You might also like
- High Performance Parallelism Pearls Volume Two: Multicore and Many-core Programming ApproachesFrom EverandHigh Performance Parallelism Pearls Volume Two: Multicore and Many-core Programming ApproachesNo ratings yet
- High Performance Parallelism Pearls Volume One: Multicore and Many-core Programming ApproachesFrom EverandHigh Performance Parallelism Pearls Volume One: Multicore and Many-core Programming ApproachesNo ratings yet
- High Performance Computer Architecture (CS60003)Document15 pagesHigh Performance Computer Architecture (CS60003)Sunil MishraNo ratings yet
- Performance PDFDocument109 pagesPerformance PDFRafa SoriaNo ratings yet
- Benchmarking SlidesDocument9 pagesBenchmarking Slidessarwan111291No ratings yet
- Measuring Experimental Error in Microprocessor SimulationDocument12 pagesMeasuring Experimental Error in Microprocessor SimulationblackspideymakNo ratings yet
- KSR Conf Paper 1Document8 pagesKSR Conf Paper 1dmctekNo ratings yet
- CIS775: Computer Architecture: Chapter 1: Fundamentals of Computer DesignDocument43 pagesCIS775: Computer Architecture: Chapter 1: Fundamentals of Computer DesignPranjal JainNo ratings yet
- S.P.E.C Cpu95Document6 pagesS.P.E.C Cpu95Nandagopal SivakumarNo ratings yet
- CO: The Chameleon 64-Bit Microprocessor Prototype: B. F. Sgs-ThomsonDocument6 pagesCO: The Chameleon 64-Bit Microprocessor Prototype: B. F. Sgs-ThomsonLekhank NandakumarNo ratings yet
- QSB ImpDocument22 pagesQSB ImpSudamBeheraNo ratings yet
- Powerxcell Instruction SetDocument9 pagesPowerxcell Instruction Setapi-12797690No ratings yet
- Compiler Technology For Future MicroprocessorsDocument52 pagesCompiler Technology For Future MicroprocessorsBiswajit DasNo ratings yet
- Numerical Simulation in Automotive Design: G. Lonsdale C&C Research Laboratories, NEC Europe LTD., St. Augustin, GermanyDocument7 pagesNumerical Simulation in Automotive Design: G. Lonsdale C&C Research Laboratories, NEC Europe LTD., St. Augustin, Germanybadboys123No ratings yet
- GS36J06D20 01eDocument6 pagesGS36J06D20 01eJuan Rodriguez ArevaloNo ratings yet
- The Design of A Low Power Asynchronous Multiplier: Yijun Liu, Steve FurberDocument6 pagesThe Design of A Low Power Asynchronous Multiplier: Yijun Liu, Steve FurberMishi AggNo ratings yet
- Opengl-Performance and Bottlenecks: S A, P K SDocument15 pagesOpengl-Performance and Bottlenecks: S A, P K SmartinsergNo ratings yet
- High Performance Computing in Power System Applications.: September 1996Document24 pagesHigh Performance Computing in Power System Applications.: September 1996Ahmed adelNo ratings yet
- High Performance Computing in Power System ApplicationsDocument23 pagesHigh Performance Computing in Power System ApplicationsDjalma FalcãoNo ratings yet
- High Computing Solution Resources - White Papers56 - en UsDocument7 pagesHigh Computing Solution Resources - White Papers56 - en UsAllen Prasad VargheseNo ratings yet
- Software ADocument35 pagesSoftware Amelkady2020No ratings yet
- Server Architectures Systems Performance and EstimationDocument25 pagesServer Architectures Systems Performance and EstimationYahiko PeinNo ratings yet
- Advanced Computer Architecture: 563 L02.1 Fall 2011Document57 pagesAdvanced Computer Architecture: 563 L02.1 Fall 2011bashar_engNo ratings yet
- Techniques For Benchmarking of CPU Micro-Architecture: College of Engineering, Pune - 5Document5 pagesTechniques For Benchmarking of CPU Micro-Architecture: College of Engineering, Pune - 5Varad DeshmukhNo ratings yet
- Compaq Professional Workstation XP1000 Benchmark Results: Performance BriefDocument21 pagesCompaq Professional Workstation XP1000 Benchmark Results: Performance BriefThalia Milanova Arias TellesNo ratings yet
- Remote Performance Monitoring (RPM)Document5 pagesRemote Performance Monitoring (RPM)nhanhruaNo ratings yet
- Attributes of The Performance of Ceutral Processing Units: A Relative Performauce Prediction ModelDocument10 pagesAttributes of The Performance of Ceutral Processing Units: A Relative Performauce Prediction ModelJuanJosé Solórzano CarrilloNo ratings yet
- Cover Note Signposting of The PortfolioDocument7 pagesCover Note Signposting of The PortfolioOur Beatiful Waziristan OfficialNo ratings yet
- BIT: A Very Compact Scheme System For MicrocontrollersDocument28 pagesBIT: A Very Compact Scheme System For Microcontrollerscarolina spinuNo ratings yet
- Chameleon ChipDocument21 pagesChameleon ChipbiswalsantoshNo ratings yet
- 0026 2714 (86) 90542 1Document1 page0026 2714 (86) 90542 1Jitendra PanthiNo ratings yet
- FFFDocument24 pagesFFFEngr Nayyer Nayyab MalikNo ratings yet
- 2º ExamDocument42 pages2º ExamSerg911100% (1)
- 1Document11 pages1aiadaiadNo ratings yet
- Application-Transparent Checkpoint/Restart For Mpi Programs Over InfinibandDocument8 pagesApplication-Transparent Checkpoint/Restart For Mpi Programs Over Infinibandalvawa27No ratings yet
- Full Solution Manual For Modern Processor Design by John Paul Shen and Mikko H. Lipasti PDFDocument18 pagesFull Solution Manual For Modern Processor Design by John Paul Shen and Mikko H. Lipasti PDFtargetiesNo ratings yet
- Updated Solution Manual For Modern Processor Design by John Paul Shen and Mikko H. LipastiDocument8 pagesUpdated Solution Manual For Modern Processor Design by John Paul Shen and Mikko H. LipastitargetiesNo ratings yet
- Full Solution Manual For Modern Processor Design by John Paul Shen and Mikko H. LipastiDocument27 pagesFull Solution Manual For Modern Processor Design by John Paul Shen and Mikko H. Lipastitargeties50% (2)
- Solution Manual For Modern Processor Design by John Paul Shen and Mikko H. LipastiDocument11 pagesSolution Manual For Modern Processor Design by John Paul Shen and Mikko H. LipastitargetiesNo ratings yet
- Submitted By: Shivendra Pal Singh 2009UIT971Document12 pagesSubmitted By: Shivendra Pal Singh 2009UIT971shivendra_xcvxcvxcvvxvcxvcvcbookNo ratings yet
- CIS775: Computer Architecture: Chapter 1: Fundamentals of Computer DesignDocument43 pagesCIS775: Computer Architecture: Chapter 1: Fundamentals of Computer DesignpadmaNo ratings yet
- ACA UNit 1Document29 pagesACA UNit 1mannanabdulsattarNo ratings yet
- ATEE 2004 Ilas 4.1Document6 pagesATEE 2004 Ilas 4.1electrotehnicaNo ratings yet
- Region-Based Techniques For Modeling and Enhancing Cluster Openmp PerformanceDocument22 pagesRegion-Based Techniques For Modeling and Enhancing Cluster Openmp PerformancedudeabcNo ratings yet
- An Overview of CommonDocument11 pagesAn Overview of CommonEman FawzyNo ratings yet
- WRL Research Report 89/7: Available Instruction-Level Parallelism For Superscalar and Superpipelined MachinesDocument35 pagesWRL Research Report 89/7: Available Instruction-Level Parallelism For Superscalar and Superpipelined MachinesSarah DeeranNo ratings yet
- The Performance and Energy Consumption of Three Embedded Real-Time Operating SystemsDocument8 pagesThe Performance and Energy Consumption of Three Embedded Real-Time Operating SystemssnathickNo ratings yet
- XCP ReferenceBook V1.0 ENDocument113 pagesXCP ReferenceBook V1.0 ENbriceagcosminNo ratings yet
- Advanced Computer ArchitectureDocument74 pagesAdvanced Computer ArchitectureMonica ChandrasekarNo ratings yet
- Tics On Embedded SystemsDocument5 pagesTics On Embedded SystemsDhiviyaSampathNo ratings yet
- MC&ES (18CSL48) Lab ManualDocument44 pagesMC&ES (18CSL48) Lab ManualMaxiteNo ratings yet
- HW Problems Chapter-1Document3 pagesHW Problems Chapter-1William DoveNo ratings yet
- Tnavigator Reservoir SimulationDocument12 pagesTnavigator Reservoir SimulationMuhammadMulyawanNo ratings yet
- Tnavigator EngDocument12 pagesTnavigator EngAlvaro Quinteros CabreraNo ratings yet
- Advanced Parallel ProcessingDocument32 pagesAdvanced Parallel ProcessingSpin FotonioNo ratings yet
- Radial Basis Function Neural NetworksDocument17 pagesRadial Basis Function Neural Networkso iNo ratings yet
- B4.4-0001-22-Oral - Mars Sample Return Campaign, The Science Opportunity and ChallengeDocument3 pagesB4.4-0001-22-Oral - Mars Sample Return Campaign, The Science Opportunity and ChallengeAnonymous Wu14iV9dqNo ratings yet
- 4063-Challenges of A Mars Sample Return MissionDocument2 pages4063-Challenges of A Mars Sample Return MissionAnonymous Wu14iV9dqNo ratings yet
- 706597main - ConwayErik-Dreaming of Mars Sample ReturnDocument44 pages706597main - ConwayErik-Dreaming of Mars Sample ReturnAnonymous Wu14iV9dqNo ratings yet
- 03-MSRUpdate-Gramling-PACNov2020 - MSR Presentation To The Planetary Advisory CommitteeDocument12 pages03-MSRUpdate-Gramling-PACNov2020 - MSR Presentation To The Planetary Advisory CommitteeAnonymous Wu14iV9dqNo ratings yet
- 2022.3.31 - MSR Overview - ASTR Presentation 2Document16 pages2022.3.31 - MSR Overview - ASTR Presentation 2Anonymous Wu14iV9dqNo ratings yet
- SvaDocument9 pagesSvaVijendra PalNo ratings yet
- Formal Verification Not Just For Control Paths - VH v13 I2Document7 pagesFormal Verification Not Just For Control Paths - VH v13 I2Anonymous Wu14iV9dqNo ratings yet
- Jagath C. Rajapakse, Andrzej Cichocki, and V. David Sanchez ADocument9 pagesJagath C. Rajapakse, Andrzej Cichocki, and V. David Sanchez AAnonymous Wu14iV9dqNo ratings yet
- Searching For A Solution To The Automatic RBF Network Design ProblemDocument24 pagesSearching For A Solution To The Automatic RBF Network Design ProblemAnonymous Wu14iV9dqNo ratings yet
- An Introduction To Database Systems 8th Edition C J Date PDFDocument1,034 pagesAn Introduction To Database Systems 8th Edition C J Date PDFAnonymous Wu14iV9dqNo ratings yet
- Perl TK TutorialDocument48 pagesPerl TK Tutorialsoumava05No ratings yet
- Insight Segmentation and Registration ToolkitDocument9 pagesInsight Segmentation and Registration ToolkitAnonymous Wu14iV9dqNo ratings yet
- Shellscriptingbook-Sample - Steves Bourne-Bash Scripting Tutorial PDFDocument16 pagesShellscriptingbook-Sample - Steves Bourne-Bash Scripting Tutorial PDFAnonymous Wu14iV9dqNo ratings yet
- IEEE DASC Standard Delay Format (SDF) PAR 1497 PDFDocument3 pagesIEEE DASC Standard Delay Format (SDF) PAR 1497 PDFAnonymous Wu14iV9dqNo ratings yet
- Generic Memory Compiler PDFDocument2 pagesGeneric Memory Compiler PDFAnonymous Wu14iV9dqNo ratings yet
- 2 Key Concepts: AssignmentsDocument18 pages2 Key Concepts: AssignmentsAnonymous Wu14iV9dqNo ratings yet
- Top 10 Tips For Efficient Perl Scripting For Chip Designers PDFDocument5 pagesTop 10 Tips For Efficient Perl Scripting For Chip Designers PDFAnonymous Wu14iV9dqNo ratings yet
- Verilog Books PDFDocument3 pagesVerilog Books PDFAnonymous Wu14iV9dqNo ratings yet
- 009 Attached-1 NAVFAC P-445 Construction Quality Management PDFDocument194 pages009 Attached-1 NAVFAC P-445 Construction Quality Management PDFSor sopanharithNo ratings yet
- " Suratgarh Super Thermal Power Station": Submitted ToDocument58 pages" Suratgarh Super Thermal Power Station": Submitted ToSahuManishNo ratings yet
- Description - GB - 98926286 - Hydro EN-Y 40-250-250 JS-ADL-U3-ADocument6 pagesDescription - GB - 98926286 - Hydro EN-Y 40-250-250 JS-ADL-U3-AgeorgeNo ratings yet
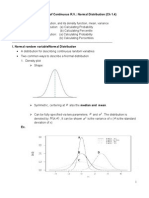
- Distribution of Continuous R.V.: Normal Distribution (CH 1.4) TopicsDocument7 pagesDistribution of Continuous R.V.: Normal Distribution (CH 1.4) TopicsPhạm Ngọc HòaNo ratings yet
- 96 Dec2018 NZGeoNews PDFDocument139 pages96 Dec2018 NZGeoNews PDFAditya PrasadNo ratings yet
- Cot Observation ToolDocument14 pagesCot Observation ToolArnoldBaladjayNo ratings yet
- Cryptography Lab DA-1Document19 pagesCryptography Lab DA-1Gautam Thothathri 19MIC0092No ratings yet
- Basics PDFDocument21 pagesBasics PDFSunil KumarNo ratings yet
- IMS - Integrated Management System Implementation Steps-Sterling - Rev00-240914 PDFDocument28 pagesIMS - Integrated Management System Implementation Steps-Sterling - Rev00-240914 PDFNorman AinomugishaNo ratings yet
- Max9924 Max9927Document23 pagesMax9924 Max9927someone elseNo ratings yet
- Jack Arch RetrofitDocument13 pagesJack Arch RetrofitDebendra Dev KhanalNo ratings yet
- Some Solutions To Enderton LogicDocument16 pagesSome Solutions To Enderton LogicJason100% (1)
- Basic Concept of ProbabilityDocument12 pagesBasic Concept of Probability8wc9sncvpwNo ratings yet
- Rewriting Snow White As A Powerful WomanDocument6 pagesRewriting Snow White As A Powerful WomanLaura RodriguezNo ratings yet
- Project BAGETS Wok Plan and Budget SIPDocument4 pagesProject BAGETS Wok Plan and Budget SIPMaia AlvarezNo ratings yet
- Read The Dialogue Below and Answer The Following QuestionDocument5 pagesRead The Dialogue Below and Answer The Following QuestionDavid GainesNo ratings yet
- Debate Lesson PlanDocument3 pagesDebate Lesson Planapi-280689729No ratings yet
- Sunrise - 12 AB-unlockedDocument81 pagesSunrise - 12 AB-unlockedMohamed Thanoon50% (2)
- Lecture Notes - Introduction To Big DataDocument8 pagesLecture Notes - Introduction To Big Datasakshi kureley0% (1)
- Nptel Online-Iit KanpurDocument1 pageNptel Online-Iit KanpurRihlesh ParlNo ratings yet
- Ugtt April May 2019 NewDocument48 pagesUgtt April May 2019 NewSuhas SNo ratings yet
- Chapter 3 PayrollDocument5 pagesChapter 3 PayrollPheng Tiosen100% (2)
- Nicole Rapp Resume 3Document2 pagesNicole Rapp Resume 3api-341337144No ratings yet
- Calculus of Finite Differences: Andreas KlappeneckerDocument30 pagesCalculus of Finite Differences: Andreas KlappeneckerSouvik RoyNo ratings yet
- History of JavaDocument3 pagesHistory of JavaKyra ParaisoNo ratings yet
- The Making of A Scientist Class 10Document2 pagesThe Making of A Scientist Class 10abhigna.ravikumarNo ratings yet
- Application of A HAZOP Study Method To Hazard Evaluation of Chemical Unit of The Power StationDocument8 pagesApplication of A HAZOP Study Method To Hazard Evaluation of Chemical Unit of The Power Stationshinta sariNo ratings yet
- Benchmark Leadership Philosphy Ead 501Document5 pagesBenchmark Leadership Philosphy Ead 501api-494301924No ratings yet
- Chapter 3: Verbal Communication SkillsDocument14 pagesChapter 3: Verbal Communication SkillsFares EL DeenNo ratings yet
- Projected Costs of Generating Electricity (EGC) 2005Document233 pagesProjected Costs of Generating Electricity (EGC) 2005susantojdNo ratings yet