You might also like
- MS 14-2009 e PrintDocument13 pagesMS 14-2009 e PrinteditorofijtosNo ratings yet
- C DockerDocument14 pagesC Dockerharicoolguy111No ratings yet
- Dock Around The Clock - Current Status of Small MoleculeDocument11 pagesDock Around The Clock - Current Status of Small Moleculetaoufik akabliNo ratings yet
- 2015 J Cheminform 7 18Document10 pages2015 J Cheminform 7 18mbrylinskiNo ratings yet
- Single-Step Deep Reinforcement Learning For Two-And Three-Dimensional Optimal Shape DesignDocument22 pagesSingle-Step Deep Reinforcement Learning For Two-And Three-Dimensional Optimal Shape DesignbuntarNo ratings yet
- CCC C C: C CC CC CCC C C !CCC CC !CCCC "CDocument25 pagesCCC C C: C CC CC CCC C C !CCC CC !CCCC "CMudit MisraNo ratings yet
- Torres 2019 DockingrevDocument29 pagesTorres 2019 DockingrevPedro Henrique Monteiro TorresNo ratings yet
- Morris 2009 Autodockv4Document7 pagesMorris 2009 Autodockv4shinigamigirl69No ratings yet
- 26 Augmented Hill-Climb Increases Reinforcement Learning Efficiency For Language-Based de Novo Molecule Generation.Document22 pages26 Augmented Hill-Climb Increases Reinforcement Learning Efficiency For Language-Based de Novo Molecule Generation.felicitywxxNo ratings yet
- 9th SemDocument22 pages9th SemVinish ChoudaryNo ratings yet
- Motion Planning of Fully Actuated Closed Kinematic Chains With Revolute Joints A Comparative AnalysisDocument8 pagesMotion Planning of Fully Actuated Closed Kinematic Chains With Revolute Joints A Comparative Analysisasabxkh74139291 czryo7165No ratings yet
- Ddfa PDFDocument11 pagesDdfa PDFAdrián RodríguezNo ratings yet
- Sustainability 14 02761 v2Document22 pagesSustainability 14 02761 v2LinkisNo ratings yet
- A Hybrid Cuckoo Search and Differential Evolution Approach To Protein-Ligand DockingDocument13 pagesA Hybrid Cuckoo Search and Differential Evolution Approach To Protein-Ligand DockingrasminojNo ratings yet
- Application Methods For Genetic Algorithms For The Search of Feed Positions in The Design of A Reactive Distillation ProcessDocument10 pagesApplication Methods For Genetic Algorithms For The Search of Feed Positions in The Design of A Reactive Distillation ProcessAdam BuchananNo ratings yet
- Bound constraints handling in DE algorithms experimental studyDocument40 pagesBound constraints handling in DE algorithms experimental studyFreddy Garcia FuentesNo ratings yet
- 1 s2.0 S0360544217317127 MainDocument11 pages1 s2.0 S0360544217317127 Mainhumzafarrukh7No ratings yet
- Belghait May 2018Document20 pagesBelghait May 2018Cherif SI MOUSSANo ratings yet
- Molecular DockingDocument6 pagesMolecular DockingadityasathyanNo ratings yet
- Analog Circuit Optimization System Based On Hybrid Evolutionary AlgorithmsDocument12 pagesAnalog Circuit Optimization System Based On Hybrid Evolutionary AlgorithmsashishmanyanNo ratings yet
- Clustering Techniques and Their Applications in EngineeringDocument16 pagesClustering Techniques and Their Applications in EngineeringIgor Demetrio100% (1)
- Research Article: An Improved Method of Particle Swarm Optimization For Path Planning of Mobile RobotDocument12 pagesResearch Article: An Improved Method of Particle Swarm Optimization For Path Planning of Mobile Robotmarcio pivelloNo ratings yet
- Cuckoo Search Algorithm For Capacitated Vehicle Routing ProblemDocument9 pagesCuckoo Search Algorithm For Capacitated Vehicle Routing Problem-Ayomi Sii Sasmito-No ratings yet
- Model Reduction High DimensionDocument20 pagesModel Reduction High DimensionLei TuNo ratings yet
- Open Source MATLAB Toolkit for Consistent Discretizations on Complex GridsDocument38 pagesOpen Source MATLAB Toolkit for Consistent Discretizations on Complex GridsCarol Paola GalvisNo ratings yet
- COMKAT simplifies complex modeling of nuclear medicine dataDocument10 pagesCOMKAT simplifies complex modeling of nuclear medicine dataIvoPetrovNo ratings yet
- Autodock4 and Autodocktools4: Automated Docking With Selective Receptor FlexibilityDocument7 pagesAutodock4 and Autodocktools4: Automated Docking With Selective Receptor FlexibilitypoojaNo ratings yet
- PINN - The Neural Particle Method - An Updated Lagrangian Physics Informed Neural Network For Computational Fluid DynamicsDocument15 pagesPINN - The Neural Particle Method - An Updated Lagrangian Physics Informed Neural Network For Computational Fluid Dynamicsjulio.dutraNo ratings yet
- Jurnal 3 Halaman 2Document1 pageJurnal 3 Halaman 2MuhammadIhsanNo ratings yet
- Automated Docking Using A LGADocument24 pagesAutomated Docking Using A LGAtaoufik akabliNo ratings yet
- Dechter Constraint ProcessingDocument40 pagesDechter Constraint Processingnani subrNo ratings yet
- Comparison of Metamodel Approaches for Robust Design OptimizationDocument14 pagesComparison of Metamodel Approaches for Robust Design OptimizationRajib ChowdhuryNo ratings yet
- Ruess2013 PDFDocument36 pagesRuess2013 PDFRizki TriwulandaNo ratings yet
- A Self-Adaptive Deep Leearning Algorithm For Accelerating Multicomponent Flash CalculationDocument19 pagesA Self-Adaptive Deep Leearning Algorithm For Accelerating Multicomponent Flash CalculationCarolina PiedrahitaNo ratings yet
- Olanders2020 Article ConformationalAnalysisOfMacrocDocument22 pagesOlanders2020 Article ConformationalAnalysisOfMacrocTsibela MofokengNo ratings yet
- Processes: Optimization of Reaction Selectivity Using CFD-Based Compartmental Modeling and Surrogate-Based OptimizationDocument20 pagesProcesses: Optimization of Reaction Selectivity Using CFD-Based Compartmental Modeling and Surrogate-Based OptimizationMurali GoshikaNo ratings yet
- Modelling Clustering of Wireless Sensor Networks With Synchronised Hyperedge ReplacementDocument15 pagesModelling Clustering of Wireless Sensor Networks With Synchronised Hyperedge Replacement- -No ratings yet
- Robust Multi-Model Predictive Controller for Distributed Parameter SystemsDocument50 pagesRobust Multi-Model Predictive Controller for Distributed Parameter SystemsCristian CanazaNo ratings yet
- ObbDocument27 pagesObbSachin GNo ratings yet
- New Hybrid CG Method for Unconstrained OptimizationDocument10 pagesNew Hybrid CG Method for Unconstrained OptimizationMaulana MalikNo ratings yet
- Qsar Thesis PDFDocument5 pagesQsar Thesis PDFstephanierobertscharleston100% (2)
- Molecular Docking MethodsDocument7 pagesMolecular Docking MethodsKOUSHIK SARKERNo ratings yet
- Prediction of ITQ-21 Zeolite Phase Crystallinity: Parametric Versus Non-Parametric StrategiesDocument18 pagesPrediction of ITQ-21 Zeolite Phase Crystallinity: Parametric Versus Non-Parametric StrategiesbaumeslNo ratings yet
- Three-Dimensional Classification Structure-Activity Relationship Analysis Using Convolutional Neural NetworkDocument8 pagesThree-Dimensional Classification Structure-Activity Relationship Analysis Using Convolutional Neural NetworkWinwin Karunia DiningsihNo ratings yet
- A Comparison of Heuristics Search Algorithms For Molecular DockingDocument18 pagesA Comparison of Heuristics Search Algorithms For Molecular DockingMudit MisraNo ratings yet
- Receptor-Ligand Molecular DockingDocument13 pagesReceptor-Ligand Molecular Dockingb.abdallah.souhaNo ratings yet
- MCMC Data Association and Sparse Factorization Updating For Real Time Multitarget Tracking With Merged and Multiple MeasurementsDocument13 pagesMCMC Data Association and Sparse Factorization Updating For Real Time Multitarget Tracking With Merged and Multiple MeasurementsAlberto Kobon GroundNo ratings yet
- Assessement of Flexible DockingDocument13 pagesAssessement of Flexible Dockingb.abdallah.souhaNo ratings yet
- Autodock2 4 UserguideDocument48 pagesAutodock2 4 UserguidePowellAbogadoNo ratings yet
- Estimating one-diode-PV Model Using Autonomous Groups Particle Swarm OptimizationDocument9 pagesEstimating one-diode-PV Model Using Autonomous Groups Particle Swarm OptimizationIAES IJAINo ratings yet
- Applied Sciences: Multi-Objective Electric Vehicles Scheduling Using Elitist Non-Dominated Sorting Genetic AlgorithmDocument18 pagesApplied Sciences: Multi-Objective Electric Vehicles Scheduling Using Elitist Non-Dominated Sorting Genetic AlgorithmLIEW HUI FANG UNIMAPNo ratings yet
- Predicting Retrosynthetic Reaction Using Self-Corrected Transformer Neural Networks PDFDocument19 pagesPredicting Retrosynthetic Reaction Using Self-Corrected Transformer Neural Networks PDFMarce VeraNo ratings yet
- Process Modeling in The Pharmaceutical Industry Using The Discrete Element MethodDocument29 pagesProcess Modeling in The Pharmaceutical Industry Using The Discrete Element MethodRonaldo MenezesNo ratings yet
- Development of A Theoretical Delay Model For HeterDocument20 pagesDevelopment of A Theoretical Delay Model For HeterAmul ShresthaNo ratings yet
- An MTIDD Based Firewall: Using Decision Diagrams For Packet FilteringDocument23 pagesAn MTIDD Based Firewall: Using Decision Diagrams For Packet Filteringkaushik247No ratings yet
- Two-layer Surrogate Model for Expensive PSODocument22 pagesTwo-layer Surrogate Model for Expensive PSOAndy SyaputraNo ratings yet
- Machine-Learning Methods For Ligand-Protein Molecular DockingDocument17 pagesMachine-Learning Methods For Ligand-Protein Molecular DockingInes MejriNo ratings yet
- Applsci 11 03175Document14 pagesApplsci 11 03175Olivia OeyNo ratings yet
- Archive of SID: Novel Fusion Approaches For The Dissolved Gas Analysis of Insulating OilDocument12 pagesArchive of SID: Novel Fusion Approaches For The Dissolved Gas Analysis of Insulating OilelshamikNo ratings yet
- High Performance Computing and the Discrete Element Model: Opportunity and ChallengeFrom EverandHigh Performance Computing and the Discrete Element Model: Opportunity and ChallengeNo ratings yet
- Types and Mechanisms of Action of AntidotesDocument30 pagesTypes and Mechanisms of Action of Antidotesnareshph28No ratings yet
- Ishizaka 1981Document6 pagesIshizaka 1981nareshph28No ratings yet
- Molbank 2016 M911 s001 PDFDocument8 pagesMolbank 2016 M911 s001 PDFnareshph28No ratings yet
- Turbidimetric Microbiological Assay of Amino AcidsDocument11 pagesTurbidimetric Microbiological Assay of Amino Acidsnareshph28No ratings yet
- Instruction ManualDocument2 pagesInstruction Manualnareshph28No ratings yet
- Sop-Qa-038-00-Stability StudiesDocument22 pagesSop-Qa-038-00-Stability Studiesnareshph28No ratings yet
- CSHCWHDocument16 pagesCSHCWHChrist FarandyNo ratings yet
- Installation InstructionsDocument3 pagesInstallation Instructionsnareshph28No ratings yet
- Sop-Qa-038-00-Stability StudiesDocument22 pagesSop-Qa-038-00-Stability Studiesnareshph28No ratings yet
- Sop-Qa-038-00-Stability StudiesDocument22 pagesSop-Qa-038-00-Stability Studiesnareshph28No ratings yet
- Nucleic Acids and Their MetabolismDocument58 pagesNucleic Acids and Their Metabolismnareshph28100% (1)
- Microbiological Assay For Vitamin B PDFDocument9 pagesMicrobiological Assay For Vitamin B PDFnareshph28No ratings yet
- The Narcotic Drugs and Psychotropic SubstancesDocument25 pagesThe Narcotic Drugs and Psychotropic Substancesnareshph28No ratings yet
- Stotras Krishnasrikanth in Mahishasuramardini Stotram in TelDocument17 pagesStotras Krishnasrikanth in Mahishasuramardini Stotram in Telnareshph28No ratings yet
- Academic - Calender - UG & PG - 2017-18Document2 pagesAcademic - Calender - UG & PG - 2017-18nareshph28No ratings yet
- Chem Sketch GuideDocument12 pagesChem Sketch GuidennnxxxnnnNo ratings yet
- Notes 14C Nmr02Document11 pagesNotes 14C Nmr02Bava BohurudeenNo ratings yet
- Higher Algebra - Hall & KnightDocument593 pagesHigher Algebra - Hall & KnightRam Gollamudi100% (2)
- Hanuman DandakamDocument2 pagesHanuman DandakamlnbandiNo ratings yet
- Medicinal and Toilet Preparations Act 1955 RulesDocument40 pagesMedicinal and Toilet Preparations Act 1955 Rulesnareshph2850% (2)
- The Havan AgnihotraDocument16 pagesThe Havan Agnihotradiegomoram0% (1)
- Medicinal and Toilet Preparations Act 1955 RulesDocument40 pagesMedicinal and Toilet Preparations Act 1955 Rulesnareshph2850% (2)
- The Havan AgnihotraDocument16 pagesThe Havan Agnihotradiegomoram0% (1)
- In Silico Drug Discovery Limitations and ApplicationsDocument29 pagesIn Silico Drug Discovery Limitations and Applicationsnareshph28No ratings yet
- BiochemistryDocument383 pagesBiochemistrybalajimeie92% (12)
- 13 ReferencesDocument13 pages13 Referencesnareshph28No ratings yet
- ACE-Inhibitors Treat Hypertension by Blocking Angiotensin-Converting Enzyme (ACEDocument32 pagesACE-Inhibitors Treat Hypertension by Blocking Angiotensin-Converting Enzyme (ACEnareshph28No ratings yet
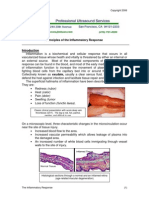
- Patho Chapter Inflammatory ResponseDocument8 pagesPatho Chapter Inflammatory ResponseBandaru RahmatariNo ratings yet
- Advanced Drug Design and Development A Medicinal Chemistry ApproachDocument151 pagesAdvanced Drug Design and Development A Medicinal Chemistry Approachshivachem18No ratings yet
- 91011-S. GargDocument5 pages91011-S. Gargnareshph28No ratings yet
- Doran 2013Document38 pagesDoran 2013Nurul NadianaNo ratings yet
- Syllabus Supplement For StudentsDocument5 pagesSyllabus Supplement For StudentsMutasem SinnokrotNo ratings yet
- Absorption Cooling and On - Energy Dynamics LimitedDocument122 pagesAbsorption Cooling and On - Energy Dynamics Limitedjamesbrown100100% (2)
- Why Is Moist Air Less Dense Than Dry AirDocument2 pagesWhy Is Moist Air Less Dense Than Dry AirMehul ChaturvediNo ratings yet
- Anil - Confined Metastable 2 Line Ferrihydrite For Affordable Pointof Use Arsenic SupportDocument30 pagesAnil - Confined Metastable 2 Line Ferrihydrite For Affordable Pointof Use Arsenic SupportRamesh SoniNo ratings yet
- Gas Dispersed EquipmentDocument20 pagesGas Dispersed EquipmentAshish SrivastavaNo ratings yet
- GT2011-46380 Implementation of A Multi Zone Radiation Method in A Low Nox Gas Turbine Combustion Chamber Conceptual SimulatorDocument10 pagesGT2011-46380 Implementation of A Multi Zone Radiation Method in A Low Nox Gas Turbine Combustion Chamber Conceptual SimulatorMarcos Noboru ArimaNo ratings yet
- 201ufrep ME ISRO2020Paper 2020 PDFDocument42 pages201ufrep ME ISRO2020Paper 2020 PDFkiran kittuNo ratings yet
- Spe 125413 MSDocument14 pagesSpe 125413 MStruth sayer100% (1)
- Polypropylene Carbonate ProductionDocument1 pagePolypropylene Carbonate ProductionBramJanssen76No ratings yet
- POLYMER MW CALCULATIONSDocument19 pagesPOLYMER MW CALCULATIONSks kNo ratings yet
- Calculations Involving Masses 1 MSDocument8 pagesCalculations Involving Masses 1 MSStabs ExtraNo ratings yet
- Unit 6 - Week 03: Mass Transfer Coefficient and Interface Mass TransferDocument3 pagesUnit 6 - Week 03: Mass Transfer Coefficient and Interface Mass TransferSandra GilbertNo ratings yet
- FORINSTDocument7 pagesFORINSTYoMomma PinkyNo ratings yet
- Complexing Capacity of Salicylaldoxime With Nickel and Zinc by Differential Pulse PolarographyDocument3 pagesComplexing Capacity of Salicylaldoxime With Nickel and Zinc by Differential Pulse PolarographyInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Nuts and Bolts of First-Principles Simulation: Plane WavesDocument33 pagesNuts and Bolts of First-Principles Simulation: Plane WavesFahd ElmourabitNo ratings yet
- Chem XRD Diff Lecture 6Document71 pagesChem XRD Diff Lecture 6Công Bùi ChíNo ratings yet
- Janssens BCC09 PaperDocument11 pagesJanssens BCC09 PaperVyto BabrauskasNo ratings yet
- Lattice Enthalpies and Ionic BondingDocument3 pagesLattice Enthalpies and Ionic BondingShahnaz AhmedNo ratings yet
- Unit 8 Packet KeyDocument21 pagesUnit 8 Packet KeyHiddenNo ratings yet
- 56-Khalil - Qartar Stadium Case StudyDocument69 pages56-Khalil - Qartar Stadium Case StudyHnin PwintNo ratings yet
- SHIP BOILERS WATERDocument94 pagesSHIP BOILERS WATERalvarompsardinhaNo ratings yet
- 2006 Keiyo District Paper 1Document4 pages2006 Keiyo District Paper 1dkavitiNo ratings yet
- Sonochemistry PDFDocument46 pagesSonochemistry PDFLupita GarzaNo ratings yet
- Thomson Atom Model: Physics NotesDocument13 pagesThomson Atom Model: Physics NotesEs ENo ratings yet
- PrinciplesDocument608 pagesPrinciplesspeedkillz83% (6)
- Protons - Neutrons - and ElectronsDocument2 pagesProtons - Neutrons - and ElectronsshaniNo ratings yet
- Ice Load For This Floor 1.0Kn/M2: M/L DWG No. H-11400-1360-1209Document1 pageIce Load For This Floor 1.0Kn/M2: M/L DWG No. H-11400-1360-1209Chiều TànNo ratings yet
- Chemical Bonding - DPP-10 (Of Lec-16) - Arjuna Neet 2024Document3 pagesChemical Bonding - DPP-10 (Of Lec-16) - Arjuna Neet 2024arshiNo ratings yet
- Practical Physical Chemistry (II) Laboratory ManualDocument25 pagesPractical Physical Chemistry (II) Laboratory Manualabdu30esNo ratings yet