You might also like
- 23 PalembangDocument48 pages23 PalembangkumparanNo ratings yet
- 19 PekanbaruDocument53 pages19 PekanbarukumparanNo ratings yet
- 14 MedanDocument205 pages14 MedankumparanNo ratings yet
- 30 JakartaDocument167 pages30 JakartakumparanNo ratings yet
- 21 JambiDocument37 pages21 JambikumparanNo ratings yet
- 17 PadangDocument134 pages17 PadangkumparanNo ratings yet
- 11 Banda AcehDocument67 pages11 Banda AcehkumparanNo ratings yet
- 27 LampungDocument50 pages27 LampungkumparanNo ratings yet
- 44 SurakartaDocument62 pages44 SurakartakumparanNo ratings yet
- 33 BogorDocument100 pages33 BogorkumparanNo ratings yet
- 22 Tanjung PinangDocument25 pages22 Tanjung PinangkumparanNo ratings yet
- 24 Pangkal PinangDocument13 pages24 Pangkal PinangkumparanNo ratings yet
- 41 PurwokertoDocument38 pages41 PurwokertokumparanNo ratings yet
- 25 BengkuluDocument30 pages25 BengkulukumparanNo ratings yet
- 38 BantenDocument60 pages38 BantenkumparanNo ratings yet
- 50 SurabayaDocument167 pages50 SurabayakumparanNo ratings yet
- 34 BandungDocument119 pages34 BandungkumparanNo ratings yet
- 55 MalangDocument111 pages55 Malangkumparan0% (1)
- 75 BanjarmasinDocument44 pages75 BanjarmasinkumparanNo ratings yet
- 42 SemarangDocument97 pages42 SemarangkumparanNo ratings yet
- 65 MataramDocument33 pages65 MataramkumparanNo ratings yet
- 83 PaluDocument49 pages83 PalukumparanNo ratings yet
- 71 PontianakDocument41 pages71 PontianakkumparanNo ratings yet
- 64 SingarajaDocument17 pages64 SingarajakumparanNo ratings yet
- 66 KupangDocument87 pages66 KupangkumparanNo ratings yet
- 58 JemberDocument43 pages58 JemberkumparanNo ratings yet
- 77 SamarindaDocument46 pages77 Samarindakumparan100% (1)
- 78 TarakanDocument13 pages78 TarakankumparanNo ratings yet
- 73 PalangkarayaDocument25 pages73 PalangkarayakumparanNo ratings yet
- 82 MakassarDocument129 pages82 MakassarkumparanNo ratings yet
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (890)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- The Data Journalism Handbook v0.1Document14 pagesThe Data Journalism Handbook v0.1Nicola Hughes0% (1)
- Enom Registration AgreementDocument13 pagesEnom Registration AgreementrofisNo ratings yet
- E Marketing Unit 1 What Is EcommerceDocument14 pagesE Marketing Unit 1 What Is EcommercejayNo ratings yet
- NetLink II System Manual Ver - 3.0 Rev A2 PDFDocument150 pagesNetLink II System Manual Ver - 3.0 Rev A2 PDFAlexander LanesskogNo ratings yet
- 05 Project Setup V8.1.0 enDocument21 pages05 Project Setup V8.1.0 enMaritza AntonioNo ratings yet
- Haiwell Cloud SCADA CatalogDocument2 pagesHaiwell Cloud SCADA Catalogkhulalah chusniatiNo ratings yet
- MCC Winnerlist 02.13Document14 pagesMCC Winnerlist 02.13Frangelyn GozumNo ratings yet
- BassPlayer 2017-06Document68 pagesBassPlayer 2017-06bds100% (7)
- Building A Secure Local Area NetworkDocument71 pagesBuilding A Secure Local Area Networkhosny1234No ratings yet
- Old Castle Shelter Brochure DownloadDocument32 pagesOld Castle Shelter Brochure DownloadmyglasshouseNo ratings yet
- DragonDocument5 pagesDragonabbhabibNo ratings yet
- Oracle Access Manager Admin-GuideDocument374 pagesOracle Access Manager Admin-Guidenarayanan_n1No ratings yet
- Pan LawsuitDocument14 pagesPan LawsuitDan SmithNo ratings yet
- Specialist Switch Requirement BoQDocument6 pagesSpecialist Switch Requirement BoQLohit YadavNo ratings yet
- TM241 ModbusDocument1 pageTM241 ModbusRobertoNo ratings yet
- Chapter2 MalwareDocument82 pagesChapter2 MalwareOscar CopadoNo ratings yet
- Mydoom: Ram NarayanDocument15 pagesMydoom: Ram NarayanTushar SharmaNo ratings yet
- DS Mtera ROADM 74C0226Document6 pagesDS Mtera ROADM 74C0226Ehsan RohaniNo ratings yet
- CCVP BK CCA63467 00 Cvp-Configuration-Guide-1101Document418 pagesCCVP BK CCA63467 00 Cvp-Configuration-Guide-1101raghavendraraomvsNo ratings yet
- TrainingCoursesHandouts V2.04Document13 pagesTrainingCoursesHandouts V2.04Jose D RevueltaNo ratings yet
- Thesis For DefenseDocument15 pagesThesis For DefenseAbby Fernandez100% (1)
- Mobile Banking System by LATNOK CD - Cyclos-ReferenceDocument109 pagesMobile Banking System by LATNOK CD - Cyclos-ReferenceCoko Mirindi MusazaNo ratings yet
- ECDL Module 7 NotesDocument11 pagesECDL Module 7 NotesPetra100% (1)
- TechNet Group Policy Tips and TricksDocument30 pagesTechNet Group Policy Tips and TricksBali JózsefNo ratings yet
- Chp2 e Business Technology BasicDocument75 pagesChp2 e Business Technology BasicNazrinNo ratings yet
- ZTE Cam PDFDocument2 pagesZTE Cam PDFmarsudi.kisworo7533No ratings yet
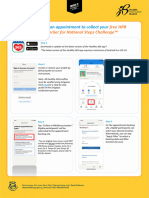
- How To Make An Appointment For Tracker Collection For NSCDocument3 pagesHow To Make An Appointment For Tracker Collection For NSCthuangchristine1989No ratings yet
- Sajjad Hussain: To Acquire A Senior Position As A Software Developer in Fast Paced OrganizationDocument3 pagesSajjad Hussain: To Acquire A Senior Position As A Software Developer in Fast Paced OrganizationSajjad HussainNo ratings yet
- Company Profile...Document15 pagesCompany Profile...tahirNo ratings yet