You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5784)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (890)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (72)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- FRP Pipe BrochureDocument8 pagesFRP Pipe BrochurecrisjhairNo ratings yet
- SY155WDocument4 pagesSY155WLutfi DstrNo ratings yet
- Pages From RCJ SpecificationsDocument1 pagePages From RCJ Specificationsarch ragabNo ratings yet
- LG Catalog107Document40 pagesLG Catalog107mehdi abdianNo ratings yet
- Technical Spec & BOQ Screw ConveyorDocument7 pagesTechnical Spec & BOQ Screw ConveyorjhsudhsdhwuNo ratings yet
- Weather and Aviation PDFDocument10 pagesWeather and Aviation PDFSergio GasparriNo ratings yet
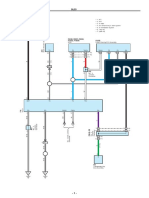
- DLC3 Yaris 2016Document3 pagesDLC3 Yaris 2016kurnia wanNo ratings yet
- KfloppyDocument17 pagesKfloppyBhanuNo ratings yet
- Hydrology Lecture01Document24 pagesHydrology Lecture01Mohd. YunusNo ratings yet
- Wire Rope and Material Properties GuideDocument100 pagesWire Rope and Material Properties GuideReynald de VeraNo ratings yet
- Fix Canon Pixma MP287 Printer Error CodesDocument7 pagesFix Canon Pixma MP287 Printer Error CodesBen BennyNo ratings yet
- UOP046-85 Wax Content in Petroleum OilsDocument6 pagesUOP046-85 Wax Content in Petroleum OilsZiauddeen Noor100% (1)
- Banner Printing Set UpDocument21 pagesBanner Printing Set UpAsanka ChandimaNo ratings yet
- Goldcut Manual PDFDocument28 pagesGoldcut Manual PDFRoxanna SabandoNo ratings yet
- Daftar Alat TSMDocument2 pagesDaftar Alat TSMagus ImawanNo ratings yet
- What is an electrostatic shieldDocument3 pagesWhat is an electrostatic shieldsujaraghupsNo ratings yet
- ASSAM - Uniform Zoning Regulation 2000Document35 pagesASSAM - Uniform Zoning Regulation 2000rajatesh1No ratings yet
- U2000 Oss NmsDocument27 pagesU2000 Oss Nmschandan100% (1)
- Propeller Pin Crack InspectionDocument4 pagesPropeller Pin Crack InspectionNicolás PiratovaNo ratings yet
- Bob L200Document12 pagesBob L200LucyPher_Comte_7563No ratings yet
- Process Capability AnalysisDocument37 pagesProcess Capability Analysisabishank09100% (1)
- Journallistofscopus PDFDocument630 pagesJournallistofscopus PDFSatyanarayana RentalaNo ratings yet
- Construction EstimateDocument42 pagesConstruction EstimateAngelica GicomNo ratings yet
- RDSO Guidelines - Bs 112 - Planning of Road Over BridgesDocument9 pagesRDSO Guidelines - Bs 112 - Planning of Road Over BridgesAnkur MundraNo ratings yet
- PDFDocument156 pagesPDFVasilescu Corina100% (1)
- Euro FirefighterDocument2 pagesEuro FirefighterGustavo VydraNo ratings yet
- Battery Room Ventilation GuidelinesDocument5 pagesBattery Room Ventilation GuidelinesARC Electrical Safety ConsultingNo ratings yet
- 2D Vs 3D ReviewDocument7 pages2D Vs 3D ReviewBhasker RamagiriNo ratings yet
- Sa2009-001608 en Rel670 CT Calculation ExampleDocument7 pagesSa2009-001608 en Rel670 CT Calculation ExampleinsanazizNo ratings yet
- LDM CuNi7Zn39Pb3Mn2 MSDSDocument4 pagesLDM CuNi7Zn39Pb3Mn2 MSDSmp87_ingNo ratings yet