You might also like
- Analytics All Web Site Data Mediavine Application 20171024-20171122Document2 pagesAnalytics All Web Site Data Mediavine Application 20171024-20171122LoiLeVanNo ratings yet
- VerilogDocument5 pagesVerilogLoiLeVanNo ratings yet
- Combinational Automatic Test Pattern GenerationDocument26 pagesCombinational Automatic Test Pattern GenerationLoiLeVanNo ratings yet
- Lecture 34: MOSFET Common Gate AmplifierDocument9 pagesLecture 34: MOSFET Common Gate AmplifierLoiLeVanNo ratings yet
- CPF Tutorial 2007 12 06Document55 pagesCPF Tutorial 2007 12 06LoiLeVanNo ratings yet
- Electronics Testing With A MultimeterDocument8 pagesElectronics Testing With A MultimeterLoiLeVan50% (2)
- Transmission LinesDocument222 pagesTransmission LinesLoiLeVanNo ratings yet
- 180mV Low Voltage FFT Processor Paper On IEEEDocument10 pages180mV Low Voltage FFT Processor Paper On IEEELoiLeVanNo ratings yet
- Ass3 SpecDocument12 pagesAss3 SpecLoiLeVanNo ratings yet
- Lec2.2 Timing UpDocument20 pagesLec2.2 Timing UpLoiLeVanNo ratings yet
- 3 - Photoresist TechnologyDocument87 pages3 - Photoresist TechnologyLoiLeVanNo ratings yet
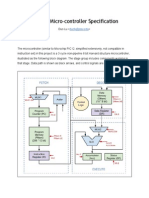
- Microcontroller Specification FinalDocument22 pagesMicrocontroller Specification FinalLoiLeVanNo ratings yet
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (345)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- LCS21 - 35 - Polar PlotsDocument14 pagesLCS21 - 35 - Polar Plotsgosek16375No ratings yet
- PB152 - CJ60 GongDocument2 pagesPB152 - CJ60 GongJibjab7No ratings yet
- Computer Graphics: Overview of Graphics SystemsDocument25 pagesComputer Graphics: Overview of Graphics Systemsshibina balakrishnanNo ratings yet
- The Power of Human Connection Review 2Document81 pagesThe Power of Human Connection Review 2Tajam SoftNo ratings yet
- Ant CabDocument93 pagesAnt CabZubair MinhasNo ratings yet
- Austsignpostmathsnsw sb9 5.1-3 00Document24 pagesAustsignpostmathsnsw sb9 5.1-3 00Minus Venus0% (3)
- Cable Sizing CalculationDocument72 pagesCable Sizing CalculationHARI my songs100% (1)
- Glpi Developer DocumentationDocument112 pagesGlpi Developer Documentationvictorlage7No ratings yet
- Mit BBM (Ib), Ipm-Session 2.4Document32 pagesMit BBM (Ib), Ipm-Session 2.4Yogesh AdhateNo ratings yet
- Lab Manual of Hydraulics PDFDocument40 pagesLab Manual of Hydraulics PDFJULIUS CESAR G. CADAONo ratings yet
- 5-Canal Irrigation SystemDocument23 pages5-Canal Irrigation Systemwajid malikNo ratings yet
- DLT Strand Jack Systems - 2.0 - 600 PDFDocument24 pagesDLT Strand Jack Systems - 2.0 - 600 PDFganda liftindoNo ratings yet
- ImmunologyDocument8 pagesImmunologyማላያላም ማላያላም89% (9)
- Honda IDSI SM - 5 PDFDocument14 pagesHonda IDSI SM - 5 PDFauto projectNo ratings yet
- Assignment - 1 Introduction of Machines and Mechanisms: TheoryDocument23 pagesAssignment - 1 Introduction of Machines and Mechanisms: TheoryAman AmanNo ratings yet
- Data Cable Containment SizingDocument21 pagesData Cable Containment SizingAngelo Franklin100% (1)
- Chapter - Four Soil Permeability and SeepageDocument19 pagesChapter - Four Soil Permeability and SeepageBefkadu KurtaileNo ratings yet
- Auto-Tune Pid Temperature & Timer General Specifications: N L1 L2 L3Document4 pagesAuto-Tune Pid Temperature & Timer General Specifications: N L1 L2 L3sharawany 20No ratings yet
- Lec1 PDFDocument12 pagesLec1 PDFtogarsNo ratings yet
- Solved Worksheet-Cell and Specialized Cells 3Document3 pagesSolved Worksheet-Cell and Specialized Cells 3Everything Everything100% (1)
- InfoDocument18 pagesInfoKaran Verm'aNo ratings yet
- Presentation5 EV ArchitectureDocument26 pagesPresentation5 EV ArchitectureJAYKUMAR MUKESHBHAI THAKORNo ratings yet
- Bent's RuleDocument3 pagesBent's RuleEdwinNo ratings yet
- Open Source Software Development and Lotka's Law: Bibliometric Patterns in ProgrammingDocument10 pagesOpen Source Software Development and Lotka's Law: Bibliometric Patterns in ProgrammingAttya ShahidNo ratings yet
- Phrasal Verbs-Syntactic BehaviorDocument4 pagesPhrasal Verbs-Syntactic BehaviorAntonija KnezovićNo ratings yet
- Analiza Procesa Ocenjivanja Na Časovima Matematike - BaucalDocument22 pagesAnaliza Procesa Ocenjivanja Na Časovima Matematike - BaucalНевенка ЈовановићNo ratings yet
- Awodey, Categories For Everybody - PsDocument196 pagesAwodey, Categories For Everybody - PsΣωτήρης Ντελής100% (3)
- Sci - Short Circuit IsolatorDocument2 pagesSci - Short Circuit IsolatorVictor MoraesNo ratings yet
- Groundwater Flow-Chapter3FYDocument73 pagesGroundwater Flow-Chapter3FYTemesgen workiyeNo ratings yet
- Comptector & Chiller (Cdu) Controller (Fx32C Series) : Precaution For UseDocument5 pagesComptector & Chiller (Cdu) Controller (Fx32C Series) : Precaution For UseFcma0903100% (1)