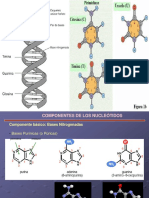
You might also like
- Ácidos NucleicosDocument4 pagesÁcidos NucleicosAlison RoaNo ratings yet
- Organizacion Del Material GeneticoDocument39 pagesOrganizacion Del Material GeneticoBelen Lorena Alvarez VargasNo ratings yet
- Semana 3 - Biología 2021 IIIDocument84 pagesSemana 3 - Biología 2021 IIIPablo CIclónNo ratings yet
- Genetica MicrobianaDocument83 pagesGenetica Microbianaguichay50% (2)
- NUCLEOTIDOSDocument25 pagesNUCLEOTIDOSLUIS ALBERTO MACHAIN GONZALEZNo ratings yet
- Acidos-Nucleicos PPT VeterinariaDocument18 pagesAcidos-Nucleicos PPT VeterinariaRoller VizcarraNo ratings yet
- Codigo Genetico - CentralDocument27 pagesCodigo Genetico - Centralmaria alejandra martinez sanabriaNo ratings yet
- Acidos Nucleicos Tumaco II Sem 23Document112 pagesAcidos Nucleicos Tumaco II Sem 23Laura RequeneNo ratings yet
- Acidos NucleicosDocument18 pagesAcidos NucleicosWilliams Reynaldo Arce DelgadoNo ratings yet
- ADN y ARNDocument43 pagesADN y ARNDAVILA GUEVARA MILTON ANDRENo ratings yet
- Unidad IV - Vi - A Pentosas - DBIO1037 - 28 Abril - 3 Mayo 2016Document34 pagesUnidad IV - Vi - A Pentosas - DBIO1037 - 28 Abril - 3 Mayo 2016Natalia Paz Solar MartinezNo ratings yet
- Tema 10 Acidos NucleicosDocument11 pagesTema 10 Acidos NucleicosAnahi ArandaNo ratings yet
- Biologia Molecular Dogma Central 2018Document58 pagesBiologia Molecular Dogma Central 2018Mercedes Cusi PinedaNo ratings yet
- Ac NucleicosDocument91 pagesAc NucleicosMaria BastiasNo ratings yet
- Sesion - Acidos NucleicosDocument28 pagesSesion - Acidos NucleicosMilena KRNo ratings yet
- Acid Os Nuclei Cos 3Document106 pagesAcid Os Nuclei Cos 3Ezequiel ValdiviaNo ratings yet
- 06 Acidos Nucleicos 2 Bach PDFDocument6 pages06 Acidos Nucleicos 2 Bach PDFNoelia ÁlvaroNo ratings yet
- Acidos NucleicosDocument19 pagesAcidos NucleicosVictor Villegas-CornelioNo ratings yet
- Diapositivas AziridinasDocument21 pagesDiapositivas AziridinasSebastian OchoaNo ratings yet
- Reduccion de Compuestos Nitrogenados PDFDocument23 pagesReduccion de Compuestos Nitrogenados PDFEli RoNo ratings yet
- Acidos NucleicosDocument45 pagesAcidos NucleicosJORDY50% (2)
- Los Ácidos NucleicosDocument4 pagesLos Ácidos NucleicosRaul Anccasi HurtadoNo ratings yet
- Adn y ArnDocument42 pagesAdn y ArnMiguel Encinas100% (2)
- PURINASDocument1 pagePURINASHermosita lilNo ratings yet
- Nucleotidos y Acidos NucleicosDocument60 pagesNucleotidos y Acidos NucleicosRe LatvNo ratings yet
- Ácidos NucleicosDocument61 pagesÁcidos Nucleicosmartapellicer07No ratings yet
- ReplicaciónDocument34 pagesReplicaciónElvisNo ratings yet
- TallerDocument3 pagesTallerAndres HoyosNo ratings yet
- Bioquimica - 07 15Document36 pagesBioquimica - 07 15Lorena LisbethNo ratings yet
- Metabolismo de AANNDocument58 pagesMetabolismo de AANNGiulianna GoicocheaNo ratings yet
- BBQ Doc t6 ApuntesWDocument7 pagesBBQ Doc t6 ApuntesWHugo de la FuenteNo ratings yet
- Sem 4Document19 pagesSem 4Nayely GVNo ratings yet
- Ácidos Nucleicos IDocument40 pagesÁcidos Nucleicos IFreddy Lucio Loza de la CruzNo ratings yet
- Clase 12 Sin AudioDocument42 pagesClase 12 Sin Audiomillaray.medinaNo ratings yet
- Ciclo de Krebs y LanzaderasDocument52 pagesCiclo de Krebs y Lanzaderasdocsamu78100% (1)
- Tema 6. Acidos NucleicosDocument31 pagesTema 6. Acidos NucleicosJavier Marquez HurtadoNo ratings yet
- NitracionDocument9 pagesNitracionmerida1234asdNo ratings yet
- AcidosDocument11 pagesAcidoszaidafdezlNo ratings yet
- 1.5 Nucleósidos y NucleótidosDocument40 pages1.5 Nucleósidos y NucleótidosKenneth CruzNo ratings yet
- Tabla LigandosDocument3 pagesTabla LigandosPaula VelandiaNo ratings yet
- Tabla LigandosDocument3 pagesTabla LigandosLau Urrego100% (1)
- Tabla Ligandos PDFDocument3 pagesTabla Ligandos PDFvaleriaNo ratings yet
- Tabla LigandosDocument3 pagesTabla LigandosLau UrregoNo ratings yet
- Ácidos nucleicos y código genéticoDocument6 pagesÁcidos nucleicos y código genéticoMaria PeredaNo ratings yet
- Adn Nucletidos 090530111549 Phpapp02Document3 pagesAdn Nucletidos 090530111549 Phpapp02Patricia Santos TossiNo ratings yet
- Respiracion CelularDocument35 pagesRespiracion Celularmario cartagenaNo ratings yet
- Acidos NucleicosDocument29 pagesAcidos Nucleicosvidalmarcosantonio07No ratings yet
- Cap.08 - Las Moleculas de La Herencia Acidos NucleicosDocument34 pagesCap.08 - Las Moleculas de La Herencia Acidos NucleicosJersiNaviaNo ratings yet
- Tipos de ReacciónDocument7 pagesTipos de Reacciónaranza moguelNo ratings yet
- UD2 Tema 3Document10 pagesUD2 Tema 3Josh Ndoky SantosNo ratings yet
- Tema 14 - Acidos Nucleicos PDFDocument30 pagesTema 14 - Acidos Nucleicos PDFKarenth Murillo ChoqueNo ratings yet
- 15-Acidos NucleicosColorDocument7 pages15-Acidos NucleicosColorXimena BacaNo ratings yet
- Heterociclos 2016-Pi ExcesivosDocument34 pagesHeterociclos 2016-Pi ExcesivosKatrina AgathaNo ratings yet
- Unidad SNA. Colinergicos y AnticolinergicosDocument80 pagesUnidad SNA. Colinergicos y AnticolinergicosAlejandra RuizNo ratings yet
- BIOENERGETICA NIVELA ON Line 2019Document9 pagesBIOENERGETICA NIVELA ON Line 2019Jessenia VásquezNo ratings yet
- 11 NucleotidosDocument46 pages11 NucleotidosDiego MorenoNo ratings yet
- Clase 3 y 4 SNA COLINERGICOS Y ANTICOLINERGICOSDocument80 pagesClase 3 y 4 SNA COLINERGICOS Y ANTICOLINERGICOSDafne AilynNo ratings yet
- Tema07 BIO-ÁCIDOS NUCLÉICOSDocument39 pagesTema07 BIO-ÁCIDOS NUCLÉICOSBorja GarcíaNo ratings yet
- Modulo 07Document34 pagesModulo 07Joel Fank Diaz Yopla100% (1)
- Sistemas de información financiera y contabilidadDocument8 pagesSistemas de información financiera y contabilidadFabiola Casapaico PultayNo ratings yet
- Cineplanet at Work 2019Document9 pagesCineplanet at Work 2019Joel Fank Diaz YoplaNo ratings yet
- Nuevo Hoja de Cálculo de Microsoft ExcelDocument1 pageNuevo Hoja de Cálculo de Microsoft ExcelJoel Fank Diaz YoplaNo ratings yet
- 02 Teorias Origen VidaDocument7 pages02 Teorias Origen VidaMaryuri RimapaNo ratings yet
- 1.5. Clasificacion de Los Seres VivosDocument17 pages1.5. Clasificacion de Los Seres Vivosprofesorhixem100% (1)
- HIDRUROSDocument21 pagesHIDRUROSJoel Fank Diaz YoplaNo ratings yet
- Trabajo Aplicativo - PJTDocument5 pagesTrabajo Aplicativo - PJTJoel Fank Diaz YoplaNo ratings yet
- Guía CNE SuministroDocument386 pagesGuía CNE SuministroLuis Angel Montilla TuestaNo ratings yet
- Nuevo Hoja de Cálculfgvdfvdfvadsfvfvadfo de Microsoft ExcelDocument1 pageNuevo Hoja de Cálculfgvdfvdfvadsfvfvadfo de Microsoft ExcelJoel Fank Diaz YoplaNo ratings yet
- Documentos Primaria Sesiones Matematica TercerGrado TERCER GRADO U1 MATE Sesion 03Document5 pagesDocumentos Primaria Sesiones Matematica TercerGrado TERCER GRADO U1 MATE Sesion 03lauraNo ratings yet
- 1.5. Clasificacion de Los Seres VivosDocument17 pages1.5. Clasificacion de Los Seres Vivosprofesorhixem100% (1)
- U2 4to Mat S7Document15 pagesU2 4to Mat S7WilycitoNo ratings yet
- 02 Teorias Origen VidaDocument7 pages02 Teorias Origen VidaMaryuri RimapaNo ratings yet
- 1.los ReinosDocument7 pages1.los ReinosharoldNo ratings yet
- 02 VectoresDocument28 pages02 VectoresKaro Kham AlkazhamNo ratings yet
- 02 P El Metodo CientificoDocument5 pages02 P El Metodo CientificoJoel Fank Diaz YoplaNo ratings yet
- 1.los ReinosDocument7 pages1.los ReinosharoldNo ratings yet
- Plan Anual de Trabajo Del Care 2017 PDFDocument12 pagesPlan Anual de Trabajo Del Care 2017 PDFRhay Valladares LunaNo ratings yet
- Articles-179304 Archivo PPT LicenciasDocument14 pagesArticles-179304 Archivo PPT Licenciasdaponte_2No ratings yet
- Articles-179304 Archivo PPT LicenciasDocument14 pagesArticles-179304 Archivo PPT Licenciasdaponte_2No ratings yet
- Articles-179304 Archivo PPT LicenciasDocument14 pagesArticles-179304 Archivo PPT Licenciasdaponte_2No ratings yet
- Acidos NuDocument31 pagesAcidos NuMax MorlaesNo ratings yet
- Articles-179304 Archivo PPT LicenciasDocument14 pagesArticles-179304 Archivo PPT Licenciasdaponte_2No ratings yet
- 02 VectoresDocument28 pages02 VectoresKaro Kham AlkazhamNo ratings yet
- 9 Tejido ConectivoDocument25 pages9 Tejido ConectivoJoel Fank Diaz Yopla100% (2)
- 9 Tejido ConectivoDocument25 pages9 Tejido ConectivoJoel Fank Diaz Yopla100% (2)
- 02pelmetodocientifico 180203030924Document6 pages02pelmetodocientifico 180203030924Joel Fank Diaz YoplaNo ratings yet
- 02 VectoresDocument28 pages02 VectoresKaro Kham AlkazhamNo ratings yet
- 02 VectoresDocument28 pages02 VectoresKaro Kham AlkazhamNo ratings yet
- El MiedoDocument21 pagesEl MiedoAbel LeguizamonNo ratings yet
- Biologia 8 Guia 2Document3 pagesBiologia 8 Guia 2René Nicolás LópezNo ratings yet
- Taller Grupal 1, GRUPO ODocument3 pagesTaller Grupal 1, GRUPO OJeidy SerranoNo ratings yet
- Actividad Celula II ABRIL 2020 UNIDAD IDocument14 pagesActividad Celula II ABRIL 2020 UNIDAD IKATIA VERONICA GUILLEN SANCHEZNo ratings yet
- Estructura Del ADN.Document1 pageEstructura Del ADN.Wendy Analy OchoaNo ratings yet
- Taller 2Document3 pagesTaller 2MarianaNo ratings yet
- Tema 5.3. ReplicacionDocument58 pagesTema 5.3. ReplicacionVanesa Algara SorianoNo ratings yet
- 7 Codigo GenéticoDocument7 pages7 Codigo GenéticoClinica Animal LifeNo ratings yet
- Enzimas clave en la replicación del ADNDocument2 pagesEnzimas clave en la replicación del ADNIván EsquivelNo ratings yet
- Cálculo del punto isoeléctrico de un péptido de 7 aminoácidosDocument2 pagesCálculo del punto isoeléctrico de un péptido de 7 aminoácidosIvan100% (1)
- Replicación, Transcripción, TraducciónDocument10 pagesReplicación, Transcripción, Traducciónyovar alva rodriguezNo ratings yet
- Plantilla - ADNDocument6 pagesPlantilla - ADNJon DiazNo ratings yet
- 1 Aminoacidos y ProteínasDocument17 pages1 Aminoacidos y ProteínasJessica ZamoraNo ratings yet
- Replicación Del AdnDocument3 pagesReplicación Del AdnhaydeeNo ratings yet
- Famaring EjerciciosDocument3 pagesFamaring EjerciciosCamila CanoNo ratings yet
- Practica #1 CSTI-1760-2327-Lab. BIO-112Document15 pagesPractica #1 CSTI-1760-2327-Lab. BIO-112Frandaly CabreraNo ratings yet
- As in CronicasDocument8 pagesAs in CronicasAdriana Lupe50% (2)
- Biología Presentación - 2 - Semana3Document24 pagesBiología Presentación - 2 - Semana3Tilki CP islandNo ratings yet
- Aminoácidos esenciales en rumiantes: su absorción y requerimientosDocument12 pagesAminoácidos esenciales en rumiantes: su absorción y requerimientosAlesu RodríguezNo ratings yet
- Biosintesis de Aminoacidos en Escherichia ColiDocument15 pagesBiosintesis de Aminoacidos en Escherichia ColiPilar HerreraNo ratings yet
- ADN FundamentosDocument28 pagesADN FundamentosLuis Sandoval EspirituNo ratings yet
- Replicacion Del AdnDocument13 pagesReplicacion Del AdnCindy RmrzNo ratings yet
- Etapas de la reacción en cadena de la polimerasa (PCRDocument2 pagesEtapas de la reacción en cadena de la polimerasa (PCRThamara CruzNo ratings yet
- Aminoácidos esenciales y su metabolismoDocument27 pagesAminoácidos esenciales y su metabolismoAndy AlarconNo ratings yet
- Phenex 1 y Phenex 2Document1 pagePhenex 1 y Phenex 2Camila Ramirez EspinozaNo ratings yet
- Genetica MolecularDocument5 pagesGenetica MolecularPepa RomeroNo ratings yet
- S12A Metabolismo de AminoacidosDocument10 pagesS12A Metabolismo de Aminoacidos000068711No ratings yet
- Cuadro Comparativo de ARN y ADNDocument2 pagesCuadro Comparativo de ARN y ADNDerlin ElianNo ratings yet
- Ejercicio Bio PythonDocument16 pagesEjercicio Bio PythonZareth HuamanNo ratings yet
- Expresión Genética para Cuarto Grado de SecundariaDocument6 pagesExpresión Genética para Cuarto Grado de Secundariacesar julcamoroNo ratings yet