You might also like
- Chi-Square Goodness of Fit TestDocument38 pagesChi-Square Goodness of Fit TestMadanish KannaNo ratings yet
- 101 Shortcuts in Math Anyone Can DoDocument95 pages101 Shortcuts in Math Anyone Can DoNaveed 205100% (3)
- EOQ Model for Inventory ManagementDocument32 pagesEOQ Model for Inventory ManagementFurikuri AziziNo ratings yet
- Frequency DNA and The Human BodypdfDocument6 pagesFrequency DNA and The Human BodypdfRegaldna Felix100% (1)
- Ed Thorp - A Mathematician On Wall Street - Statistical ArbitrageDocument33 pagesEd Thorp - A Mathematician On Wall Street - Statistical Arbitragenick ragoneNo ratings yet
- MGT613Document19 pagesMGT613Taimoor Sultan100% (3)
- Operations ResearchDocument2 pagesOperations ResearchGokul KrishNo ratings yet
- MGT 613 Final Term 13 PapersDocument141 pagesMGT 613 Final Term 13 PapersKamran HaiderNo ratings yet
- SPAM: Understanding Spammer Tactics and ToolsDocument57 pagesSPAM: Understanding Spammer Tactics and ToolsBindu Narayanan NampoothiriNo ratings yet
- Introduction To Operations ResearchDocument27 pagesIntroduction To Operations ResearchDivyendu Sahoo100% (2)
- Aggregate Planning PPTsDocument43 pagesAggregate Planning PPTsSwati Sucharita DasNo ratings yet
- Solving Facility Location Problems with Center of Gravity and P-Median ApproachesDocument30 pagesSolving Facility Location Problems with Center of Gravity and P-Median ApproachesAbhishek PadhyeNo ratings yet
- Operational Research: DR Anshuli Trivedi I ST Year P.G. NSCB Medical College JabalpurDocument21 pagesOperational Research: DR Anshuli Trivedi I ST Year P.G. NSCB Medical College Jabalpurdranshulitrivedi100% (1)
- Allen J.R.L.-physical Processes of Sedimentation-GEORGE ALLEN and UNWIN LTD (1980)Document128 pagesAllen J.R.L.-physical Processes of Sedimentation-GEORGE ALLEN and UNWIN LTD (1980)Dwiyana Yogasari100% (1)
- Operations Research: This Article May Require If You Can. The May Contain SuggestionsDocument6 pagesOperations Research: This Article May Require If You Can. The May Contain SuggestionsAshish KumarNo ratings yet
- Session 10-11 Transportation ProblemsDocument73 pagesSession 10-11 Transportation ProblemsSIRSHA PATTANAYAKNo ratings yet
- Maximising Profits for TBA AirlinesDocument46 pagesMaximising Profits for TBA Airlineslevy100% (1)
- Monte CarloDocument9 pagesMonte CarloqamhNo ratings yet
- Manager, Organization, and The TeamDocument40 pagesManager, Organization, and The TeamWajdiNo ratings yet
- Detailed Lesson Plan in Mathematics IV (Plane Figures)Document7 pagesDetailed Lesson Plan in Mathematics IV (Plane Figures)Mark Robel Torreña88% (56)
- Chapter 3, ND Vohra Book Linear Programming II:: Simplex MethodDocument38 pagesChapter 3, ND Vohra Book Linear Programming II:: Simplex MethodJazz KaurNo ratings yet
- AHP Lesson 1Document5 pagesAHP Lesson 1Konstantinos ParaskevopoulosNo ratings yet
- AHP Lesson 2Document12 pagesAHP Lesson 2Kanav NarangNo ratings yet
- CS583 ClusteringDocument40 pagesCS583 ClusteringruoibmtNo ratings yet
- Probset 3 KeyDocument7 pagesProbset 3 KeyhoneyschuNo ratings yet
- A Comparison Study On Methods For Measuring Distance in ImagesDocument5 pagesA Comparison Study On Methods For Measuring Distance in ImagesDr. R. BALUNo ratings yet
- CH 04 Sensitivity Vs Scenario AnalysisDocument2 pagesCH 04 Sensitivity Vs Scenario AnalysisUjjwal ShresthaNo ratings yet
- 12 - Chapter4 (DISTANCE MEASURES) PDFDocument18 pages12 - Chapter4 (DISTANCE MEASURES) PDFImran BashaNo ratings yet
- AHP TutorialDocument14 pagesAHP TutorialSree NivasNo ratings yet
- ClassificationDocument81 pagesClassificationAbhishek ShettigarNo ratings yet
- 613 Total Ass QuizDocument29 pages613 Total Ass QuizSyed Faisal BukhariNo ratings yet
- Monte Carlo Analysis: Arun Y. Patil Dept. of Mechanical EngineeringDocument54 pagesMonte Carlo Analysis: Arun Y. Patil Dept. of Mechanical EngineeringAmith S KaratkarNo ratings yet
- Ambo University Inistitute of Technology Department of Computer ScienceDocument13 pagesAmbo University Inistitute of Technology Department of Computer Sciencesifan MirkenaNo ratings yet
- Transshipment ProblemDocument4 pagesTransshipment ProblemGhani RizkyNo ratings yet
- RiskDocument26 pagesRiskVaibhav BanjanNo ratings yet
- Sta 3113 Revision QuestionsDocument7 pagesSta 3113 Revision Questionsvictor100% (1)
- Operation ResearchDocument25 pagesOperation Researchmahmoud khaterNo ratings yet
- Error AnalysisDocument10 pagesError Analysisapi-310102170No ratings yet
- Lecture 8: Risk Management: Software Development Project Management (CSC4125)Document51 pagesLecture 8: Risk Management: Software Development Project Management (CSC4125)rohanNo ratings yet
- Project Management in PracticeDocument27 pagesProject Management in PracticeHarold TaylorNo ratings yet
- Game Theory StrategiesDocument29 pagesGame Theory StrategiesVikas SharmaNo ratings yet
- MG 602 Probability Theories ExerciseDocument5 pagesMG 602 Probability Theories ExerciseEvelynNo ratings yet
- Human Resource Managment Chapter 6 QuizDocument2 pagesHuman Resource Managment Chapter 6 QuizluluNo ratings yet
- Operation ResearchDocument7 pagesOperation ResearchSohail AkhterNo ratings yet
- Transformations in Homogeneous Coordinates (Com S 477/577 NotesDocument10 pagesTransformations in Homogeneous Coordinates (Com S 477/577 NotesAaqib KhanNo ratings yet
- Importance of Similarity Measures in Effective Web Information RetrievalDocument5 pagesImportance of Similarity Measures in Effective Web Information RetrievalEditor IJRITCCNo ratings yet
- MB0032 Operations ResearchDocument38 pagesMB0032 Operations ResearchSaurabh MIshra12100% (1)
- PM Practice QuestionsDocument7 pagesPM Practice QuestionsAWNo ratings yet
- Markov 123Document108 pagesMarkov 123rafeshNo ratings yet
- Mid Term Problem 1 & 2-1-54877Document2 pagesMid Term Problem 1 & 2-1-54877Nehal NabilNo ratings yet
- P1.T2.Jorion 97 102 127 133 v1 PDFDocument5 pagesP1.T2.Jorion 97 102 127 133 v1 PDFHasan SadozyeNo ratings yet
- Stochastic Inventory Models: INOPER3 NotesDocument37 pagesStochastic Inventory Models: INOPER3 NotesAnorudo AguilarNo ratings yet
- Presentation Lecture 1 INDU 6111Document36 pagesPresentation Lecture 1 INDU 6111Vinoth RamaiahNo ratings yet
- EE 413: Operations Research & Quality Control: Chapter - 1Document26 pagesEE 413: Operations Research & Quality Control: Chapter - 1Daniel Nimabwaya100% (1)
- R5311304-Operations ResearchDocument4 pagesR5311304-Operations ResearchsivabharathamurthyNo ratings yet
- Operations Research - An IntroductionDocument14 pagesOperations Research - An IntroductionMahesh KumarNo ratings yet
- Operations Research NotesDocument73 pagesOperations Research NotesShivam kesarwani100% (1)
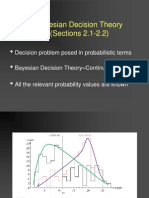
- Bayesian Decision Theory: CS479/679 Pattern Recognition Dr. George BebisDocument64 pagesBayesian Decision Theory: CS479/679 Pattern Recognition Dr. George Bebisএ.এস. সাকিবNo ratings yet
- Bayesian Decision TheoryDocument65 pagesBayesian Decision TheoryAnas TubailNo ratings yet
- Lecture 5Document16 pagesLecture 5Alireza MovahedianNo ratings yet
- Bayesian Decision Theory: Prof. Richard ZanibbiDocument47 pagesBayesian Decision Theory: Prof. Richard Zanibbishivani_himaniNo ratings yet
- Bayesian TheoryDocument66 pagesBayesian TheoryPaul WalkerNo ratings yet
- DHSCH 2Document88 pagesDHSCH 2obsidian555No ratings yet
- Pattern Classification PDFDocument39 pagesPattern Classification PDFandrey90No ratings yet
- Pattern ClassificationDocument39 pagesPattern ClassificationemanfatNo ratings yet
- Gunn DiodeDocument80 pagesGunn DiodeBindu Narayanan Nampoothiri100% (2)
- Cavity Resonator Field ExpressionsDocument10 pagesCavity Resonator Field ExpressionsBindu Narayanan NampoothiriNo ratings yet
- EC403: Microwave & Radar EngineeringDocument70 pagesEC403: Microwave & Radar EngineeringBindu Narayanan NampoothiriNo ratings yet
- 1935 Proc Indian Acad Sci-A V1 p179-188 PDFDocument13 pages1935 Proc Indian Acad Sci-A V1 p179-188 PDFBindu Narayanan NampoothiriNo ratings yet
- QuestionsDocument4 pagesQuestionsBindu Narayanan NampoothiriNo ratings yet
- P0307Document6 pagesP0307Bindu Narayanan NampoothiriNo ratings yet
- Classification Comparison of Red AlgaeDocument3 pagesClassification Comparison of Red AlgaeBindu Narayanan NampoothiriNo ratings yet
- John GumbelDocument18 pagesJohn GumbelJMF_CORD100% (1)
- Measure of Dispersion and LocationDocument51 pagesMeasure of Dispersion and LocationTokyo TokyoNo ratings yet
- Non Linear Data StructuresDocument50 pagesNon Linear Data Structuresnaaz_pinuNo ratings yet
- 2016 CodeUGM Usingn Code Design Life For Fatigue of WeldsDocument32 pages2016 CodeUGM Usingn Code Design Life For Fatigue of WeldsdddNo ratings yet
- CAPE Applied Mathematics Past Papers 2005P2B PDFDocument5 pagesCAPE Applied Mathematics Past Papers 2005P2B PDFEquitable BrownNo ratings yet
- SPY Trading Sheet - Monday, August 2, 2010Document2 pagesSPY Trading Sheet - Monday, August 2, 2010swinganddaytradingNo ratings yet
- Projectile MotionDocument11 pagesProjectile MotionRamachandran VenkateshNo ratings yet
- Study pointers in C with examplesDocument6 pagesStudy pointers in C with examplespremsagarNo ratings yet
- Chapter 5 - WEIGHT-VOLUME RELATIONSHIP PDFDocument44 pagesChapter 5 - WEIGHT-VOLUME RELATIONSHIP PDFKasturi Letchumanan100% (1)
- Business Math CBLM Com MathDocument54 pagesBusiness Math CBLM Com MathJoy CelestialNo ratings yet
- Quantitative Aptitude PDFDocument35 pagesQuantitative Aptitude PDFjeevithaNo ratings yet
- HARDER Developing The Formula 0.5 Ab SIN C For The Area of A TriangleDocument1 pageHARDER Developing The Formula 0.5 Ab SIN C For The Area of A TrianglejulucesNo ratings yet
- ES105 - Section I - Winter 2020 ExamDocument2 pagesES105 - Section I - Winter 2020 ExamAadil VahoraNo ratings yet
- DEB-HAR-21-2018-2019-337-PPR-BACHELOR of COMPUTER ApplicationDocument26 pagesDEB-HAR-21-2018-2019-337-PPR-BACHELOR of COMPUTER ApplicationAshok poddarNo ratings yet
- Mining Surveying Lecture Notes-II: Assoc - Prof.Dr. Nursu TunalıoğluDocument26 pagesMining Surveying Lecture Notes-II: Assoc - Prof.Dr. Nursu TunalıoğluEnes AslanNo ratings yet
- Unit-Iii Sequence and Series: 2 Marks QuestionsDocument18 pagesUnit-Iii Sequence and Series: 2 Marks QuestionsAshish Sharma0% (1)
- 1.5 - Solution Sets of Linear SystemsDocument4 pages1.5 - Solution Sets of Linear SystemsMuhammad YasirNo ratings yet
- CSY2006 Software Engineering 2 AssignmentDocument5 pagesCSY2006 Software Engineering 2 AssignmentantonioNo ratings yet
- Personalized Intelligent Hotel Recommendation System For Online ReservationDocument5 pagesPersonalized Intelligent Hotel Recommendation System For Online ReservationezekillNo ratings yet
- Met 2aDocument70 pagesMet 2aharshaNo ratings yet
- Model Building MethodologyDocument24 pagesModel Building MethodologymtlopezNo ratings yet
- Trainer: Class 2Document13 pagesTrainer: Class 2Kavita PatilNo ratings yet
- Unit 1 Practice QuestionsDocument5 pagesUnit 1 Practice QuestionsKristen JimenezNo ratings yet
- 2015-12-98 Math MagazineDocument76 pages2015-12-98 Math MagazineMETI MICHALOPOULOU100% (1)
- 2016 AAA HuDocument13 pages2016 AAA HuAnis SuissiNo ratings yet