You might also like
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (894)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- Excel VBA Course Notes 2 - LoopsDocument4 pagesExcel VBA Course Notes 2 - LoopsPapa KingNo ratings yet
- Hybris-SAP Integration ArchitectureDocument9 pagesHybris-SAP Integration ArchitectureSubhadip Das Sarma100% (1)
- EschatologyDocument10 pagesEschatologyJijoyM100% (3)
- Project SynopsisDocument9 pagesProject Synopsisshruti raiNo ratings yet
- MCQs On MotivationDocument12 pagesMCQs On MotivationSubhadip Das Sarma93% (100)
- 8-12OPM Period End ProcessDocument22 pages8-12OPM Period End ProcessBhaskararaoSimmaNo ratings yet
- 2 - BODS ErrorsDocument19 pages2 - BODS ErrorsSubhadip Das Sarma100% (1)
- Configuration GuideDocument41 pagesConfiguration GuideSubhadip Das SarmaNo ratings yet
- Web Application Developers GuideDocument296 pagesWeb Application Developers GuideSubhadip Das SarmaNo ratings yet
- RUP Best PracticesDocument21 pagesRUP Best PracticesJohana Cevallos100% (17)
- (Autonomous) (ISO/IEC - 27001 - 2005 Certified) Summer - 2022 Examination Model Answer Subject: Wireless & Mobile Network Subject Code: 22622Document26 pages(Autonomous) (ISO/IEC - 27001 - 2005 Certified) Summer - 2022 Examination Model Answer Subject: Wireless & Mobile Network Subject Code: 22622Gaurav Langhi100% (1)
- Cloud Application DevelopmentDocument7 pagesCloud Application DevelopmentSubhadip Das SarmaNo ratings yet
- Sotis DramalisDocument6 pagesSotis DramalisSubhadip Das Sarma100% (1)
- Stephanie Hudson Finance Expert SAPDocument3 pagesStephanie Hudson Finance Expert SAPSubhadip Das SarmaNo ratings yet
- Basics of GST Implementation in IndiaDocument4 pagesBasics of GST Implementation in IndiaSubhadip Das SarmaNo ratings yet
- Vinay ReddyDocument7 pagesVinay ReddySubhadip Das SarmaNo ratings yet
- Virtualization and Cloud ComputingDocument33 pagesVirtualization and Cloud ComputingSubhadip Das Sarma100% (1)
- 9.open ODS ViewsDocument19 pages9.open ODS ViewsSubhadip Das SarmaNo ratings yet
- Swapan SahaDocument6 pagesSwapan SahaSubhadip Das SarmaNo ratings yet
- Calculation ViewDocument18 pagesCalculation ViewSubhadip Das SarmaNo ratings yet
- Preconfigured SAP Best Practices for Pharmaceutical Industry PresalesDocument8 pagesPreconfigured SAP Best Practices for Pharmaceutical Industry PresalesSubhadip Das SarmaNo ratings yet
- SQLDocument41 pagesSQLSubhadip Das SarmaNo ratings yet
- Cloud SecurityDocument38 pagesCloud SecuritySubhadip Das Sarma100% (1)
- Eub03011usen PDFDocument8 pagesEub03011usen PDFSubhadip Das SarmaNo ratings yet
- Resignation LetterDocument2 pagesResignation LetterSubhadip Das SarmaNo ratings yet
- QM PPT Gsa DeloDocument13 pagesQM PPT Gsa DeloSubhadip Das SarmaNo ratings yet
- Translation Strategies GuideDocument7 pagesTranslation Strategies GuideMuetya Permata DaraNo ratings yet
- LicenceDocument3 pagesLicenceAndika GlinNo ratings yet
- Cambridge IGCSE™: Physics 0625/32 March 2020Document11 pagesCambridge IGCSE™: Physics 0625/32 March 2020Wilber TuryasiimaNo ratings yet
- The Shakespearean Sonnet: WorksheetDocument3 pagesThe Shakespearean Sonnet: WorksheetJ M McRaeNo ratings yet
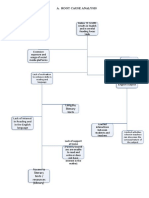
- Project REAP-Root Cause AnalysisDocument4 pagesProject REAP-Root Cause AnalysisAIRA NINA COSICONo ratings yet
- DLL - English 4 - Q4 - W9Document4 pagesDLL - English 4 - Q4 - W9Roemyr BellezasNo ratings yet
- C++ Program: All Tasks .CPPDocument14 pagesC++ Program: All Tasks .CPPKhalid WaleedNo ratings yet
- Antiochene exegesis traditions examinedDocument18 pagesAntiochene exegesis traditions examinedPricopi VictorNo ratings yet
- Judd-Ofelt Theory in A New Light On Its (Almost) 40 AnniversaryDocument7 pagesJudd-Ofelt Theory in A New Light On Its (Almost) 40 AnniversaryMalek BombasteinNo ratings yet
- Libros para Aprender InglesDocument3 pagesLibros para Aprender InglesJohn Guzman100% (1)
- GlossaryDocument9 pagesGlossarysaeedNo ratings yet
- Lesson Plan 1 - What Do Seeds Need To Grow Group 1Document5 pagesLesson Plan 1 - What Do Seeds Need To Grow Group 1api-321143976No ratings yet
- Chike Jeffers - Cultural ConstructivismDocument33 pagesChike Jeffers - Cultural ConstructivismHurto BeatsNo ratings yet
- Religion and Politics in EthiopiaDocument26 pagesReligion and Politics in EthiopiaAbduljelil Sheh Ali KassaNo ratings yet
- Verbs in Present Simple and ContinuousDocument1 pageVerbs in Present Simple and ContinuousDerry RiccardoNo ratings yet
- Assignmen1 PDFDocument5 pagesAssignmen1 PDFMaryam IftikharNo ratings yet
- Peter Sestoft KVL and IT University of Copenhagen: The TeacherDocument8 pagesPeter Sestoft KVL and IT University of Copenhagen: The TeacherArnaeemNo ratings yet
- Spare Part List - GF - NBG 150-125-315Document40 pagesSpare Part List - GF - NBG 150-125-315LenoiNo ratings yet
- Object Oriented Programming in Java Questions and Answers: 1. What Is Oops?Document27 pagesObject Oriented Programming in Java Questions and Answers: 1. What Is Oops?Anees AhmadNo ratings yet
- Sharah Aqeeda-E-Tahawiyyah - Shaykh Muhammad Bin Yahya NinowyDocument205 pagesSharah Aqeeda-E-Tahawiyyah - Shaykh Muhammad Bin Yahya NinowyAtif Hussain Khan100% (2)
- Gr12 Language Litrature Unit 3Document157 pagesGr12 Language Litrature Unit 3Gwyn LapinidNo ratings yet
- Test Instructions: Audio File and Transcript Labels 01 Healthyeatinggroups - 08.01.19 - 500Pm - Group1Document4 pagesTest Instructions: Audio File and Transcript Labels 01 Healthyeatinggroups - 08.01.19 - 500Pm - Group1Adam ElmarouaniNo ratings yet
- Declared Foreign and Primary Keys in RDM Embedded SQLDocument6 pagesDeclared Foreign and Primary Keys in RDM Embedded SQLSarah KhanNo ratings yet
- Structured Programming Using C++ (1) : University of Kufa Collage of Mathematics and Computer ScienceDocument27 pagesStructured Programming Using C++ (1) : University of Kufa Collage of Mathematics and Computer ScienceHasanen MurtadhaNo ratings yet
- H3C Products Catalog 2.0Document37 pagesH3C Products Catalog 2.0Sir GembuLNo ratings yet