagesCompReg 13SEPTEMBER2023syed pashaNo ratings yet
- A Light Sculling Training Boat PDFDocument8 pagesA Light Sculling Training Boat PDFLuis BraulinoNo ratings yet
- School Development Plan 2022Document3 pagesSchool Development Plan 2022Nora Herrera100% (6)
- SITXWHS001 Participate in Safe Work Practices - Training ManualDocument82 pagesSITXWHS001 Participate in Safe Work Practices - Training ManualIsuru AbhimanNo ratings yet
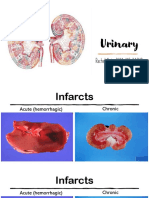
- Urinary: Rachel Neto, DVM, MS, DACVP May 28 2020Document15 pagesUrinary: Rachel Neto, DVM, MS, DACVP May 28 2020Rachel AutranNo ratings yet
- MGN 363Document14 pagesMGN 363Nitin PatidarNo ratings yet
- Cisco Dcloud Lab Access Tutorial For HyperFlex Virtual EnablementDocument7 pagesCisco Dcloud Lab Access Tutorial For HyperFlex Virtual Enablementfd77No ratings yet
- Samsung Investor Presentation CE 2022 v1Document22 pagesSamsung Investor Presentation CE 2022 v1Sagar chNo ratings yet
- Science 7 Module1Document22 pagesScience 7 Module1Hector Panti0% (1)
- Multinational Business Finance 12th Edition Slides Chapter 12Document33 pagesMultinational Business Finance 12th Edition Slides Chapter 12Alli Tobba100% (1)
- Ilogic LinkDocument13 pagesIlogic Linkbekirrrr100% (1)
- Plastic RecyclingDocument14 pagesPlastic RecyclingLevitaNo ratings yet