You might also like
- mms9 Workbook 05 Unit5Document46 pagesmms9 Workbook 05 Unit5api-26518088350% (4)
- Where Mathematics Comes FromDocument122 pagesWhere Mathematics Comes FromDragutinAD67% (3)
- Maths in Focus Preliminary 3 UnitDocument861 pagesMaths in Focus Preliminary 3 Unitrahulm98100% (7)
- Direct Instruction Mathematics 5Th Edition Full ChapterDocument41 pagesDirect Instruction Mathematics 5Th Edition Full Chaptertommy.kondracki100100% (25)
- Help Your Kids With Maths PDFDocument266 pagesHelp Your Kids With Maths PDFJulio Cesar100% (2)
- Programming in C++ Prof. Partha Pratim Das Department of Computer Science and Engineering Indian Institute of Technology, Kharagpur Lecture - 07 Stack and Its ApplicationsDocument12 pagesProgramming in C++ Prof. Partha Pratim Das Department of Computer Science and Engineering Indian Institute of Technology, Kharagpur Lecture - 07 Stack and Its Applicationsayush guptaNo ratings yet
- Lec52 PDFDocument15 pagesLec52 PDFabm999100% (1)
- Calculus II - Equations of LinesDocument6 pagesCalculus II - Equations of LinesLiz BenhamouNo ratings yet
- Lec 5Document24 pagesLec 5jehadyamNo ratings yet
- Binary SearchDocument12 pagesBinary SearchpetejuanNo ratings yet
- Lecture Notes On Binary Search: 15-122: Principles of Imperative Computation Frank Pfenning August 31, 2010Document16 pagesLecture Notes On Binary Search: 15-122: Principles of Imperative Computation Frank Pfenning August 31, 2010anuj tattiNo ratings yet
- hw3 14Document7 pageshw3 14Jiyang XieNo ratings yet
- The Math of Deep Learning Neural Networks Simplified (Part 2Document9 pagesThe Math of Deep Learning Neural Networks Simplified (Part 2agalassiNo ratings yet
- Abstract Data StructureDocument18 pagesAbstract Data StructureVedant PatilNo ratings yet
- Lec 6Document20 pagesLec 6ዘረአዳም ዘመንቆረርNo ratings yet
- Applied Deep LearningDocument48 pagesApplied Deep LearningShivich10No ratings yet
- Lec 59Document21 pagesLec 59Elisée NdjabuNo ratings yet
- Dissecting Reinforcement Learning-Part9Document15 pagesDissecting Reinforcement Learning-Part9Sep ElectromecanicaNo ratings yet
- Concept of AlgorithmDocument40 pagesConcept of AlgorithmHari HaraNo ratings yet
- Lec4 5Document14 pagesLec4 5Jagdeep ArryNo ratings yet
- MLT image compression using Huffman codingDocument22 pagesMLT image compression using Huffman codingcosmin_cabaNo ratings yet
- Lec26 PDFDocument16 pagesLec26 PDFarunika palNo ratings yet
- Subtitle NBDocument3 pagesSubtitle NBsanthosh sivaNo ratings yet
- Lec 6Document23 pagesLec 6SharathNo ratings yet
- Nonlinear Dynamical Systems Course IntroductionDocument26 pagesNonlinear Dynamical Systems Course IntroductionAhmet A. YurttadurNo ratings yet
- MITOCW - MITRES2 - 002s10linear - Lec05 - 300k-mp4: ProfessorDocument20 pagesMITOCW - MITRES2 - 002s10linear - Lec05 - 300k-mp4: ProfessorDanielNo ratings yet
- Lecture 23 - MODELING FINITE STATE MACHINESDocument15 pagesLecture 23 - MODELING FINITE STATE MACHINESMagendran PKNo ratings yet
- 06 BinsearchDocument15 pages06 BinsearchRajdip PalNo ratings yet
- Lessson 1Document4 pagesLessson 1Tin-tin MarzanNo ratings yet
- Lec 50Document17 pagesLec 50Ankan BhuniaNo ratings yet
- Functions and GraphsDocument9 pagesFunctions and GraphsFactoran WilfredNo ratings yet
- Linear Regression for Absolute Beginners: A Guide to Implementation in PythonDocument17 pagesLinear Regression for Absolute Beginners: A Guide to Implementation in PythonDerek DegbedzuiNo ratings yet
- Lec 23Document13 pagesLec 23sixfacerajNo ratings yet
- 1.1 All Notes PDFDocument48 pages1.1 All Notes PDFPahonea GigiNo ratings yet
- Lec 13 Module 08 - Default Parameters and Function Overloading (Contd.) (Lecture 13) PDFDocument11 pagesLec 13 Module 08 - Default Parameters and Function Overloading (Contd.) (Lecture 13) PDFNameNo ratings yet
- BIG O NOTATION and ABSTRACT DATA TYPESDocument15 pagesBIG O NOTATION and ABSTRACT DATA TYPESjebjebavestruz8No ratings yet
- Mcs 31Document324 pagesMcs 31Sonali GhanwatNo ratings yet
- Estimating time complexity with Big O, Θ, and Ω notationsDocument9 pagesEstimating time complexity with Big O, Θ, and Ω notationsLovely ChinnaNo ratings yet
- Lec 12Document18 pagesLec 12gabbup13No ratings yet
- PCA and SVMDocument2 pagesPCA and SVMAkshay RajmohanNo ratings yet
- MO's Algorithm ExplainedDocument16 pagesMO's Algorithm ExplainedAmar MalikNo ratings yet
- Calculus I - Derivatives of Inverse Trig FunctionsDocument4 pagesCalculus I - Derivatives of Inverse Trig FunctionsIdrisNo ratings yet
- Cp5191 MLT Unit IIDocument27 pagesCp5191 MLT Unit IIbala_07123No ratings yet
- Module 7 Loops Arrays ListsDocument14 pagesModule 7 Loops Arrays Listssrikrish425No ratings yet
- Data Driven Models FunctionsDocument32 pagesData Driven Models Functionsrt.cseNo ratings yet
- Merge Sort: Divide and ConquerDocument18 pagesMerge Sort: Divide and ConquervinithNo ratings yet
- Finite Element Method Mod-3 Lec-2Document20 pagesFinite Element Method Mod-3 Lec-2PSINGH02No ratings yet
- Module (Calculus)Document18 pagesModule (Calculus)Richard GomezNo ratings yet
- Lec 9Document10 pagesLec 9Rajendra singhNo ratings yet
- Lec 3Document17 pagesLec 3shivaranjaniNo ratings yet
- Data Structures Lecture No. 02: Reading MaterialDocument8 pagesData Structures Lecture No. 02: Reading Materialali razaNo ratings yet
- Aravind Rangamreddy 500195259 cs3Document8 pagesAravind Rangamreddy 500195259 cs3Aravind Kumar ReddyNo ratings yet
- Lec 34 Module 19 - Overloading Operator For User Defined Types - Part - II (Lecture 34) PDFDocument17 pagesLec 34 Module 19 - Overloading Operator For User Defined Types - Part - II (Lecture 34) PDFNameNo ratings yet
- Mathematical ModelingDocument8 pagesMathematical ModelingMourougapragash SubramanianNo ratings yet
- 1.1 Concept of AlgorithmDocument46 pages1.1 Concept of Algorithmrajat322No ratings yet
- CSE 211 Lecture Notes - Algorithm Analysis and Performance PredictionDocument8 pagesCSE 211 Lecture Notes - Algorithm Analysis and Performance PredictionRamya PrabaNo ratings yet
- Data Structure Module 1Document10 pagesData Structure Module 1ssreeram1312.tempNo ratings yet
- Lec 15Document27 pagesLec 15shubhamNo ratings yet
- FunctionsDocument17 pagesFunctionsRYAN MAGBANUANo ratings yet
- MITOCW - MITRES2 - 002s10nonlinear - Lec12 - 300k-mp4: NarratorDocument16 pagesMITOCW - MITRES2 - 002s10nonlinear - Lec12 - 300k-mp4: NarratorBastian DewiNo ratings yet
- CalcI AreaProblemDocument12 pagesCalcI AreaProblemJose V. Chunga MunaycoNo ratings yet
- BCIT MANUAL - STUDENT COPY-Bio-Medical-11-16Document6 pagesBCIT MANUAL - STUDENT COPY-Bio-Medical-11-16Anonymous naEAR9adNo ratings yet
- By Observing Patterns at F 1.2 GHZ, F 2.4 GHZ, F 3.6 GHZ, F 4.8 GHZ, We Get RespectivelyDocument6 pagesBy Observing Patterns at F 1.2 GHZ, F 2.4 GHZ, F 3.6 GHZ, F 4.8 GHZ, We Get RespectivelyAnonymous naEAR9adNo ratings yet
- CST - Studiosuitemanual 10 14Document5 pagesCST - Studiosuitemanual 10 14Anonymous naEAR9adNo ratings yet
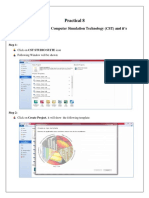
- Practical 8: Aim: Introduction To Computer Simulation Technology (CST) and It's InstallationDocument4 pagesPractical 8: Aim: Introduction To Computer Simulation Technology (CST) and It's InstallationAnonymous naEAR9adNo ratings yet
- Government Polytechnic Lab Manual Covers Computer BasicsDocument5 pagesGovernment Polytechnic Lab Manual Covers Computer BasicsAnonymous naEAR9adNo ratings yet
- ASSIGNMENT:3 SUBJECT: MW (3351103) : Gireeja D. AminDocument1 pageASSIGNMENT:3 SUBJECT: MW (3351103) : Gireeja D. AminAnonymous naEAR9adNo ratings yet
- BCIT MANUAL - STUDENT COPY-Bio-Medical-17-22Document6 pagesBCIT MANUAL - STUDENT COPY-Bio-Medical-17-22Anonymous naEAR9adNo ratings yet
- BCIT MANUAL - STUDENT COPY-Bio-Medical-31-36Document6 pagesBCIT MANUAL - STUDENT COPY-Bio-Medical-31-36Anonymous naEAR9adNo ratings yet
- BCIT MANUAL - STUDENT COPY-Bio-Medical-23-30Document8 pagesBCIT MANUAL - STUDENT COPY-Bio-Medical-23-30Anonymous naEAR9adNo ratings yet
- Cmos 1Document76 pagesCmos 1Anonymous naEAR9adNo ratings yet
- 3300003environment Conservation and Hazard ManagementDocument4 pages3300003environment Conservation and Hazard ManagementK Nirmala Anantapur100% (1)
- Program Outcomes (Pos) :: Electronic and Communication EngineeringDocument10 pagesProgram Outcomes (Pos) :: Electronic and Communication EngineeringAnonymous naEAR9adNo ratings yet
- Industry - Sheet 2021-22Document8 pagesIndustry - Sheet 2021-22Anonymous naEAR9adNo ratings yet
- AWP Unit II BDocument60 pagesAWP Unit II BChakravarthy Vedula VSSSNo ratings yet
- Cupboard 31 Rack RecordsDocument148 pagesCupboard 31 Rack RecordsAnonymous naEAR9adNo ratings yet
- Over 12,000 Books OrganizedDocument1,109 pagesOver 12,000 Books OrganizedAnonymous naEAR9adNo ratings yet
- Session 10 - Introduction To Patent 2 - 16-07-2020Document49 pagesSession 10 - Introduction To Patent 2 - 16-07-2020Anonymous naEAR9adNo ratings yet
- Antenna - Notes Chapter 1-5-41-45Document5 pagesAntenna - Notes Chapter 1-5-41-45Anonymous naEAR9adNo ratings yet
- Translated Office OrderDocument3 pagesTranslated Office OrderAnonymous naEAR9adNo ratings yet
- Antenna - Notes Chapter 1-5-36-40Document5 pagesAntenna - Notes Chapter 1-5-36-40Anonymous naEAR9adNo ratings yet
- Antenna - Notes Chapter 1-5-41-45Document5 pagesAntenna - Notes Chapter 1-5-41-45Anonymous naEAR9adNo ratings yet
- Antenna - Notes Chapter 1-5-46-50Document5 pagesAntenna - Notes Chapter 1-5-46-50Anonymous naEAR9adNo ratings yet
- Antenna - Notes Chapter 1-5-51-55Document5 pagesAntenna - Notes Chapter 1-5-51-55Anonymous naEAR9adNo ratings yet
- Antenna - Notes Chapter 1-5-31-35Document5 pagesAntenna - Notes Chapter 1-5-31-35Anonymous naEAR9adNo ratings yet
- Antenna - Notes Chapter 1-5-46-50Document5 pagesAntenna - Notes Chapter 1-5-46-50Anonymous naEAR9adNo ratings yet
- Antenna - Notes Chapter 1-5-31-40Document10 pagesAntenna - Notes Chapter 1-5-31-40Anonymous naEAR9adNo ratings yet
- Antenna - Notes Chapter 1-5-26-30Document5 pagesAntenna - Notes Chapter 1-5-26-30Anonymous naEAR9adNo ratings yet
- Antenna - Notes Chapter 1-5-26-30Document5 pagesAntenna - Notes Chapter 1-5-26-30Anonymous naEAR9adNo ratings yet
- Antenna - Notes Chapter 1-5-16-20Document5 pagesAntenna - Notes Chapter 1-5-16-20Anonymous naEAR9adNo ratings yet
- Antenna - Notes Chapter 1-5-21-25Document5 pagesAntenna - Notes Chapter 1-5-21-25Anonymous naEAR9adNo ratings yet
- A Detailed Lesson Plan in MathematicsDocument4 pagesA Detailed Lesson Plan in MathematicsCarlo Osorio88% (8)
- ALGEBRA 1: 1.4-Numerical Properties & ExpressionsDocument4 pagesALGEBRA 1: 1.4-Numerical Properties & ExpressionsCaty LiesekeNo ratings yet
- Math6 LasDocument3 pagesMath6 LasEdna Gamo100% (1)
- (Mind, Meaning and Metaphysics) Keith Hossack - Knowledge and The Philosophy of Number - What Numbers Are and How They Are Known-Bloomsbury Academic (2020)Document217 pages(Mind, Meaning and Metaphysics) Keith Hossack - Knowledge and The Philosophy of Number - What Numbers Are and How They Are Known-Bloomsbury Academic (2020)Reinaldo Elias De Souza JuniorNo ratings yet
- Mae4326 Lesson Plan 1 TemplateDocument7 pagesMae4326 Lesson Plan 1 Templateapi-445512320No ratings yet
- Chapter 8 (Complex Numbers)Document8 pagesChapter 8 (Complex Numbers)Naledi MashishiNo ratings yet
- Direct Variation in MathematicsDocument17 pagesDirect Variation in MathematicsMarivy SilaoNo ratings yet
- Image Transform The Development of Two Dimensional (2-D) Transforms and Their PropertiesDocument34 pagesImage Transform The Development of Two Dimensional (2-D) Transforms and Their PropertiesumasistaNo ratings yet
- Chapter 3Document6 pagesChapter 3May Yadanar NweNo ratings yet
- Original PDF A Problem Solving Approach To Mathematics For Elementary School Teachers 12th Edition PDFDocument42 pagesOriginal PDF A Problem Solving Approach To Mathematics For Elementary School Teachers 12th Edition PDFalice.bueckers152100% (31)
- C 02 Algebra and EquationsDocument50 pagesC 02 Algebra and EquationsAn Ninh VũNo ratings yet
- Multiplication Worksheets Math AnticsDocument6 pagesMultiplication Worksheets Math Anticsapi-236323101No ratings yet
- Derivative Exercises Graphs and TablesDocument2 pagesDerivative Exercises Graphs and TablesSherrell Blankenship-BrownNo ratings yet
- TST m3 Tahap 1 & 2Document11 pagesTST m3 Tahap 1 & 2Kogila Vaani BalakeristananNo ratings yet
- MATH 8 - Q1 - Mod2Document17 pagesMATH 8 - Q1 - Mod2ALLYSSA MAE PELONIANo ratings yet
- Java Programming For Human BeingsDocument80 pagesJava Programming For Human BeingsMiguel León NogueraNo ratings yet
- A Fortran 90 Program To Solve A Set of Linear Equations by UsingDocument3 pagesA Fortran 90 Program To Solve A Set of Linear Equations by Usingnadher albaghdadiNo ratings yet
- Math UnitDocument7 pagesMath Unitapi-259576410No ratings yet
- Chapter 6Document58 pagesChapter 6api-262532023No ratings yet
- Lesson 25 M6Q1LC15.1 DLLDocument6 pagesLesson 25 M6Q1LC15.1 DLLMelinda RafaelNo ratings yet
- Mental Math Tricks To Impress Your FriendsDocument8 pagesMental Math Tricks To Impress Your Friendsdaveloutan100% (1)
- Math HTMLDocument33 pagesMath HTMLVinod SolankiNo ratings yet
- Matrix - MELCs - MATHDocument12 pagesMatrix - MELCs - MATHKimberly Anne Arizala BaculandoNo ratings yet
- Number All LevelsDocument4 pagesNumber All LevelsMohd Zulkhairi AbdullahNo ratings yet
- English-5-Q3 Module 7 v2Document27 pagesEnglish-5-Q3 Module 7 v2Eiyoh Emmanuel BrizoNo ratings yet