You might also like
- Safety and Immunogenicity of the Respiratory Syncytial Virus Vaccine RSV/ΔNS2/Δ1313/I1314L in RSV-Seronegative ChildrenDocument10 pagesSafety and Immunogenicity of the Respiratory Syncytial Virus Vaccine RSV/ΔNS2/Δ1313/I1314L in RSV-Seronegative ChildrenminaNo ratings yet
- Academic Word List - Sublist 8Document3 pagesAcademic Word List - Sublist 8pallavi agarwalNo ratings yet
- New Drug Innovation and Pharmaceutical Industry Structure: Trends in The Output of Pharmaceutical FirmsDocument26 pagesNew Drug Innovation and Pharmaceutical Industry Structure: Trends in The Output of Pharmaceutical FirmsminaNo ratings yet
- Innovating by Developing New Uses of Already-Approved Drugs: Trends in The Marketing Approval of Supplemental IndicationsDocument11 pagesInnovating by Developing New Uses of Already-Approved Drugs: Trends in The Marketing Approval of Supplemental IndicationsminaNo ratings yet
- Sierre Leone Guidelines For Medicinal PdtsDocument20 pagesSierre Leone Guidelines For Medicinal PdtsminaNo ratings yet
- Revision Notes Chemistry 2 CompleteDocument11 pagesRevision Notes Chemistry 2 CompleteminaNo ratings yet
- Role of Scientific CommitteeDocument1 pageRole of Scientific CommitteeminaNo ratings yet
- Crispr Cas 9 Gene EditingDocument4 pagesCrispr Cas 9 Gene EditingminaNo ratings yet
- Crispr Cas 9 Gene EditingDocument4 pagesCrispr Cas 9 Gene EditingminaNo ratings yet
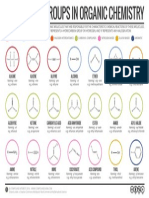
- Organic Functional GroupsDocument1 pageOrganic Functional GroupsCarolina MallamaNo ratings yet
- How DNA Microarray Works PDFDocument1 pageHow DNA Microarray Works PDFminaNo ratings yet
- Metabolism of DisaccharidesDocument15 pagesMetabolism of DisaccharidesminaNo ratings yet
- How DNA Microarray WorksDocument12 pagesHow DNA Microarray WorksminaNo ratings yet
- Organic Functional Groups UpdateDocument33 pagesOrganic Functional Groups UpdateminaNo ratings yet
- Safety Monitoring and Reporting in Clinical Trials NHMRC Nov2016 PDFDocument27 pagesSafety Monitoring and Reporting in Clinical Trials NHMRC Nov2016 PDFminaNo ratings yet
- Computer Aided Drug Design Success and Limitations PDFDocument10 pagesComputer Aided Drug Design Success and Limitations PDFminaNo ratings yet
- 2013 BPS Recertification GuideDocument10 pages2013 BPS Recertification GuideminaNo ratings yet
- Pharmacovigilance in Clinical Trials - PPTX FinalDocument20 pagesPharmacovigilance in Clinical Trials - PPTX Finalmina100% (1)
- 18-2013 UTpt Card01Document48 pages18-2013 UTpt Card01minaNo ratings yet
- 15-2013 UTpt NephDocument34 pages15-2013 UTpt NephminaNo ratings yet
- Academic Word List - Sublist 4Document4 pagesAcademic Word List - Sublist 4MarthaNo ratings yet
- Revision Notes Chemistry 2 CompleteDocument11 pagesRevision Notes Chemistry 2 CompleteminaNo ratings yet
- 09-2013 UTpt EndoDocument44 pages09-2013 UTpt Endomina0% (1)
- TocDocument4 pagesTocminaNo ratings yet
- PPC13 FacultyDocument2 pagesPPC13 FacultyminaNo ratings yet
- Program Goals and Target AudienceDocument1 pageProgram Goals and Target AudienceminaNo ratings yet
- 9822 USP 1160 Pharm CalcDocument12 pages9822 USP 1160 Pharm Calcandreas hpNo ratings yet
- Medical Surgical Nursing Review NotesDocument75 pagesMedical Surgical Nursing Review Notesstuffednurse92% (146)
- A To Z Drugs-2 PDFDocument40 pagesA To Z Drugs-2 PDFMohamedYosef71% (7)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (890)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Nonsteroidal Antiinflammatory DrugsDocument12 pagesNonsteroidal Antiinflammatory DrugsAlano S. LimgasNo ratings yet
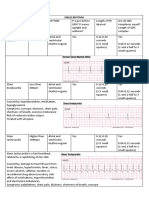
- ECG Arrhythmia GuideDocument5 pagesECG Arrhythmia GuideMasarrah AlchiNo ratings yet
- Medication Charge ReportDocument1,905 pagesMedication Charge ReportRajabagus HarapanEntertaimentNo ratings yet
- Gastro Retentive Drug Delivery SystemDocument20 pagesGastro Retentive Drug Delivery SystemokNo ratings yet
- Disorders of Parathyroid Glands: Hyperparathyroidism and HypoparathyroidismDocument52 pagesDisorders of Parathyroid Glands: Hyperparathyroidism and HypoparathyroidismDr. Akash GuptaNo ratings yet
- Supply Shortages Alerts Update Issue 24Document3 pagesSupply Shortages Alerts Update Issue 24gobsheen666No ratings yet
- Covid 19 TreatmentDocument2 pagesCovid 19 TreatmentGio Tamaño BalisiNo ratings yet
- In Vivo and in Vitro Evaluation of Four Different Aqueous Polymeric Dispersions For Producing An Enteric Coated TabletDocument6 pagesIn Vivo and in Vitro Evaluation of Four Different Aqueous Polymeric Dispersions For Producing An Enteric Coated TabletSara QuirozNo ratings yet
- Unit 05 Word Wall - States of ConsciousnessDocument15 pagesUnit 05 Word Wall - States of ConsciousnessJayNo ratings yet
- Principles and Practice of Toxicology in Public Health 2nd Edition Ebook PDFDocument61 pagesPrinciples and Practice of Toxicology in Public Health 2nd Edition Ebook PDFhelen.fico427100% (42)
- Coli (ETEC) Strains Isolated From Hospitalized ChildrenDocument6 pagesColi (ETEC) Strains Isolated From Hospitalized ChildrenMartyn PereiraNo ratings yet
- Anticancer Activity of Anise (Pimpinella Anisum L.) Seed Extract.Document5 pagesAnticancer Activity of Anise (Pimpinella Anisum L.) Seed Extract.Gregory KalonaNo ratings yet
- Common Ophthalmic DrugsDocument3 pagesCommon Ophthalmic DrugsBadr DihamNo ratings yet
- Trombembolismul PulmonarDocument9 pagesTrombembolismul PulmonarCătălina Raluca CojoceaNo ratings yet
- Request Letter For Pre-InD MeetingDocument7 pagesRequest Letter For Pre-InD MeetingharshitNo ratings yet
- Role of Autophagy and Apoptosis in AcuteDocument8 pagesRole of Autophagy and Apoptosis in AcuteJesus_Arraiz_14No ratings yet
- Cardiac Metabolism in Health and Disease-Opie, Lionel H-In Cellular and Molecular Pathobiology of Cardiovascular Disease, 2014Document14 pagesCardiac Metabolism in Health and Disease-Opie, Lionel H-In Cellular and Molecular Pathobiology of Cardiovascular Disease, 2014AnaInesRodriguezNo ratings yet
- (Peter M. Haddad, Serdar Dursun, Bill Deakin) Adve (BookFi) PDFDocument335 pages(Peter M. Haddad, Serdar Dursun, Bill Deakin) Adve (BookFi) PDFFrancesca Ruiz100% (1)
- Nrn101 and Nrn102 Drug Card: Zithromax, Zmax, Z-PakDocument2 pagesNrn101 and Nrn102 Drug Card: Zithromax, Zmax, Z-PakJanet Sheldon50% (2)
- AyurvedaDocument1 pageAyurvedaAddissonNo ratings yet
- Respiratory PhysiologyDocument16 pagesRespiratory PhysiologyYsabel Salvador DychincoNo ratings yet
- By Dr. Kamran Javed Naquvi,: Unit II Pharmacognosy (DP-103)Document31 pagesBy Dr. Kamran Javed Naquvi,: Unit II Pharmacognosy (DP-103)Bashar AhmedNo ratings yet
- New QU 8-2017 Pearson VueDocument18 pagesNew QU 8-2017 Pearson Vueahmed masoud100% (1)
- Practneurol 2020 002763Document12 pagesPractneurol 2020 002763Edgar MoralesNo ratings yet
- List of Anesthesia Library BooksDocument3 pagesList of Anesthesia Library BooksSivaramakrishnan Dhamotharan100% (2)
- Banstag Life Sciences proposed manufacturing plantDocument66 pagesBanstag Life Sciences proposed manufacturing plantemad hayekNo ratings yet
- 43 Shravan ParmarDocument30 pages43 Shravan Parmarsai projectNo ratings yet
- Gastrointestinal Bleeding Risk Factors and ManagementDocument17 pagesGastrointestinal Bleeding Risk Factors and ManagementMaría José GalvisNo ratings yet
- Ipr ProjectDocument23 pagesIpr ProjectKriti KhareNo ratings yet
- Family Life Cycle StagesDocument8 pagesFamily Life Cycle StagesDanishNo ratings yet