You might also like
- Lack of Fit 17.46 7 2.49 0.62 0.7267 Not Significant Pure Error 32.02 8 4.00Document3 pagesLack of Fit 17.46 7 2.49 0.62 0.7267 Not Significant Pure Error 32.02 8 4.00Anonymous bnwcKLNo ratings yet
- Analysis of ANOVA: Regression StatisticsDocument6 pagesAnalysis of ANOVA: Regression StatisticsSadi MohaiminulNo ratings yet
- Analysis of ANOVADocument6 pagesAnalysis of ANOVASadi MohaiminulNo ratings yet
- Analysis of ANOVA: Regression StatisticsDocument6 pagesAnalysis of ANOVA: Regression StatisticsSadi MohaiminulNo ratings yet
- Decision ScienceDocument8 pagesDecision Sciencerahulbd4uNo ratings yet
- Chapter 13 HW 13-5Document18 pagesChapter 13 HW 13-5Tushar GoyalNo ratings yet
- 10-Assigment-1 PQTDocument8 pages10-Assigment-1 PQTsamanthaNo ratings yet
- Math 11 Abm BM q1 Week 1Document14 pagesMath 11 Abm BM q1 Week 1Flordilyn DichonNo ratings yet
- CRI CRM CaseDocument1 pageCRI CRM CaseAnubhav JainNo ratings yet
- 3 CE 414 Precipitation ExamplesDocument20 pages3 CE 414 Precipitation ExamplesKhalid KhanNo ratings yet
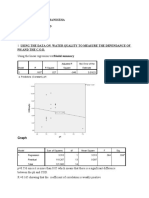
- Regression 1: LN (Cumulative Avg DLH Per Unit) A + (B: Summary OutputDocument3 pagesRegression 1: LN (Cumulative Avg DLH Per Unit) A + (B: Summary OutputElliot RichardNo ratings yet
- Regression Analysis: Answers To Problems and Cases 1. 2Document80 pagesRegression Analysis: Answers To Problems and Cases 1. 2Terry ReynaldoNo ratings yet
- PART B Questions For Business StatsDocument6 pagesPART B Questions For Business StatsjimNo ratings yet
- Homework: Introduction To EViewsDocument4 pagesHomework: Introduction To EViewsmaxNo ratings yet
- Introductory Econometrics A Modern Approach 5Th Edition Wooldridge Solutions Manual Full Chapter PDFDocument27 pagesIntroductory Econometrics A Modern Approach 5Th Edition Wooldridge Solutions Manual Full Chapter PDFcara.miltner626100% (9)
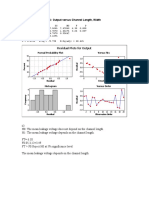
- Two-Way ANOVA: Output Versus Channel Length, Width: Normal Probability Plot Versus FitsDocument1 pageTwo-Way ANOVA: Output Versus Channel Length, Width: Normal Probability Plot Versus FitsFfmohamad NAdNo ratings yet
- Tutorial Covering Topic 11 - Solutions-2-3 (1) - 1Document7 pagesTutorial Covering Topic 11 - Solutions-2-3 (1) - 1RayaNo ratings yet
- Name:Patience. N. Mandizha REG NUMBER:R159077D Assignment 1Document4 pagesName:Patience. N. Mandizha REG NUMBER:R159077D Assignment 1kundayi shavaNo ratings yet
- Use Historical Data FirstDocument14 pagesUse Historical Data FirstKleber NovaisNo ratings yet
- Lab Report: ObjectivesDocument7 pagesLab Report: ObjectivesubaidNo ratings yet
- What We Really Want To Understand Is How Spending Will Vary in A Variety of Decision SettingsDocument34 pagesWhat We Really Want To Understand Is How Spending Will Vary in A Variety of Decision SettingsLouis Webstarr AduNo ratings yet
- Wooldridge 7e Ch17 SMDocument14 pagesWooldridge 7e Ch17 SMsamNo ratings yet
- The Exponential, Gamma and Chi-SquaredDocument22 pagesThe Exponential, Gamma and Chi-SquaredOliver58No ratings yet
- Scatter Diagram: Account Balance Residual PlotDocument3 pagesScatter Diagram: Account Balance Residual PlotYew YaoNo ratings yet
- AssgnDocument15 pagesAssgnMulugetaNo ratings yet
- ISOM2500 Spring 2019 Assignment 4 Suggested Solution: Regression StatisticsDocument4 pagesISOM2500 Spring 2019 Assignment 4 Suggested Solution: Regression StatisticsChing Yin HoNo ratings yet
- Stat 112 D. Small Example of Regression Analysis: Emergency Calls To The New York Auto ClubDocument7 pagesStat 112 D. Small Example of Regression Analysis: Emergency Calls To The New York Auto Clubvijaya bhanuNo ratings yet
- Stat 112 D. Small Example of Regression Analysis: Emergency Calls To The New York Auto ClubDocument7 pagesStat 112 D. Small Example of Regression Analysis: Emergency Calls To The New York Auto Clubvijaya bhanuNo ratings yet
- Shelf-Life FDA OvaisDocument8 pagesShelf-Life FDA OvaisOvais08100% (2)
- Regresión Lineal - II - 14Document42 pagesRegresión Lineal - II - 14Lorraine GavilanesNo ratings yet
- Table NW OUTPUTMEAN MIN DAN MAXDocument4 pagesTable NW OUTPUTMEAN MIN DAN MAXMuhammad Afif WildanNo ratings yet
- Decision ScienceDocument8 pagesDecision ScienceHimanshi YadavNo ratings yet
- Observed No. of Newspaper Ads (X) Number of Bikes Sold (Y)Document6 pagesObserved No. of Newspaper Ads (X) Number of Bikes Sold (Y)Namit BaserNo ratings yet
- Lab 4 AssignmentDocument7 pagesLab 4 AssignmentSeneida BiendarraNo ratings yet
- Answers To Section Six Exercises A Review of Chapters 15 and 16Document4 pagesAnswers To Section Six Exercises A Review of Chapters 15 and 16Jennifer WijayaNo ratings yet
- Lajes 2.4x5.5 - Armadura SuperiorDocument1 pageLajes 2.4x5.5 - Armadura Superiormarceloafborges.engenhariaNo ratings yet
- FNCE 370v10: Assignment 1Document15 pagesFNCE 370v10: Assignment 1smaNo ratings yet
- Lecture5 Mar22 2024Document44 pagesLecture5 Mar22 2024sd.ashifNo ratings yet
- Assignment 3 (Wednesday) - Summer 2021Document4 pagesAssignment 3 (Wednesday) - Summer 2021Paola CastelblancoNo ratings yet
- Example 1Document6 pagesExample 1edwinNo ratings yet
- Design and Analysis of Experiments 3Document20 pagesDesign and Analysis of Experiments 3api-3723257No ratings yet
- Multikolonieritas Dan Autokorelasi (Ketut Wila Tika - 20011060)Document5 pagesMultikolonieritas Dan Autokorelasi (Ketut Wila Tika - 20011060)Gede WirawanNo ratings yet
- Just One Number in A Cell As An Answer Without The Formula Behind It Is Not SufficientDocument10 pagesJust One Number in A Cell As An Answer Without The Formula Behind It Is Not SufficientAhmed Ali NizamaniNo ratings yet
- Gage R&R (Xbar/R) For ResponseDocument5 pagesGage R&R (Xbar/R) For ResponsebhaskarNo ratings yet
- Chem 142 Experiment #1: Atomic Emission: Deadline: Due in Your TA's 3rd-Floor Mailbox 72 Hours After Your Lab EndsDocument2 pagesChem 142 Experiment #1: Atomic Emission: Deadline: Due in Your TA's 3rd-Floor Mailbox 72 Hours After Your Lab Endsapi-339485098No ratings yet
- Chem 142 Kinetics 1 Lab ReportDocument21 pagesChem 142 Kinetics 1 Lab Reportapi-30178223488% (17)
- 3.2 Techniques of Maximizing Total Revenue 3.3 Techniques of Maximizing Output: Minimizing The Average Cost 3.4 Maximization of Profit 3.5 Constrained OptimizationDocument34 pages3.2 Techniques of Maximizing Total Revenue 3.3 Techniques of Maximizing Output: Minimizing The Average Cost 3.4 Maximization of Profit 3.5 Constrained OptimizationBelayneh Ayalew100% (1)
- AssignmentDocument10 pagesAssignmentTharindu DhananjayaNo ratings yet
- Traffic Signal DesignDocument12 pagesTraffic Signal DesignFaizal HakimiNo ratings yet
- Dat Sol 2Document32 pagesDat Sol 2Rafidul IslamNo ratings yet
- Calculation Semi and Quarter BeamDocument8 pagesCalculation Semi and Quarter BeamAsyraf MJNo ratings yet
- Fartok SpssDocument6 pagesFartok SpssNiswatul Ayunil AkhsanNo ratings yet
- Model Sum of Squares DF Mean Square F Sig. 1 Regression 49.210 4 12.302 45.969 .000 Residual 12.846 48 .268 Total 62.056 52 A. Predictors: (Constant), LC, TANG, DEBT, EXT B. Dependent Variable: DPRDocument3 pagesModel Sum of Squares DF Mean Square F Sig. 1 Regression 49.210 4 12.302 45.969 .000 Residual 12.846 48 .268 Total 62.056 52 A. Predictors: (Constant), LC, TANG, DEBT, EXT B. Dependent Variable: DPRMuhammad AliNo ratings yet
- Tutorial Covering Topic 10 - Solutions-Update-3Document4 pagesTutorial Covering Topic 10 - Solutions-Update-3RayaNo ratings yet
- Jordan Reynier RTP Eqc Midterm ExamDocument7 pagesJordan Reynier RTP Eqc Midterm ExamEnergy Trading QUEZELCO 1No ratings yet
- Chapter 5 Exercises LCV - LatestDocument8 pagesChapter 5 Exercises LCV - LatestFarina NajwaNo ratings yet
- Paper14 SolutionDocument25 pagesPaper14 SolutionGregorio VidadNo ratings yet
- Ohm's Law Report - GRADED - Tamim Mahmud - 201800463Document10 pagesOhm's Law Report - GRADED - Tamim Mahmud - 201800463AbdulNo ratings yet
- Quantitative Risk Management: CourseworkDocument14 pagesQuantitative Risk Management: CourseworkMichaelWongNo ratings yet
- Global Capital Markets Summary Q3 2015Document3 pagesGlobal Capital Markets Summary Q3 2015faker fake fakersonNo ratings yet
- DELL Merger AgreementDocument137 pagesDELL Merger Agreementpml1028No ratings yet
- F10 Outline SchuckDocument97 pagesF10 Outline Schuckfaker fake fakersonNo ratings yet
- Lindsay Carson Danielle Wettan: Monday Tuesday Wednesday Thursday Friday Saturday SundayDocument2 pagesLindsay Carson Danielle Wettan: Monday Tuesday Wednesday Thursday Friday Saturday Sundayfaker fake fakersonNo ratings yet
- Gas Range: Defsgg 24 SsDocument20 pagesGas Range: Defsgg 24 Ssfaker fake fakersonNo ratings yet
- Cornhusk Meringues With Corn Mousse: Ingredients InstructionsDocument2 pagesCornhusk Meringues With Corn Mousse: Ingredients Instructionsfaker fake fakerson100% (1)
- The Complete Works of William ShakespeareDocument1 pageThe Complete Works of William Shakespearefaker fake fakersonNo ratings yet
- The Complete Works of William ShakespeareDocument1 pageThe Complete Works of William Shakespearefaker fake fakersonNo ratings yet
- Full Research Paper UitmDocument7 pagesFull Research Paper Uitmhbkgbsund100% (1)
- 13Document18 pages13Shubham TewariNo ratings yet
- Predictionof Pavement Lifeof Flexible Pavementsunderthe Traffic Loading Conditionsof BangladeshDocument12 pagesPredictionof Pavement Lifeof Flexible Pavementsunderthe Traffic Loading Conditionsof BangladeshwilliamNo ratings yet
- Exercises 6 Workshops 9001 - WBP1Document1 pageExercises 6 Workshops 9001 - WBP1rameshqcNo ratings yet
- IFRC FSL Tools PresentationDocument13 pagesIFRC FSL Tools PresentationHussam MothanaNo ratings yet
- Econometrics Assig 1Document13 pagesEconometrics Assig 1ahmed0% (1)
- The Negative Effects of Undecidability in Career Choices ofDocument22 pagesThe Negative Effects of Undecidability in Career Choices ofSenyuriNo ratings yet
- Audit Automation As Control Within Audit FirmsDocument25 pagesAudit Automation As Control Within Audit FirmsVincent RommyNo ratings yet
- Organizational Network Analysis Template PDFDocument10 pagesOrganizational Network Analysis Template PDFmhardi cubacubNo ratings yet
- TWD IC Manual Part I IV. Internal ControlsDocument23 pagesTWD IC Manual Part I IV. Internal ControlsMark Kenneth AcostaNo ratings yet
- PMAY WorkFlowDocument2 pagesPMAY WorkFlowishanhbmehtaNo ratings yet
- Session 3 DistribtionDocument61 pagesSession 3 DistribtionSriya Aishwarya TataNo ratings yet
- ASPRS Positional Accuracy Standards For Digital Geospatial DataDocument55 pagesASPRS Positional Accuracy Standards For Digital Geospatial DataA Ki Asmoro SantoNo ratings yet
- Statistical MethodsDocument77 pagesStatistical MethodsGuruKPO100% (1)
- Unit 1: Concept of Public Policy and Policy AnalysisDocument8 pagesUnit 1: Concept of Public Policy and Policy AnalysisChandan TiwariNo ratings yet
- Consumer BehaviourDocument6 pagesConsumer BehaviourVivek KrNo ratings yet
- AwarenessDocument19 pagesAwarenessJaiShanker CommunicationNo ratings yet
- Bibliogrtaphy AppendixDocument4 pagesBibliogrtaphy AppendixSocialist GopalNo ratings yet
- CH 7 BookDocument48 pagesCH 7 BookTayyaba MunawarNo ratings yet
- An Open Letter To Rowing Canada Aviron Oct 23 2017Document5 pagesAn Open Letter To Rowing Canada Aviron Oct 23 2017The London Free PressNo ratings yet
- 05 (Intro To RBI Inspection)Document24 pages05 (Intro To RBI Inspection)SureshMasilamaniNo ratings yet
- IntroductionDocument2 pagesIntroductionDomnic OnyangoNo ratings yet
- Athanase Iyakaremye - CV PDFDocument20 pagesAthanase Iyakaremye - CV PDFCIBA ItdNo ratings yet
- Kebebush ResearchDocument28 pagesKebebush ResearchBarnababas BeyeneNo ratings yet
- The Problem Background of The StudyDocument9 pagesThe Problem Background of The StudyShairuz Caesar DugayNo ratings yet
- Chapter 2 - F&B ManagementDocument25 pagesChapter 2 - F&B ManagementMohd Faizal Bin AyobNo ratings yet
- Jgeot 15 P 112Document13 pagesJgeot 15 P 112Andrei NardelliNo ratings yet
- MR - ' T ' Test-Independent Sample and Paired SampleDocument26 pagesMR - ' T ' Test-Independent Sample and Paired SamplePrem RajNo ratings yet
- Higher Education Dissertation TopicsDocument5 pagesHigher Education Dissertation TopicsSecondarySchoolReportWritingSiouxFalls100% (1)
- Herman & Renz, 2008Document17 pagesHerman & Renz, 2008Fabio SettiNo ratings yet