You might also like
- REGRESIÓNDocument54 pagesREGRESIÓNHector Mamani CutipaNo ratings yet
- VC - Regresión y Correl Lineal SimpDocument25 pagesVC - Regresión y Correl Lineal SimpVamos Tu PuedesNo ratings yet
- AAD Sesión Virtual DeterminacionDocument5 pagesAAD Sesión Virtual DeterminacionjessicaNo ratings yet
- 09 Semana - Modelo de Regresión Lineal SimpleDocument77 pages09 Semana - Modelo de Regresión Lineal SimpleJOSUE MANUEL VALDERA HOSTIANo ratings yet
- DeberDocument13 pagesDeberKaren Samantha GNo ratings yet
- Regresion LINEALDocument54 pagesRegresion LINEALRodrigo Aycache ChavezNo ratings yet
- Matereial de Apoyo Sobre Econometría y Estadistica InferencialDocument22 pagesMatereial de Apoyo Sobre Econometría y Estadistica InferencialIng. Luis Fernando Restrepo100% (2)
- Tarea 2. Microeconomía - Oferta, Demanda y Punto de EquilibrioDocument4 pagesTarea 2. Microeconomía - Oferta, Demanda y Punto de EquilibrioNohemi OlvloNo ratings yet
- Biofisica IiDocument8 pagesBiofisica IiKarla AlejandraNo ratings yet
- Sesión 13Document12 pagesSesión 13LUCHI100% (1)
- Proes - Semana 13Document19 pagesProes - Semana 13Dayanna MendozaNo ratings yet
- Estadísticas de La RegresiónDocument18 pagesEstadísticas de La RegresiónDanielaPerezCastroNo ratings yet
- Gestión de La Demanda - Parte 4Document27 pagesGestión de La Demanda - Parte 4Yukio AsatoNo ratings yet
- CORRELACION Y CORRELACION PARCIAL - UnlockedDocument13 pagesCORRELACION Y CORRELACION PARCIAL - UnlockedDANNY SANCHEZNo ratings yet
- Tracian TIR VANDocument4 pagesTracian TIR VANNathalyArdilaNo ratings yet
- GD Sesion 06 Guia Practica Ejercicio 03-Impresion A4hDocument1 pageGD Sesion 06 Guia Practica Ejercicio 03-Impresion A4hjNo ratings yet
- Suponga Que Brígida y Érica Gastan Su Renta en Dos BienesDocument3 pagesSuponga Que Brígida y Érica Gastan Su Renta en Dos BienesDavis Hugo Salinas OchoaNo ratings yet
- Estadistica 3Document10 pagesEstadistica 3Franyeli Delgado CalderónNo ratings yet
- Soluciones Cap 1 4Document24 pagesSoluciones Cap 1 4ANGELO MORALESNo ratings yet
- Estrés Académico - Cuadros y GráficosDocument10 pagesEstrés Académico - Cuadros y Gráficos20223409No ratings yet
- Problema 4-19 de ModelosDocument5 pagesProblema 4-19 de ModelosAlfonsoNo ratings yet
- Taller A Equipo 01 - Mayo 2021Document8 pagesTaller A Equipo 01 - Mayo 2021Carlos HormazábalNo ratings yet
- Clase-Regresión Linel, Curvilineal y Multiple 2013Document23 pagesClase-Regresión Linel, Curvilineal y Multiple 2013leonardoNo ratings yet
- Tir215 - Retroalimentación 1-1Document4 pagesTir215 - Retroalimentación 1-1Mantenimiento OccidenteNo ratings yet
- Reporte 4 - Estadística AvanzadaDocument13 pagesReporte 4 - Estadística AvanzadaHugo AlvaradoNo ratings yet
- Estadistica General Tarea 2 Aracelis SuarezDocument8 pagesEstadistica General Tarea 2 Aracelis SuarezAracelis SuarezNo ratings yet
- Presentación 1Document6 pagesPresentación 1guillermoNo ratings yet
- Encuesta Del Grado 6 01Document28 pagesEncuesta Del Grado 6 01YULEIDYS PEÑALOZANo ratings yet
- Actividad Práctica U2Document6 pagesActividad Práctica U2Adiel SosaNo ratings yet
- Investigacion de Operacion 2 TallerDocument10 pagesInvestigacion de Operacion 2 TallerNeftali RodriguezNo ratings yet
- Jueves 6 A 8Document11 pagesJueves 6 A 8Neftali RodriguezNo ratings yet
- Guía 1 ResueltaDocument25 pagesGuía 1 ResueltaSofí MontesNo ratings yet
- Ejercicio n1Document11 pagesEjercicio n1Josefina LafuenteNo ratings yet
- Diamante de La EconomíaDocument1 pageDiamante de La EconomíaNasly100% (1)
- Estadistica - 3Document5 pagesEstadistica - 3andrea mendezNo ratings yet
- Al Preguntar A 20 Familias Sobre El Número de Hijos Que TuvieronDocument3 pagesAl Preguntar A 20 Familias Sobre El Número de Hijos Que TuvieronNery Cresencia Caceres MolinaNo ratings yet
- PRACTICASSDocument3 pagesPRACTICASSalexanderNo ratings yet
- 04-TRANSFORMADOR MUNICIPIO DEL PTO EL CARMEN-LAM 5-SignedDocument1 page04-TRANSFORMADOR MUNICIPIO DEL PTO EL CARMEN-LAM 5-SignedJhinson CoyagoNo ratings yet
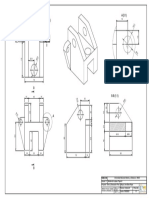
- Plano - Figura 8 - (1a1)Document1 pagePlano - Figura 8 - (1a1)Jhon Bairo RojasNo ratings yet
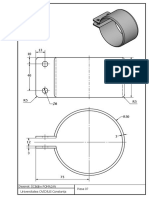
- P05 - Piese SimpleDocument6 pagesP05 - Piese SimpleEmricaNo ratings yet
- Tarea - U6 - Clase 28 - S8Document2 pagesTarea - U6 - Clase 28 - S8Stefy ばNo ratings yet
- Actividades de La Unidad IIIDocument6 pagesActividades de La Unidad IIIcarina vrnturaNo ratings yet
- Semana 13 - VideoconferenciaDocument54 pagesSemana 13 - VideoconferenciaJeremy RojasNo ratings yet
- Metodo de TrasporteDocument5 pagesMetodo de TrasporteDEYLIN YAMILETH ORELLANA SANTOSNo ratings yet
- Tallern6Document24 pagesTallern6Charles JlNo ratings yet
- Long CallDocument4 pagesLong CallLayla BedoyaNo ratings yet
- Distribución de Frecuencias EJEMPLODocument1 pageDistribución de Frecuencias EJEMPLOho melllamoyoNo ratings yet
- Jeisson Tabla FrecuenciasDocument5 pagesJeisson Tabla FrecuenciasAndres BreikNo ratings yet
- CAUBAUELINCOL12Document17 pagesCAUBAUELINCOL12Jhon Alarcon JaramilloNo ratings yet
- S13 Correlación ASUDocument53 pagesS13 Correlación ASUunicinoNo ratings yet
- Correlacion Pearson S13Document3 pagesCorrelacion Pearson S13Yuliana Diaz LozadaNo ratings yet
- Formato Seguimiento SupervisoresDocument1 pageFormato Seguimiento SupervisoresYalile FRANCO PAIPILLANo ratings yet
- Metodos Estadisticos Clase 4. Medidas Descriptivas - Tendencia Central (Media - Mediana)Document17 pagesMetodos Estadisticos Clase 4. Medidas Descriptivas - Tendencia Central (Media - Mediana)Santiago Chacon RiosNo ratings yet
- Sesión 11Document33 pagesSesión 11MitsukiNo ratings yet
- Higiene OC - Parte2 (1581)Document65 pagesHigiene OC - Parte2 (1581)Christian LorenzoNo ratings yet
- OutputDocument3 pagesOutputLucila Iparraguirre ToledoNo ratings yet
- Diagnostico 3Document4 pagesDiagnostico 3Fatima ArguelloNo ratings yet
- Analisis de MercadoDocument9 pagesAnalisis de MercadomunozllaucaangelyrosarioNo ratings yet
- Experimento de Franck-HertzDocument8 pagesExperimento de Franck-HertzjoaquinNo ratings yet
- CAMPO FORMATIVO - Exploracion y Conocimiento Del MundoDocument4 pagesCAMPO FORMATIVO - Exploracion y Conocimiento Del MundoGrecia Gonzalez GuzmanNo ratings yet
- 7comunidad. Jul. 17Document6 pages7comunidad. Jul. 17Luiis CarrizalesNo ratings yet
- Saber N°Document17 pagesSaber N°Adriana Cielo Valdez VargasNo ratings yet
- Árbol de DecisiónDocument7 pagesÁrbol de DecisiónTimohdez CruzNo ratings yet
- Examen Seminario FinalDocument6 pagesExamen Seminario Finalretamozoo724No ratings yet
- Tarea 3 - Grupo - 68 - Katherine Brigitte Colmenares GarciaDocument12 pagesTarea 3 - Grupo - 68 - Katherine Brigitte Colmenares GarciaRaul Andres CastañedaNo ratings yet
- Comunicación Masiva: Discurso Y... - BibliografíaDocument12 pagesComunicación Masiva: Discurso Y... - BibliografíaJesús Martín BarberoNo ratings yet
- Dossier Estilos de AP Gobierno Canarias Pag-5-19Document15 pagesDossier Estilos de AP Gobierno Canarias Pag-5-19MalenaNo ratings yet
- La Educación en America LatinaDocument9 pagesLa Educación en America Latinaaracelys piñateNo ratings yet
- Historia Clínica Psicológica 1Document21 pagesHistoria Clínica Psicológica 1IngridcitaVM100% (5)
- Hans KungDocument3 pagesHans KungLyss IbNo ratings yet
- Adrian Mauricio Lopez Barbosa - Actividad 1 Elaboracion de ProyectosDocument3 pagesAdrian Mauricio Lopez Barbosa - Actividad 1 Elaboracion de ProyectosAdrian Mauricio LopezNo ratings yet
- FactorajeDocument50 pagesFactorajeCorleoneVitoQuiaraNo ratings yet
- Lo Que Siento Por TiDocument29 pagesLo Que Siento Por Tiangie aymachoqueNo ratings yet
- Realismo JurídicoDocument3 pagesRealismo JurídicoKary CahuanticoNo ratings yet
- Escala de AsertividadDocument2 pagesEscala de AsertividadJuan Mauricio VergaraNo ratings yet
- Grupos y SubgruposDocument2 pagesGrupos y SubgruposDanielGaiardoNo ratings yet
- Programa de Capacitacion para Liideres Basado en PNLDocument6 pagesPrograma de Capacitacion para Liideres Basado en PNLAJGOMEZ3636No ratings yet
- DomínguezGuillén Tarea3Document24 pagesDomínguezGuillén Tarea3IlexNo ratings yet
- Carta A Mi Esposo 1Document2 pagesCarta A Mi Esposo 1Mayra MoralNo ratings yet
- Actividad Formativa 4Document3 pagesActividad Formativa 4Deborath Samanta Zavala LeonNo ratings yet
- Carta de QuejaDocument2 pagesCarta de QuejaBLANCA AURORA BLANCO NAJARNo ratings yet
- Estudiando Juntos - Mark FinleyDocument206 pagesEstudiando Juntos - Mark FinleyMarcos Jose Paico Ruiz83% (12)
- Formas Básicas de ComposiciónDocument22 pagesFormas Básicas de Composiciónmoira99100% (1)
- RV 4.1 NormativaDocument2 pagesRV 4.1 NormativaSergio 965No ratings yet
- Discurso PersuasivoDocument2 pagesDiscurso Persuasivoapi-436064674No ratings yet
- Teoría Del ColorDocument4 pagesTeoría Del ColorYorita HerreraNo ratings yet
- ExcelenciaDocument19 pagesExcelenciaanon-547042100% (2)
- Producto 2-Estudio de Caso Planeación de La InvestigaciónDocument2 pagesProducto 2-Estudio de Caso Planeación de La InvestigaciónJULIANA MARCELA GIRALDO ALFARONo ratings yet
- Folleto Exposicion La PosmodernidadDocument3 pagesFolleto Exposicion La PosmodernidadupelworopezaNo ratings yet