You might also like
- Biostatistics Series Module 1: Basics of Biostatistics: ResumenDocument27 pagesBiostatistics Series Module 1: Basics of Biostatistics: ResumenGloria GonzálezNo ratings yet
- Measures of Disease Frequency NOTESDocument22 pagesMeasures of Disease Frequency NOTESSJ JungNo ratings yet
- Ways To Quantify Diseases: Counts of Disease CasesDocument13 pagesWays To Quantify Diseases: Counts of Disease CasesCHIMA ONWUKA MONGNo ratings yet
- Metode PenelitianDocument28 pagesMetode PenelitianyeniNo ratings yet
- Methods Used in EpidemologyDocument53 pagesMethods Used in EpidemologySameera banuNo ratings yet
- Case-Control Study DesignDocument11 pagesCase-Control Study Designmusa onyango obuyaNo ratings yet
- BIO STATISTICS of First SemesterDocument143 pagesBIO STATISTICS of First SemesterRabiaa QureshiNo ratings yet
- Maths Folio BiqDocument21 pagesMaths Folio Biqapi-349814923No ratings yet
- Occupational Exposure and Tuberculosis Among Medical Residents in A High-Burden Setting: An Open-Cohort StudyDocument14 pagesOccupational Exposure and Tuberculosis Among Medical Residents in A High-Burden Setting: An Open-Cohort StudyWisnu Syahputra SuryanullahNo ratings yet
- BiostatsDocument295 pagesBiostatsSuggula Vamsi KrishnaNo ratings yet
- Measurement of Health N DiseaseDocument9 pagesMeasurement of Health N DiseaseOceanChan QdNo ratings yet
- Lecture 1 NOTES Variables and Distributions 2020-21Document11 pagesLecture 1 NOTES Variables and Distributions 2020-21Hannah MatthewsNo ratings yet
- 02.biostatistics EpidemiologyPopulation Health 2 BlocksDocument300 pages02.biostatistics EpidemiologyPopulation Health 2 BlocksSam NickNo ratings yet
- Bias and ConfoundingDocument27 pagesBias and ConfoundingsanjivdasNo ratings yet
- Rockson Ohene Asante 2235026 - Epidemiology Assignment by Pratap Kumar Jena SirDocument11 pagesRockson Ohene Asante 2235026 - Epidemiology Assignment by Pratap Kumar Jena SirRockson Ohene AsanteNo ratings yet
- Epidemiologicstudies 160723192425Document133 pagesEpidemiologicstudies 160723192425Aamir EjazNo ratings yet
- Worksheet Therapy CebmDocument5 pagesWorksheet Therapy CebmZulfan RifqiawanNo ratings yet
- Variability & Bias - 2020-11-27Document69 pagesVariability & Bias - 2020-11-27mirabel IvanaliNo ratings yet
- Lecture Notes On Epidemiology: The Aims of EpidemiologyDocument11 pagesLecture Notes On Epidemiology: The Aims of Epidemiologysagar mittalNo ratings yet
- Chintu Zobolo Epidemeology Assignment 2Document7 pagesChintu Zobolo Epidemeology Assignment 2Chintu ZoboloNo ratings yet
- Output 8 and 9Document11 pagesOutput 8 and 9Angelo ParaoNo ratings yet
- Bias & ConfoundingDocument34 pagesBias & ConfoundingdrvikrantkabirpanthiNo ratings yet
- Biostatistics Word NewDocument43 pagesBiostatistics Word NewMereesha K MoideenNo ratings yet
- AriaForoughi - Bio220 Take Home ExamDocument8 pagesAriaForoughi - Bio220 Take Home ExamAria ForoughiNo ratings yet
- Epidemiological Methods 1Document5 pagesEpidemiological Methods 1Nrs Sani Sule MashiNo ratings yet
- Chapter II - Measurements Used in Epidemiologyoct.22020Document13 pagesChapter II - Measurements Used in Epidemiologyoct.22020Alphine DalgoNo ratings yet
- Sources of Cases: HospitalsDocument19 pagesSources of Cases: HospitalsShaimaa AbdulkadirNo ratings yet
- Clinical Types of Epidemiological StudiesDocument3 pagesClinical Types of Epidemiological StudiesEduardo Proaño100% (1)
- Guide Diagnosis Treatment DecisionsDocument12 pagesGuide Diagnosis Treatment DecisionsJehad Ali Al-ammariNo ratings yet
- Critical Appraisal of Prognostic StudiesDocument4 pagesCritical Appraisal of Prognostic StudiesGhany Hendra WijayaNo ratings yet
- Chapter 1 Introduction BioDocument7 pagesChapter 1 Introduction BiolibavalerieNo ratings yet
- Biostatistics and ExerciseDocument97 pagesBiostatistics and ExerciseMINANI Theobald100% (4)
- Clinical and radiological differences between BCG vaccinated and unvaccinated children with tuberculous meningitisDocument6 pagesClinical and radiological differences between BCG vaccinated and unvaccinated children with tuberculous meningitisDian Ayu Permata SandiNo ratings yet
- Datasets 551982 1490480 Kaggle Target Tables 0 Table Formats and Column Definitions Column DefinitionsDocument5 pagesDatasets 551982 1490480 Kaggle Target Tables 0 Table Formats and Column Definitions Column Definitionsbala bhavani peddiNo ratings yet
- 1 IntroductDocument9 pages1 IntroductAbdu DahlanNo ratings yet
- Comparison of BCG Vaccination at Birth and at 3 MonthDocument3 pagesComparison of BCG Vaccination at Birth and at 3 Monthromeoenny4154No ratings yet
- InfluenzaDocument3 pagesInfluenzaibalsaputraNo ratings yet
- Genetics and The Evaluation of The Febrile Child: EditorialDocument2 pagesGenetics and The Evaluation of The Febrile Child: EditorialYRRVNo ratings yet
- Teoría EconómicaDocument19 pagesTeoría EconómicaMaria Teresa Albino GavilanNo ratings yet
- Nursing Research Step-by-Step: Case-Control StudiesDocument6 pagesNursing Research Step-by-Step: Case-Control StudiesAnkush Kulat PatilNo ratings yet
- Critical Appraisal Jurnal India WiwinDocument6 pagesCritical Appraisal Jurnal India WiwinWindy Atika HapsariNo ratings yet
- Statistical ReasoningDocument4 pagesStatistical ReasoningbodwiserNo ratings yet
- Epidemiology Lab ManualDocument34 pagesEpidemiology Lab ManualDominique SmithNo ratings yet
- 2015 GATE NotesDocument49 pages2015 GATE NotesMariaTheresaTalladorOrbeNo ratings yet
- MPH EocDocument8 pagesMPH EocGalaleldin AliNo ratings yet
- Tutorial 6 Epidemiologi 2018Document8 pagesTutorial 6 Epidemiologi 2018Marcelo100% (1)
- MRCP Passmedicine Statistics 2021Document25 pagesMRCP Passmedicine Statistics 2021shenouda abdelshahidNo ratings yet
- Systematic review of COVID19 prevention in children through vaccinationDocument33 pagesSystematic review of COVID19 prevention in children through vaccinationViswaVittal's TheHiddenWorldNo ratings yet
- Critical ApraisalDocument4 pagesCritical Apraisalfauziah qurrota a'yuniNo ratings yet
- Bio-Statistics and RD Lecture NoteDocument176 pagesBio-Statistics and RD Lecture NotefayanNo ratings yet
- FirstAid 2017 PDFDocument412 pagesFirstAid 2017 PDFSylvia Diamond86% (7)
- Analytical Epidemiology: Case Control StudyDocument32 pagesAnalytical Epidemiology: Case Control StudydeissuzaNo ratings yet
- Epidemiological Study DesignsDocument60 pagesEpidemiological Study DesignsAnn Hill100% (1)
- Vaccine effectiveness case-control studyDocument4 pagesVaccine effectiveness case-control studyAdin RamadhanNo ratings yet
- Rates and RatioDocument54 pagesRates and RatioAngel Borbon GabaldonNo ratings yet
- LIFE COURSE AND DELAY IN ONCOPEDIATRICS REMEDY:case of Burkitt's Lymphoma in Abidjan (Côte D'ivoire)Document10 pagesLIFE COURSE AND DELAY IN ONCOPEDIATRICS REMEDY:case of Burkitt's Lymphoma in Abidjan (Côte D'ivoire)AJHSSR JournalNo ratings yet
- C. Fullpapper - Manuskrip ICOOPH - Agustus 2022Document13 pagesC. Fullpapper - Manuskrip ICOOPH - Agustus 2022Siti NurjanahNo ratings yet
- Epidemiology for Canadian Students: Principles, Methods and Critical AppraisalFrom EverandEpidemiology for Canadian Students: Principles, Methods and Critical AppraisalRating: 1 out of 5 stars1/5 (1)
- Preclinical Behavioral Science and Social Sciences Review 2023: For USMLE Step 1 and COMLEX-USA Level 1From EverandPreclinical Behavioral Science and Social Sciences Review 2023: For USMLE Step 1 and COMLEX-USA Level 1No ratings yet
- List of Academic Vocabulary For Writing Task 1 and 2Document4 pagesList of Academic Vocabulary For Writing Task 1 and 2Nofri RahmadikaNo ratings yet
- List of PrepositionsDocument7 pagesList of PrepositionsNofri RahmadikaNo ratings yet
- 747543Document13 pages747543Nofri RahmadikaNo ratings yet
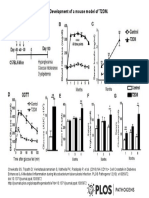
- Journal Ppat 1005972 g001Document1 pageJournal Ppat 1005972 g001Nofri RahmadikaNo ratings yet
- Math League Grade 4 2009Document9 pagesMath League Grade 4 2009Joann DuNo ratings yet
- Corrosion Performance of Alloys in Coal Combustion EnvironmentsDocument11 pagesCorrosion Performance of Alloys in Coal Combustion Environmentsdealer82No ratings yet
- Kinetics P.1 and P.2 SL IB Questions PracticeDocument22 pagesKinetics P.1 and P.2 SL IB Questions Practice2018dgscmtNo ratings yet
- Bentley RM Bridge Advanced Detalii Module AditionaleDocument4 pagesBentley RM Bridge Advanced Detalii Module AditionalephanoanhgtvtNo ratings yet
- Owner's Manual For Porsgrunn Rotary Vane Steering Gear S-1995Document124 pagesOwner's Manual For Porsgrunn Rotary Vane Steering Gear S-1995O olezhaod100% (4)
- 03-LEK-1050 Drill 12.25 Inch SectionDocument4 pages03-LEK-1050 Drill 12.25 Inch SectionDrilling Engineering ChannelNo ratings yet
- Cloud Load Balancing Overview - Google CloudDocument1 pageCloud Load Balancing Overview - Google CloudnnaemekenNo ratings yet
- Fire Magic 2019 Catalog PDFDocument56 pagesFire Magic 2019 Catalog PDFgallegos7386No ratings yet
- Trampas de Vapor AmstrongDocument113 pagesTrampas de Vapor Amstrongjeyjo_64No ratings yet
- 11 Physics Ncert ChapterDocument26 pages11 Physics Ncert ChapterBhumika DNo ratings yet
- Study 3-Phase Circuits and ConnectionsDocument14 pagesStudy 3-Phase Circuits and ConnectionsEdlyn EstevesNo ratings yet
- Antipyretic Ectraction From PlantDocument5 pagesAntipyretic Ectraction From PlantTaufiksyaefulmalikNo ratings yet
- Filtration EquipmentsDocument29 pagesFiltration EquipmentsharijayaramNo ratings yet
- Leader MLV Test-03 30 Oct QPDocument60 pagesLeader MLV Test-03 30 Oct QPInsane insaanNo ratings yet
- Small Wind Turbine For Grid-Connected and Stand-Alone OperationDocument4 pagesSmall Wind Turbine For Grid-Connected and Stand-Alone OperationPranav PiseNo ratings yet
- Iron Carbon Diagram 6Document15 pagesIron Carbon Diagram 6Harris DarNo ratings yet
- EE4534 Modern Distribution Systems With Renewable Resources - OBTLDocument7 pagesEE4534 Modern Distribution Systems With Renewable Resources - OBTLAaron TanNo ratings yet
- Australia: AiracDocument3 pagesAustralia: AiracPero PericNo ratings yet
- Einstein's Discoveries Paved the WayDocument3 pagesEinstein's Discoveries Paved the WayAyman Ahmed CheemaNo ratings yet
- Introduction To InsulationDocument43 pagesIntroduction To InsulationHaridev Moorthy100% (2)
- Technical Data Sheet 3#5 Copper Clad Steel Wire: ITEM CODE - 600305Document2 pagesTechnical Data Sheet 3#5 Copper Clad Steel Wire: ITEM CODE - 600305Victor DoyoganNo ratings yet
- Praepagen HY - CleanersDocument16 pagesPraepagen HY - CleanersCARMEN LINARESNo ratings yet
- PRNCON.EXE Release Notes v11.11.09.1Document4 pagesPRNCON.EXE Release Notes v11.11.09.1Oswaldo GarayNo ratings yet
- Actuarial Valuation LifeDocument22 pagesActuarial Valuation Lifenitin_007100% (1)
- Digital Logic GatesDocument41 pagesDigital Logic Gatessurafel5248No ratings yet
- 08 Catalog Krisbow9 Handtool ProductDocument76 pages08 Catalog Krisbow9 Handtool ProductNajmi BalfasNo ratings yet
- X28HC256Document25 pagesX28HC256schwagerino100% (1)
- Engineering Drawing ScalesDocument18 pagesEngineering Drawing ScalesShadabNo ratings yet
- EEE312 - Midterm Exam - Part 1 - Google FormsDocument4 pagesEEE312 - Midterm Exam - Part 1 - Google FormsDavid Louie BediaNo ratings yet
- An Introduction To Computer Simulation Methods: Harvey Gould, Jan Tobochnik, and Wolfgang Christian July 31, 2005Document8 pagesAn Introduction To Computer Simulation Methods: Harvey Gould, Jan Tobochnik, and Wolfgang Christian July 31, 2005Maria Juliana Ruiz MantillaNo ratings yet