You might also like
- Advertising and Sales PromotionDocument75 pagesAdvertising and Sales PromotionGuruKPO100% (3)
- ZeroAccess Rootkit Analysis PDFDocument9 pagesZeroAccess Rootkit Analysis PDFzositeNo ratings yet
- Embedded CoderDocument8 pagesEmbedded Coderجمال طيبيNo ratings yet
- Think Tank - Advertising & Sales PromotionDocument75 pagesThink Tank - Advertising & Sales PromotionGuruKPO67% (3)
- Applied ElectronicsDocument37 pagesApplied ElectronicsGuruKPO100% (2)
- Banking Services OperationsDocument134 pagesBanking Services OperationsGuruKPONo ratings yet
- Ross-Tech - VCDS Tour - Auto-ScanDocument5 pagesRoss-Tech - VCDS Tour - Auto-ScandreamelarnNo ratings yet
- Co NotesDocument144 pagesCo NotesSandeep KumarNo ratings yet
- Production and Material ManagementDocument50 pagesProduction and Material ManagementGuruKPONo ratings yet
- ch09 Morris ManoDocument15 pagesch09 Morris ManoYogita Negi RawatNo ratings yet
- Computer Graphics & Image ProcessingDocument117 pagesComputer Graphics & Image ProcessingGuruKPONo ratings yet
- AutoAccounting FAQ provides troubleshooting tipsDocument10 pagesAutoAccounting FAQ provides troubleshooting tipsFahd AizazNo ratings yet
- CS1601 Computer ArchitectureDocument389 pagesCS1601 Computer Architectureainugiri100% (1)
- Product and Brand ManagementDocument129 pagesProduct and Brand ManagementGuruKPONo ratings yet
- Biyani's Think Tank: Concept Based NotesDocument49 pagesBiyani's Think Tank: Concept Based NotesGuruKPO71% (7)
- Software Quality Assurance: Key Attributes and ActivitiesDocument28 pagesSoftware Quality Assurance: Key Attributes and Activitieskaosar alamNo ratings yet
- ECCouncil 312-50v9 Practice Test: One-Click CertificationDocument45 pagesECCouncil 312-50v9 Practice Test: One-Click Certificationzamanbd75% (4)
- Functional Verification 2003: Technology, Tools and MethodologyDocument5 pagesFunctional Verification 2003: Technology, Tools and MethodologydoomachaleyNo ratings yet
- Abstract AlgebraDocument111 pagesAbstract AlgebraGuruKPO100% (5)
- Introduction To JavaDocument26 pagesIntroduction To JavaMr. VipulNo ratings yet
- Advanced Operating SystemsDocument51 pagesAdvanced Operating SystemsaidaraNo ratings yet
- Service MarketingDocument60 pagesService MarketingGuruKPONo ratings yet
- Wrapper ClassesDocument17 pagesWrapper Classesadarsh raj100% (1)
- Data Communication & NetworkingDocument138 pagesData Communication & NetworkingGuruKPO75% (4)
- SDM Final AssignmentDocument47 pagesSDM Final AssignmentAbdullah Ali100% (4)
- Green Computing: Reducing Environmental Impact Through IT StrategiesDocument174 pagesGreen Computing: Reducing Environmental Impact Through IT Strategies19CS038 HARIPRASADRNo ratings yet
- Java Programming PDFDocument247 pagesJava Programming PDFBaponNo ratings yet
- Computer Programming PDFDocument260 pagesComputer Programming PDFSaad IlyasNo ratings yet
- Green ComputingDocument24 pagesGreen ComputingSunil Vicky VohraNo ratings yet
- Introduction To C ProgrammingDocument82 pagesIntroduction To C ProgrammingTAPAS KUMAR JANANo ratings yet
- What is Python? An SEO-Optimized GuideDocument11 pagesWhat is Python? An SEO-Optimized GuidemohitNo ratings yet
- Teaching Plan of Operating SystemDocument2 pagesTeaching Plan of Operating SystemGarrett MannNo ratings yet
- Vi RtSimDocument155 pagesVi RtSimjenishaNo ratings yet
- Computer Hardware & MaintenanceDocument4 pagesComputer Hardware & MaintenancemanishkalshettyNo ratings yet
- GE3151 - Python SyllabusDocument2 pagesGE3151 - Python Syllabussaro2330No ratings yet
- Lab Manual SPCCDocument62 pagesLab Manual SPCCenggeng7No ratings yet
- Software Engineering Question BankDocument71 pagesSoftware Engineering Question BankMAHENDRANo ratings yet
- C++ Functions Chapter SummaryDocument23 pagesC++ Functions Chapter SummaryGeethaa MohanNo ratings yet
- Project On Fantasy Cricket GameDocument6 pagesProject On Fantasy Cricket GameKINGS MAN HUNTER GAMING67% (3)
- 2D PRIMITIVESDocument173 pages2D PRIMITIVESArunsankar MuralitharanNo ratings yet
- Unit No 4 Slides FullDocument133 pagesUnit No 4 Slides Full18JE0254 CHIRAG JAINNo ratings yet
- Edge analytics core functions and componentsDocument13 pagesEdge analytics core functions and componentssarakeNo ratings yet
- Knapp's ClassificationDocument6 pagesKnapp's ClassificationSubi PapaNo ratings yet
- Embedded System R 2017 PDFDocument50 pagesEmbedded System R 2017 PDFSENTHILKUMAR RNo ratings yet
- Quotation Lab: Internet of Things (Iot) : Regulation: R16 Branch: Cse Yrae: B.Tech Iv Year I SemDocument3 pagesQuotation Lab: Internet of Things (Iot) : Regulation: R16 Branch: Cse Yrae: B.Tech Iv Year I Sembabu surendraNo ratings yet
- CS8074 Cyber Forensics: Anna University Exams April May 2022 - Regulation 2017Document2 pagesCS8074 Cyber Forensics: Anna University Exams April May 2022 - Regulation 2017TeCh 5No ratings yet
- Role of Internet and IntranetDocument10 pagesRole of Internet and IntranetsubhendujanaNo ratings yet
- Bcs 011 PDFDocument33 pagesBcs 011 PDFRahul RawatNo ratings yet
- Cloud Computing FundamentalsDocument31 pagesCloud Computing FundamentalsvizierNo ratings yet
- Emb Lab ManualDocument73 pagesEmb Lab ManualBharath RamanNo ratings yet
- Compiler DesignDocument2 pagesCompiler DesignDreamtech Press100% (1)
- Data Mining and Business Intelligence Lab ManualDocument52 pagesData Mining and Business Intelligence Lab ManualVinay JokareNo ratings yet
- Cocomo PDFDocument14 pagesCocomo PDFPriyanshi TiwariNo ratings yet
- Customer Billing System Report 2Document14 pagesCustomer Billing System Report 2rainu sikarwarNo ratings yet
- 3 - JVM As An Interpreter and EmulatorDocument34 pages3 - JVM As An Interpreter and EmulatorVedika VermaNo ratings yet
- LAB SESSSION 01 (AutoRecovered)Document12 pagesLAB SESSSION 01 (AutoRecovered)Bhavana100% (2)
- Cs 2032 Data Warehousing and Data Mining Question Bank by GopiDocument6 pagesCs 2032 Data Warehousing and Data Mining Question Bank by Gopiapi-292373744No ratings yet
- SOFTWARE AS EVOLUTIONARY ENTITY AnandDocument17 pagesSOFTWARE AS EVOLUTIONARY ENTITY AnandCherun ChesilNo ratings yet
- AJAX Patterns Web20Document15 pagesAJAX Patterns Web20Jith MohanNo ratings yet
- Department of Information Technology Faculty of Engineering and TechnologyDocument40 pagesDepartment of Information Technology Faculty of Engineering and TechnologyHarry CNo ratings yet
- Microprocessor Architecture and Instruction SetDocument185 pagesMicroprocessor Architecture and Instruction Setanishadanda50% (2)
- Tomasulo's Algorithm and ScoreboardingDocument17 pagesTomasulo's Algorithm and ScoreboardingParth KaleNo ratings yet
- sOFTWARE REUSEDocument48 pagessOFTWARE REUSENaresh KumarNo ratings yet
- Case Study Comparison of X85 and X86 AssemblersDocument6 pagesCase Study Comparison of X85 and X86 AssemblersRiteshNo ratings yet
- Arrays in C': Shashidhar G Koolagudi CSE, NITK, SurathkalDocument26 pagesArrays in C': Shashidhar G Koolagudi CSE, NITK, SurathkalKALYANE SATYAM SANJAYNo ratings yet
- Theory of ComputationDocument34 pagesTheory of ComputationSurya KameswariNo ratings yet
- Chapter - 3 TRANSACTION PROCESSINGDocument51 pagesChapter - 3 TRANSACTION PROCESSINGdawodNo ratings yet
- Python Lab Assignment ManualDocument62 pagesPython Lab Assignment ManualNihal ShettyNo ratings yet
- UntitledDocument125 pagesUntitledRIHAN PATHAN100% (1)
- Compiler Design Practical FileDocument49 pagesCompiler Design Practical FileDHRITI SALUJANo ratings yet
- SW Detailed Design PrinciplesDocument42 pagesSW Detailed Design PrinciplesSamuel LambrechtNo ratings yet
- Ecs-Unit IDocument29 pagesEcs-Unit Idavid satyaNo ratings yet
- Computer Organisation and Architectre NotesDocument353 pagesComputer Organisation and Architectre NotesvardhinNo ratings yet
- OOAD - Object Oriented Analysis and DesignDocument48 pagesOOAD - Object Oriented Analysis and DesignsharmilaNo ratings yet
- Real Time Operating System A Complete Guide - 2020 EditionFrom EverandReal Time Operating System A Complete Guide - 2020 EditionNo ratings yet
- Network Management System A Complete Guide - 2020 EditionFrom EverandNetwork Management System A Complete Guide - 2020 EditionRating: 5 out of 5 stars5/5 (1)
- Pipelining and Vector ProcessingDocument37 pagesPipelining and Vector ProcessingJohn DavidNo ratings yet
- OptimizationDocument96 pagesOptimizationGuruKPO67% (3)
- Applied ElectronicsDocument40 pagesApplied ElectronicsGuruKPO75% (4)
- Algorithms and Application ProgrammingDocument114 pagesAlgorithms and Application ProgrammingGuruKPONo ratings yet
- Algorithms and Application ProgrammingDocument114 pagesAlgorithms and Application ProgrammingGuruKPONo ratings yet
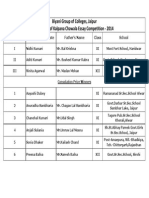
- Biyani Group of Colleges, Jaipur Merit List of Kalpana Chawala Essay Competition - 2014Document1 pageBiyani Group of Colleges, Jaipur Merit List of Kalpana Chawala Essay Competition - 2014GuruKPONo ratings yet
- Fundamental of Nursing Nov 2013Document1 pageFundamental of Nursing Nov 2013GuruKPONo ratings yet
- Phychology & Sociology Jan 2013Document1 pagePhychology & Sociology Jan 2013GuruKPONo ratings yet
- Paediatric Nursing Sep 2013 PDFDocument1 pagePaediatric Nursing Sep 2013 PDFGuruKPONo ratings yet
- Phychology & Sociology Jan 2013Document1 pagePhychology & Sociology Jan 2013GuruKPONo ratings yet
- Biological Science Paper I July 2013Document1 pageBiological Science Paper I July 2013GuruKPONo ratings yet
- Community Health Nursing I Nov 2013Document1 pageCommunity Health Nursing I Nov 2013GuruKPONo ratings yet
- Community Health Nursing Jan 2013Document1 pageCommunity Health Nursing Jan 2013GuruKPONo ratings yet
- Business Ethics and EthosDocument36 pagesBusiness Ethics and EthosGuruKPO100% (3)
- Community Health Nursing I July 2013Document1 pageCommunity Health Nursing I July 2013GuruKPONo ratings yet
- Biological Science Paper 1 Nov 2013Document1 pageBiological Science Paper 1 Nov 2013GuruKPONo ratings yet
- Business LawDocument112 pagesBusiness LawDewanFoysalHaqueNo ratings yet
- Biological Science Paper 1 Jan 2013Document1 pageBiological Science Paper 1 Jan 2013GuruKPONo ratings yet
- BA II English (Paper II)Document45 pagesBA II English (Paper II)GuruKPONo ratings yet
- Software Project ManagementDocument41 pagesSoftware Project ManagementGuruKPO100% (1)
- Moving Ocr or Voting Disk From One Diskgroup To AnotherDocument4 pagesMoving Ocr or Voting Disk From One Diskgroup To Anothermartin_seaNo ratings yet
- RasterDocument229 pagesRastermacielxflavioNo ratings yet
- Idrisi32 APIDocument38 pagesIdrisi32 APIYodeski Rodríguez AlvarezNo ratings yet
- Automatic Timetable GeneratorDocument4 pagesAutomatic Timetable GeneratorArohi LigdeNo ratings yet
- Pulse Monitor - CMPT 340Document4 pagesPulse Monitor - CMPT 340Gilbert MiaoNo ratings yet
- Week 1 QuizDocument2 pagesWeek 1 QuizKevin MulhernNo ratings yet
- Hitachi-HDS Technology UpdateDocument25 pagesHitachi-HDS Technology Updatekiennguyenh156No ratings yet
- The Likelihood Encoder For Source Coding: Paul Cuff and Eva C. Song - Princeton UniversityDocument2 pagesThe Likelihood Encoder For Source Coding: Paul Cuff and Eva C. Song - Princeton UniversityAyda EhsanyNo ratings yet
- TL-WR1043ND Print Server AppliDocument39 pagesTL-WR1043ND Print Server AppliJames FungNo ratings yet
- Huawei Interview QuestionsDocument5 pagesHuawei Interview QuestionsShashank NaikNo ratings yet
- EndevorDocument40 pagesEndevorAkash KumarNo ratings yet
- PuttyDocument146 pagesPuttypandishNo ratings yet
- Checkpoint 156-115.77 Practice Exam TitleDocument54 pagesCheckpoint 156-115.77 Practice Exam Titlegarytj21No ratings yet
- PK Sinha Distributed Operating System PDFDocument4 pagesPK Sinha Distributed Operating System PDFJivesh Garg0% (1)
- CS 464 Question BankDocument5 pagesCS 464 Question BankjomyNo ratings yet
- Ch. 1 Installing Ubuntu Server and FOG: The Simple Method! by Ian Carey (TN - Smashedbotatos)Document25 pagesCh. 1 Installing Ubuntu Server and FOG: The Simple Method! by Ian Carey (TN - Smashedbotatos)Karen ShawNo ratings yet
- Array Assignment No1Document4 pagesArray Assignment No1subashNo ratings yet
- Linked List Iterator and Node ClassDocument15 pagesLinked List Iterator and Node ClassRadenSue Raden Abd MuinNo ratings yet
- History of Multimedia SystemsDocument40 pagesHistory of Multimedia SystemsEng MakwebaNo ratings yet
- Technical QuestionsDocument59 pagesTechnical QuestionsVinen TomarNo ratings yet
- 1) A Class A Address HasDocument5 pages1) A Class A Address HaspatipawanNo ratings yet
- 8 Ways To Tweak and Configure Sudo On UbuntuDocument9 pages8 Ways To Tweak and Configure Sudo On UbuntuVictor Alexandru BusnitaNo ratings yet
- Laguna University: PrefaceDocument5 pagesLaguna University: PrefaceBeatsTubeTV FlowsNo ratings yet
- Python TwistedDocument247 pagesPython Twistedamit.213No ratings yet